






 文章介绍了QA-GNN,一种在问答任务中利用预训练语言模型和知识图谱进行联合推理的模型。它解决了从大规模知识图谱中识别相关信息和在上下文与结构之间进行细致推理的问题。通过相关性评分和联合图表示,QA-GNN在处理否定和实体替换等结构化推理上表现出优势。
文章介绍了QA-GNN,一种在问答任务中利用预训练语言模型和知识图谱进行联合推理的模型。它解决了从大规模知识图谱中识别相关信息和在上下文与结构之间进行细致推理的问题。通过相关性评分和联合图表示,QA-GNN在处理否定和实体替换等结构化推理上表现出优势。
论文链接:https://arxiv.org/abs/2104.06378
代码链接:https://github.com/michiyasunaga/qagnn
论文复现:论文复现:QA-GNN: Reasoning with Language Models and Knowledge Graphsfor Question Answering
参考文献:QA-GNN: Reasoning with Language Models and Knowledge Graphs for Question Answering
一、引言
给定QA环境(例如:问题和答案选择;图1紫色框),结合LM+KG进行推理有两点挑战:
(1)从一个大KG(绿色框)中识别信息知识;
(2)捕捉QA上下文和KG结构的细微差别,以对这两个信息来源进行联合推理。
以前的工作通过获取主题实体(在给定的QA上下文中提到的KG实体)和它们的少跳邻居来从KG检索子图。然而,这会引入许多与QA上下文在语义上不相关的实体节点,特别是当主题实体或跳跃的数量增加时。
此外,现有的LM+KG推理方法将QA上下文和KG视为两个独立的模式。他们分别将LMs应用于QA上下文,将图神经网络(GNN)应用于KG,并且不相互更新或统一它们的表示。这种分离可能会限制他们进行结构化推理的能力,例如,处理否定。
在这里,我们提出了QA-GNN,这是一个端到端的LM+KG问答模型,解决了上述两个挑战。我们首先用 LM 对问答上下文进行编码,同时用 MHGRN 检索 KG 子图。
MHGRN代表Multi-Head Graph Retrieval Network,是一种结合了多头注意力机制的图检索网络。在上下文中,MHGRN用于从知识图谱中检索子图,以便根据问题和答案上下文来获取相关实体和关系信息。通过多头机制,MHGRN能够并行地关注不同部分的知识图谱,提高了子图检索的效率和准确性。MHGRN的设计旨在有效地整合知识图谱的信息,并为QA-GNN模型提供必要的背景知识以辅助问题回答任务。
我们的QA-GNN有两个关键点:
(1)相关性评分:由于KG子图由主题实体的所有少跳邻居组成,因此对于给定的QA上下文,一些实体节点比其他实体节点更相关。因此,我们提出了KG节点相关性评分:我们通过将实体与QA上下文连接起来,并使用预训练的LM计算可能性,来对KG子图上的每个实体进行评分。这提供了一个关于KG的权重信息的一般框架。
(2)联合推理:我们设计了QA上下文和KG的联合图表示,其中我们显式地将QA上下文视为附加节点(QA上下文节点),并将其连接到KG子图中的主题实体,如图1所示。这个联合图,我们称之为工作图,将两个模态统一成一个图。然后,我们用相关分数增强每个节点的特征,并设计了一个新的基于注意力的GNN模块用于推理。
我们在工作图上的联合推理算法同时更新KG实体和QA上下文节点的表示,弥合了两个信息源之间的差距。
本文在常识领域使用的知识图谱是:Concept,用的数据集是:CommonsenseQA 和 OpenBookQA。
在医学领域使用的知识图谱是:UMLS 和 DrugBank,用的数据集是:MedQA-USMLE。
QA-GNN在某些形式的结构化推理(例如,正确处理问题中的否定和实体替换)上表现出更好的性能:在带有否定的问题上,它比经过微调的LM提高了4.6%;而现有的LM+KG模型比经过微调的LM提高了0.6%。
我们还表明:可以以一般KG子图的形式从QA-GNN中提取推理过程,而不仅仅是路径,这提出了一种解释模型预测的方法。
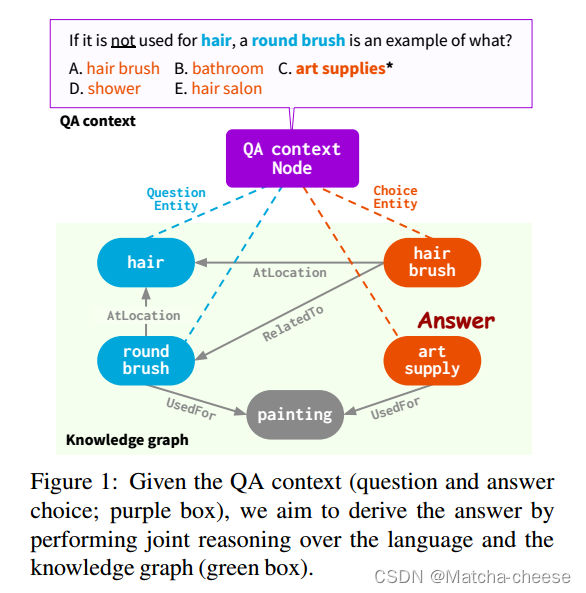
图1:给定QA环境(问题和答案选择;紫色框),我们的目标是通过对语言和知识图(绿色框)进行联合推理来得出答案。
二、方法
如图2所示,给定一个问题和一个答案选项a,我们将它们连接起来以获得QA上下文[q;a]。为了使用LM和KG的知识对给定的QA上下文进行推理,QA- gnn的工作方式如下:
(1)首先,我们使用LM获得QA上下文的表示,并从KG检索子图![]() 。然后我们引入一个表示QA上下文的QA上下文节点z,并将z连接到主题实体
。然后我们引入一个表示QA上下文的QA上下文节点z,并将z连接到主题实体![]() ,这样我们就有了两个知识来源的联合图,我们称之为工作图
,这样我们就有了两个知识来源的联合图,我们称之为工作图![]() 。
。
(2)为了自适应地捕捉QA上下文节点和Gw中每个其他节点之间的关系,我们使用LM计算各个知识图谱实体节点和问答上下文 z 的相关性分数,并将该分数用作每个节点的附加特征。
(3)然后,我们提出了一个基于注意力的GNN模块,该模块在GW上执行多轮消息传递。我们通过LM嵌入表示、QA上下文节点表示和池化工作图表示进行最终预测。
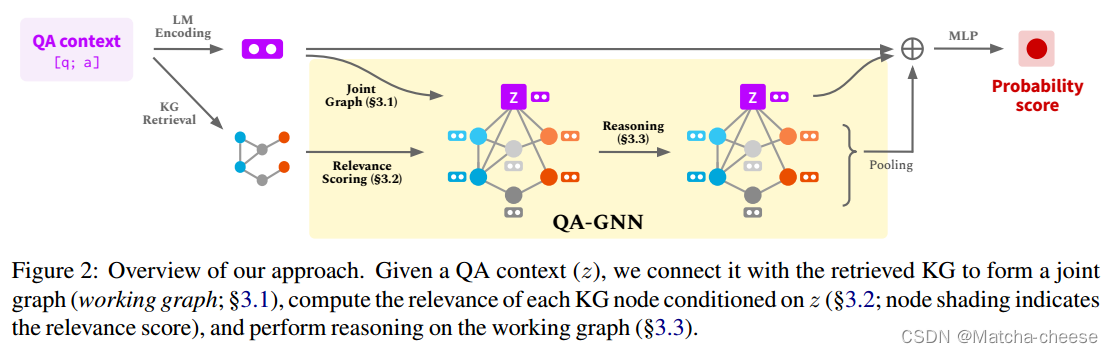
图2:概述我们的方法。给定一个QA上下文(z),我们将其与检索到的KG连接起来,形成一个联合图(工作图;§3.1),计算每个KG节点在z条件下的相关性(§3.2;节点阴影表示相关性评分),并在工作图上执行推理(第3.3节)。
2.1联合图表示
为了设计两个知识来源的联合推理空间,我们将它们显式地连接在一个公共图结构中。我们引入了一个新的QA上下文节点z来表示QA上下文,并使用两个新的关系类型![]() 和
和![]() 将z连接到KG子图
将z连接到KG子图![]() 上
上![]() 中的每个主题实体。这关系类型捕获QA上下文和KG中相关实体之间的关系,这取决于实体是在QA上下文的问题部分还是答案部分中找到的。
中的每个主题实体。这关系类型捕获QA上下文和KG中相关实体之间的关系,这取决于实体是在QA上下文的问题部分还是答案部分中找到的。
联合图表示:讲述working graph 是如何构建的。将问答上下文作为一个新节点z,与KG中的相应实体连起来,并设置了新的两种关系,该关系取决于实体是从哪里来的:问题实体和选中实体(候选答案实体)。用 LM 进行实体节点的初始化。
由于这个联合图直观地提供了QA上下文和KG上的推理空间(工作记忆),我们称其为工作图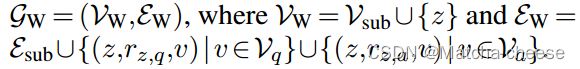
:问题实体(图1蓝色实体)
:答案实体(图1红色实体)
:使用Vq,a来表示出现在问题或答案选择中的所有实体,我们称之为主题实体。
:工作图 =(实体节点的集合,各节点的边的集合)
实体集 = 子图节点 + 节点z
边集 = 子图边 + {节点z,关系类型
,问题实体v}的各节点的边 + {节点z,关系类型
,答案实体v}的各节点的边
![]() 中的每个节点与四种类型中的一种相关联:
中的每个节点与四种类型中的一种相关联:![]()
每种类型分别表示:上下文节点z、Vq中的节点、Va中的节点、其他节点(对应图1和图2中的节点颜色:紫色、蓝色、红色、灰色)。我们将上下文节点z(QA上下文)和KG节点![]() (实体名称)的文本分别表示为text(z)和text(v)。
(实体名称)的文本分别表示为text(z)和text(v)。
我们通过QA上下文的LM表示初始化z的节点嵌入,并通过其实体嵌入初始化![]() 上的每个节点(§4.2)。在随后的部分中,我们将对工作图进行推理,为给定的(问题、答案选择)对打分。
上的每个节点(§4.2)。在随后的部分中,我们将对工作图进行推理,为给定的(问题、答案选择)对打分。
2.2KG节点相关性评分
如图3所示的示例,检索到的具有Vq,a的少跳邻居的KG子图Gsub可能包含对推理过程无信息的节点,例如节点“holiday”和“river bank”偏离主题;“人”和“地方”是通用的。当Vq,a很大时,这些不相关的节点可能会导致过拟合或在推理中引入不必要的困难。
考虑到许多子图中的实体节点与问答上下文之间没有关联,所以本文设置了节点相关性得分。我们使用LM 对每个KG节点在QA上下文条件下的相关性进行评分。对于每个节点v,我们将实体文本(v)与QA上下文文本(z)连接起来,并计算相关性分数:
![]()
其中fhead◦fenc表示LM计算的文本(v)的概率。此相关性评分ρv捕获每个KG节点相对于给定QA上下文的重要性,用于推理或修剪工作图。
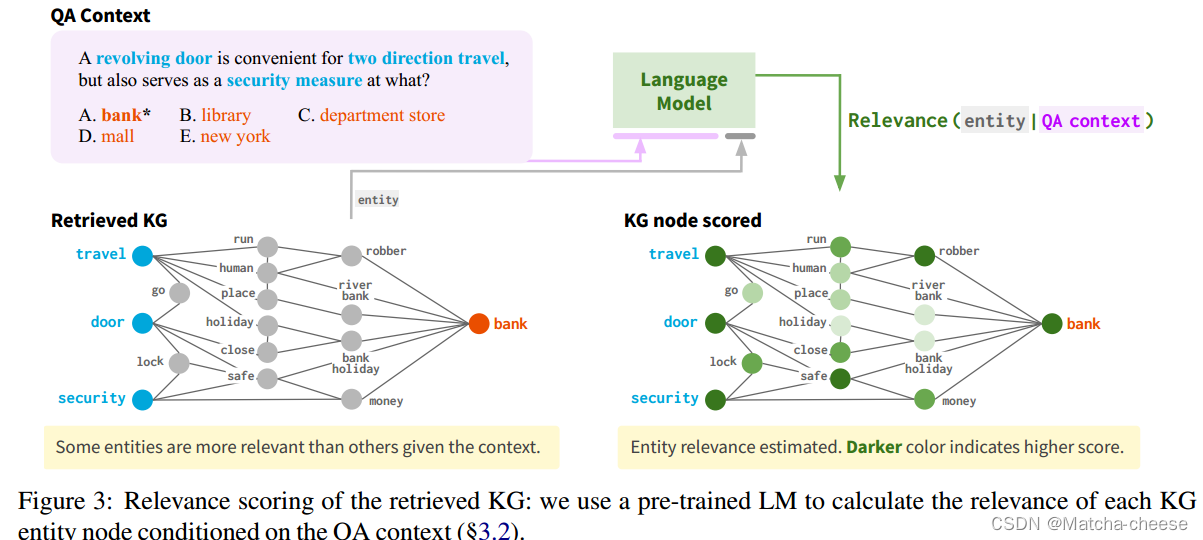
图3:检索到的KG的相关性评分:我们使用预训练的LM来计算每个KG实体节点在QA上下文条件下的相关性(§3.2)。
2.3GNN架构
为了在工作图GW上进行推理,我们的GNN模块建立在图注意框架(GAT)的基础上,该框架通过图上邻居之间的迭代消息传递来诱导节点表示。在每一层中,将每个节点的表示更新为如下表示。

将消息通过两层 MLP,并进行批处理化。
节点类型和关系感知消息:消息应该捕获关系和节点类型。其中关系和节点类型是 one-hot 向量。fu 是一个线性变换,fr 是一个双层 MLP。
![]()
消息如下,fm 是一个线性变换。
![]()
节点类型、关系和得分感知注意力:采用注意力捕获节点之间的关联,关联由节点类型、关系和节点相关性分数来决定。节点相关性分数计算如下,fp 是 MLP。

为了计算注意力权重,得到查询向量和关键字向量,fq 和 fk 是线性变换。最终得到注意力得分。


2.4推理与学习
给定问题和候选实体,候选实体是答案的概率由下式得出,其中 zGNN 是隐含得分的池化。用交叉熵损失函数进行优化。
![]()
2.5计算复杂度
我们分析了我们的模型的时间和空间复杂性,并与表1中的KagNet和MHGRN进行了比较。由于我们使用不同的边缘嵌入来处理不同关系类型的边,而不是像RGCN或MHGRN那样为每个关系设计一个独立的图网络,因此我们方法的时间复杂度相对于关系的数量是恒定的,相对于节点的数量是线性的。我们实现了与MHGRN相同的空间复杂度。

三、摘要
使用预训练语言模型(LMs)和知识图(KGs)中的知识回答问题的问题提出了两个挑战:
(1)给定QA上下文(问题和答案选择):
方法需要(i)从大型KGs中识别相关知识,以及(ii)在QA上下文
(2)KG上执行联合推理:
在这项工作中,我们提出了一个新的模型,QA-GNN,它通过两个关键的创新来解决上述挑战:
(i)相关性评分:我们使用LM来估计相对于给定QA上下文的KG节点的重要性。
(ii)联合推理:我们将QA上下文和KG连接起来形成一个联合图,并通过图神经网络相互更新它们的表示。
我们在常识(CommonsenseQA, OpenBookQA)和生物医学(MedQA-USMLE)领域的QA基准上评估我们的模型。QA-GNN优于现有的LM和LM+KG模型,并展示了执行可解释和结构化推理的能力,例如,正确处理问题中的否定。
四、实验
4.1数据集
(1)CommonsenseQA:是一个5道选择题,需要用常识性知识进行推理,包含12102个问题。CommonsenseQA的测试集是不公开的,模型预测只能通过官方排行榜每两周评估一次。因此,我们对Lin等人(2019)使用的内部(IH)数据分割进行了主要实验,并报告了我们最终系统在官方测试集上的分数。
(2)OpenBookQA:是一个4道选择题,需要用基础科学知识进行推理,包含5,957个问题。我们使用Mihaylov和Frank(2018)的官方数据分割。
(3)MedQA-USMLE:是一个要求生物医学和临床知识的4道选择题。这些问题最初来自美国医师执照考试(USMLE)的实践测试。该数据集包含12,723个问题。我们使用Jin等人(2021)的原始数据分割。
4.2知识图谱
对于CommonsenseQA和OpenBookQA,我们使用ConceptNet (Speer et al., 2017),一个通用领域知识图,作为我们的结构化知识来源。它总共有799,273个节点和2,487,810条边。节点嵌入使用Feng等人准备的实体嵌入进行初始化,该实体嵌入将预训练的lm应用于ConceptNet中的所有三元组,然后获得每个实体的池化表示.
对于MedQA-USMLE,我们使用了一个自构建的知识图,该知识图集成了统一医学语言系统(UMLS)的疾病数据库部分和DrugBank。知识图包含9958个节点和44561条边。节点嵌入使用来自SapBERT的实体名称的池表示进行初始化。
给定每个QA上下文(问题和答案选择),我们按照Feng等人(2020)中描述的预处理步骤从G中检索子图Gsub,跳数k= 2。然后,我们根据§3.2中计算的节点相关性评分对Gsub进行修剪,以保留前200个节点。因此,在本节(§4)中,我们使用术语“KG”来指代Gsub。
4.3训练参数
我们设置了我们的GNN模块的维数(D = 200)和层数(L = 5),每层的损失率为0.2。我们使用两个gpu (GeForce RTX 2080 Ti)使用RAdam优化器训练模型,耗时约20小时。我们设置批大小为{32,64,128,256},LM模块的学习率为{5e-6, 1e-5, 2e-5, 3e-5, 5e-5}, GNN模块的学习率为{2e-4, 5e-4, 1e-3, 2e-3}。上述超参数在开发集上进行调优。
4.4主要结果
表3和表5分别显示了CommonsenseQA和OpenBookQA上的结果。在这两个数据集上,我们观察到对微调LM和现有LM+KG模型的一致改进,例如,在CommonsenseQA上,比RoBERTa增加了4.7%,比先前最好的LM+KG系统MHGRN增加了2.3%。对MHGRN的提升表明,QA-GNN比现有的LM+KG方法更好地利用KG来执行联合推理。
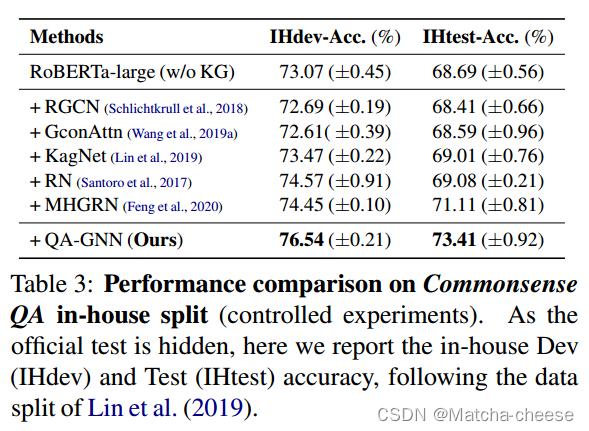
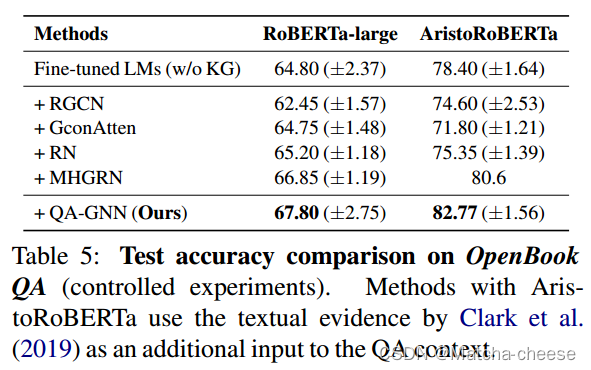
我们在官方排行榜上也取得了与其他系统竞争的成绩(表4和表6)。
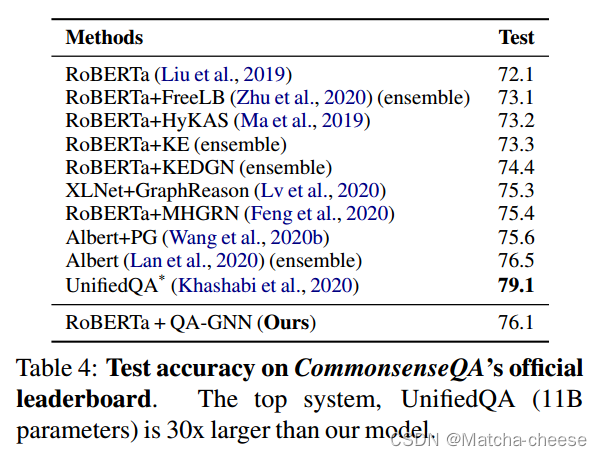
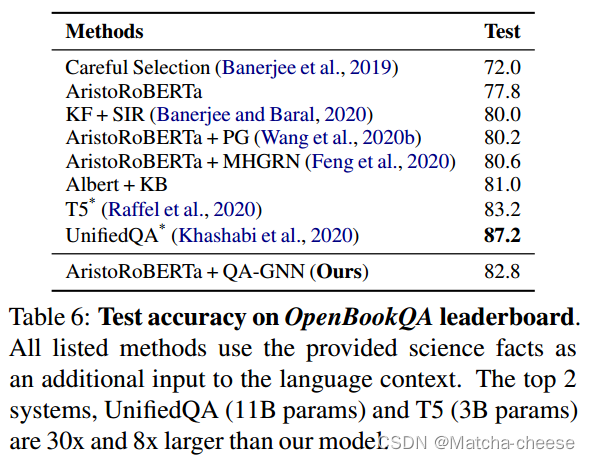
值得注意的是,前两个系统T5 (rafael等人,2020)和UnifiedQA (Khashabi等人,2020)使用更多的数据进行训练,并使用比我们的模型多8到30倍的参数(我们的模型有~ 360M个参数)。排除这些和集成系统,我们的模型在大小和数据量上与其他系统相当,并在这两个数据集上实现了最佳性能。
表7显示了MedQA-USMLE上的结果。QA-GNN优于最先进的微调lm(例如,SapBERT)。这一结果表明,我们的方法是跨不同领域(即除常识领域外的生物医学领域)对LMs和kg的有效增强。

4.5消融实验
表8总结了使用CommonsenseQA IHdev集对我们的每个模型组件(§3.1,§3.2,§3.3)进行的消融研究。

(1)图连接:
QA-GNN的第一个关键组件是连接z节点(QA上下文)到KG(§3.1)中的QA实体节点Vq,a的联合图。如果没有这些边,QA上下文和KG不能相互更新它们的表示,从而影响性能,这与之前的LM+KG系统MHGRN接近。如果我们将z连接到KG中的所有节点(而不仅仅是QA实体),则性能相当或略有下降(-0.16%)。
(2)KG节点相关性评分:
我们发现KG节点的相关性评分(§3.2)提供了一个提升:76.54%。我们还尝试为每个节点Vsub获取上下文嵌入wv,并添加节点特征:wv =fenc([text(z);文本(v)])。然而,我们发现它的表现并不好(76.31%),并且同时使用相关性分数和上下文嵌入与单独使用分数的表现相当,这表明分数在我们的任务中具有足够的信息;因此,我们的最终系统只使用相关性评分。
(3)GNN架构:
我们从GNN的注意力和消息计算中剔除了节点类型、关系和相关性评分的信息(§3.3)。结果表明,所有这些特征都提高了模型的性能。对于GNN层的数量,我们发现L = 5在开发集上效果最好。我们的直觉是,5层允许在QA上下文(z)和KG之间传递各种消息或推理模式。
4.6模型的可解释性
我们的目的是通过分析由GNN引起的节点到节点的注意权重来解释QA-GNN的推理过程。图4显示了两个示例。
在(a)中,我们对工作图执行最佳优先搜索(Best First Search, BFS),从QA上下文节点(Z;紫色)到问题实体节点(蓝色)到其他(灰色)或答案选择实体节点(橙色),这表明QA上下文z关注KG中的“电梯”和“地下室”,“电梯”和“地下室”都强烈关注“大楼”,“大楼”关注“办公楼”,这是我们的最终答案。
在(b)中,我们使用BFS从两个方向追踪注意力权重,它揭示了KG中不一定在QA上下文中提到的概念(“海”和“海洋”),但在问题实体(“螃蟹”)和答案选择实体(“盐水”)之间架起了一座推理桥梁。
而之前的KG推理模型(Lin et al, 2019;Feng et al, 2020)枚举KG中的单个路径用于模型解释,QA-GNN不是特定于路径,而是有助于找到更一般的推理结构(例如,示例(a)中具有多个锚节点的KG子图)。
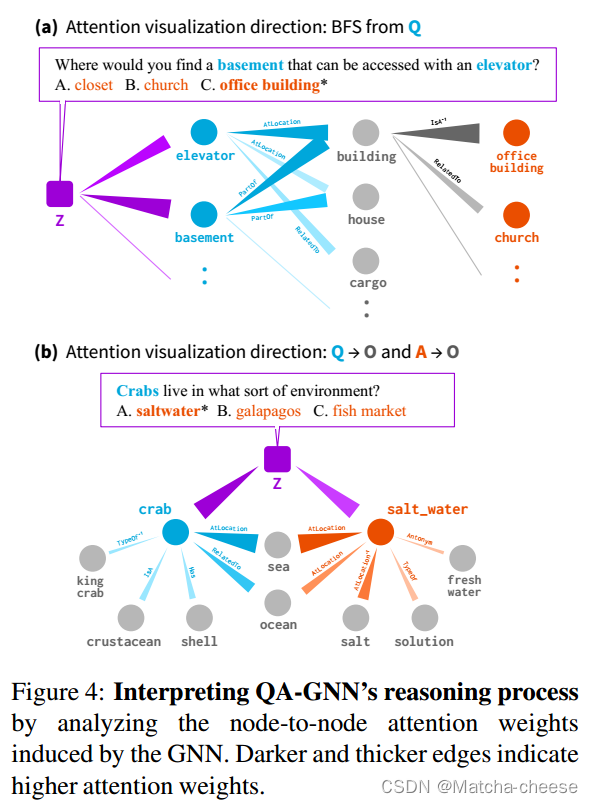
图4:通过分析GNN诱导的节点间注意权值来解释QA-GNN的推理过程。更暗和更粗的边缘表示更高的注意力权重。
4.7结构化的推理
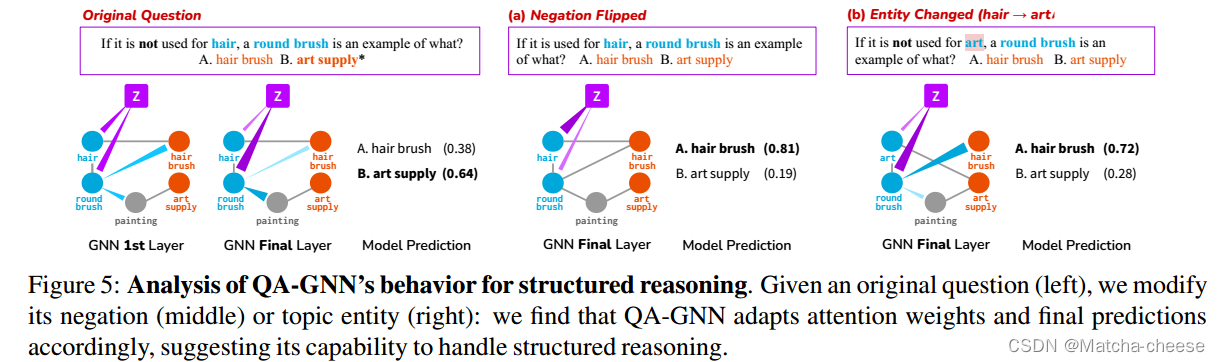
图5:结构化推理QA-GNN行为分析。给定一个原始问题(左),我们修改其否定(中)或主题实体(右):我们发现QA-GNN相应地调整注意力权重和最终预测,表明其处理结构化推理的能力。
图5显示了一个案例研究,用于分析我们的模型用于结构化推理的行为。左边的问题包含否定“不用于头发”,正确答案是“B:艺术用品”。我们观察到,在QA-GNN的第一层,从z到问题实体(“毛发”、“圆刷”)的注意力是分散的。在工作图上经过多轮消息传递后,z强烈关注GNN最后一层的“圆刷”,但对否定实体“毛发”的关注较弱。该模型正确地预测了答案“B:艺术用品”。
接下来,给定左边的原始问题,我们(a)删除否定或(b)修改主题实体(“艺术”)。
在(a)中,z现在强烈关注“毛发”,它不再被否定。该模型预测正确答案是“A:毛刷”。
在(b)中,我们观察到QA-GNN识别的结构与原始问题相同(只是交换了实体):z像之前一样弱地关注被否定的实体(“艺术”),并且模型正确地预测了“A”。
五、结论
我们提出了QA-GNN,这是一个利用LMs和kg的端到端问答模型。我们的主要创新包括(i)相关性评分,我们计算给定QA上下文条件下KG节点的相关性;(ii)联合在QA上下文和kg上进行推理,其中我们通过工作图连接两个信息源,并通过GNN消息传递共同更新它们的表示。通过定量和定性分析,我们展示了QA-GNN在问答任务上对现有LM和LM+KG模型的改进,以及其执行可解释和结构化推理的能力,例如正确处理问题中的否定。















 298
298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









