






论文链接:https://arxiv.org/abs/2104.06378
代码链接:https://github.com/michiyasunaga/qagnn
论文阅读:QA-GNN: Reasoning with Language Models and Knowledge Graphsfor Question Answering
一:环境配置
注意!【暖心小贴士】4060/4070/4080/4090/A40/A400显卡不适配CUDA11.3以下的cuda版本
conda create -n qagnn python=3.7
conda activate qagnn
pip install torch==1.8.0+cu111 -f https://download.pytorch.org/whl/torch_stable.html
pip install transformers==3.4.0
pip install nltk spacy==2.1.6
python -m spacy download en
# for torch-geometric
pip install torch-scatter==2.0.7 -f https://pytorch-geometric.com/whl/torch-1.8.0+cu111.html
pip install torch-sparse==0.6.9 -f https://pytorch-geometric.com/whl/torch-1.8.0+cu111.html
pip install torch-geometric==1.7.0 -f https://pytorch-geometric.com/whl/torch-1.8.0+cu111.html执行 python -m spacy download en 命令后报错:
requests.exceptions.ConnectionError: HTTPSConnectionPool(host='raw.githubusercontent.com', port=443): Max retries exceeded with url: /explosion/spacy-models/master/shortcuts-v2.json (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x7f55533dfd10>: Failed to establish a new connection: [Errno 111] Connection refused'))
解决办法:手动安装:【命名说明:sm/md/lg表示模型的大小(small, medium, large)】
1.去github下载模型,根据自己的spacy的版本下载对应的en版本
https://github.com/explosion/spacy-models/releases
这里给出en2.1.0下载链接
https://github.com/explosion/spacy-models/releases/tag/en_core_web_sm-2.1.0
2.下载en_core_web_sm-2.1.0.tar.gz

3.执行pip install .....tar.gz 命令安装
pip install /path/en_core_web_sm-2.1.0.tar.gz二、下载数据
(1)使用问答数据集(CommonsenseQA、OpenBookQA)和 ConceptNet 知识图谱。 下载所有原始数据
./download_raw_data.sh报错:
bash: ./download_raw_data.sh: 权限不够
解决办法:
更改权限:使用 chmod 命令更改脚本文件的权限,使其具有执行权限。在终端中运行以下命令
chmod +x download_raw_data.sh然后下载数据
./download_raw_data.sh成功!
 (2)通过运行预处理原始数据
(2)通过运行预处理原始数据
python preprocess.py -p <num_processes>报错:
[nltk_data] Error loading stopwords: <urlopen error [Errno 111]
[nltk_data] Connection refused>
解决办法 :
1.手动下载stopwords
https://www.nltk.org/nltk_data/
2.创建一个nltk_data文件夹,往下再创建一个corpora文件夹,最后把stopwords解压后的文件夹放在corpora文件夹下:D:\Python3.8\nltk_data\corpora(根据自己的报错路径对应去放)
然后运行脚本,又报另一个错误:
TypeError: Descriptors cannot not be created directly.
If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0.
If you cannot immediately regenerate your protos, some other possible workarounds are:
1. Downgrade the protobuf package to 3.20.x or lower.
2. Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower).
解决办法:
pip install protobuf==3.20然后运行脚本,又报错:
OSError: Can't load weights for 'roberta-large'. Make sure that:
- 'roberta-large' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'roberta-large' is the correct path to a directory containing a file named one of pytorch_model.bin, tf_model.h5, model.ckpt.
!没找到解决办法,我选择放弃自己预处理数据,直接去下载作者处理后的数据。
./download_preprocessed_data.sh遇到权限不够的问题,用上面的方法解决。然后就是漫长的下载过程......

下载完成

新闻(添加 MedQA-USMLE)除了带有 ConceptNet 知识图谱的常识性 QA 数据集(CommonsenseQA、OpenBookQA)外,我们还添加了一个生物医学 QA 数据集 (MedQA-USMLE),其中包含基于疾病数据库和 DrugBank 的生物医学知识图谱。您可以从 [此处] 下载所有数据。解压缩它并将medqa_usmle and ddb 文件夹放在data/目录中。虽然这些数据已经过预处理,但我们还提供了我们在utils_biomed/中使用的预处理脚本。
生成的文件结构将如下所示:
.
├── README.md
├── data/
├── cpnet/ (prerocessed ConceptNet)
├── csqa/
├── train_rand_split.jsonl
├── dev_rand_split.jsonl
├── test_rand_split_no_answers.jsonl
├── statement/ (converted statements)
├── grounded/ (grounded entities)
├── graphs/ (extracted subgraphs)
├── ...
├── obqa/
├── medqa_usmle/
└── ddb/三、训练QA-GNN
(1)对于 CommonsenseQA,请运行
./run_qagnn__csqa.sh遇到权限不够的问题,用上面的方法解决。
报错:
OSError: Can't load weights for 'roberta-large'. Make sure that:
- 'roberta-large' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'roberta-large' is the correct path to a directory containing a file named one of pytorch_model.bin, tf_model.h5, model.ckpt.
看样子这个错误逃不掉,必须要解决啊啊啊啊
解决办法:
1.去网站下载roberta-large,下载这3个到新建的文件夹roberta-large中
https://huggingface.co/FacebookAI/roberta-large/tree/main

2.将文件夹roberta-large放入项目目录中
然后运行,报错:
nvrtc compilation failed:
#define NAN __int_as_float(0x7fffffff)
#define POS_INFINITY __int_as_float(0x7f800000)
#define NEG_INFINITY __int_as_float(0xff800000)
主要原因可能是cuda跟显卡的兼容问题,所以要重新安装cuda+torch(要被气死了)
我重新安装torch1.10.0+cu113
https://download.pytorch.org/whl/torch_stable.html
因为我的pip install不知道抽什么风了,不能直接网络下载torch-scatter torch-sparse torch-geometric 所以我本地下载,链接放下面了。
pytorch-geometric.com/whl/torch-1.10.0+cu113.html
https://pypi.org/project/torch-geometric/2.0.4/
不同的torch+cu改一下链接就好
参考这个:torch-geometric、torch-sparse、torch-scatter、torch-cluster、 torch-spline-conv安装
配置好新环境后,继续运行。
报错:
RuntimeError: CUDA error: out of memory
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
内存不够....等晚上夜深人静了我再跑试试(人麻了已经)
跑通了。


四、评估QA-GNN
评估训练模型,对于 CommonsenseQA,请运行:
./eval_qagnn__csqa.sh报错:
FileNotFoundError: [Errno 2] No such file or directory: 'saved_models/csqa_model_hf3.4.0.pt'
看到有人说可以自己建一个:
FileNotFoundError: [Errno 2] No such file or directory: ‘models/trained_models/wind_model_NL_1h_CNN2
但是我新建一个后报错:
EOFError: Ran out of input
解决办法:不用管这个文件,在eval_qagnn__csqa.sh代码里直接改成自己训练模型生成的文件路径。
--load_model_path saved_models/csqa/enc-roberta-large__k5__gnndim200__bs64__seed0__20240407_091656/model.pt.14 \然后发现训练后生成的.txt,里面有每次迭代的模型评估(所以是不是不用再去执行评估命令了?)

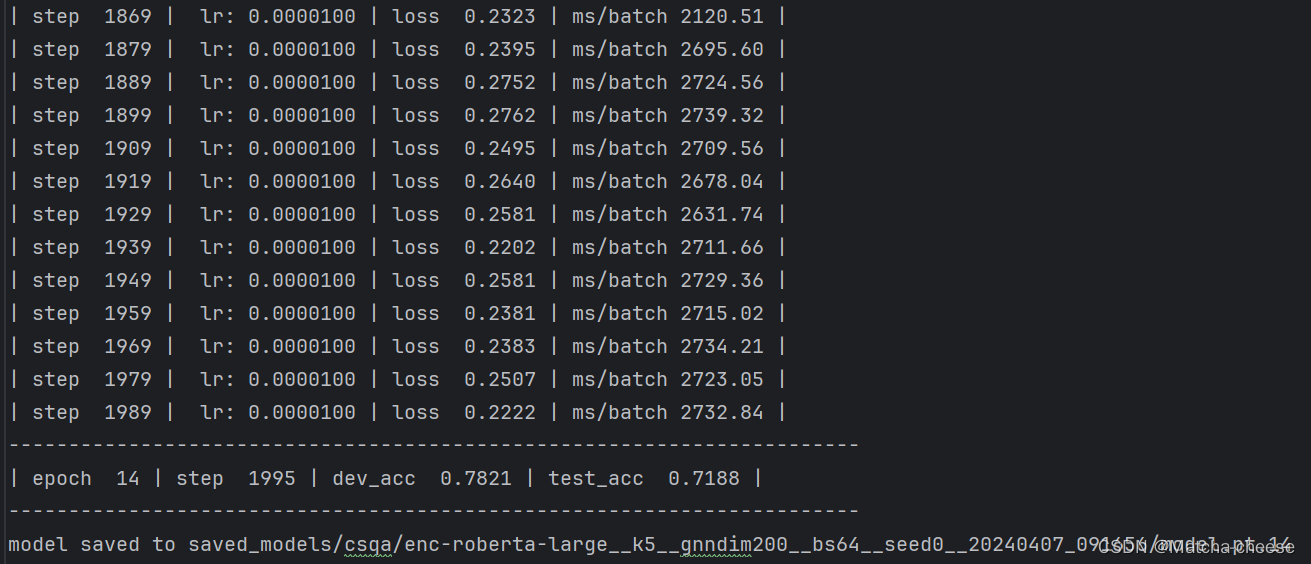
执行命令:
./eval_qagnn__csqa.sh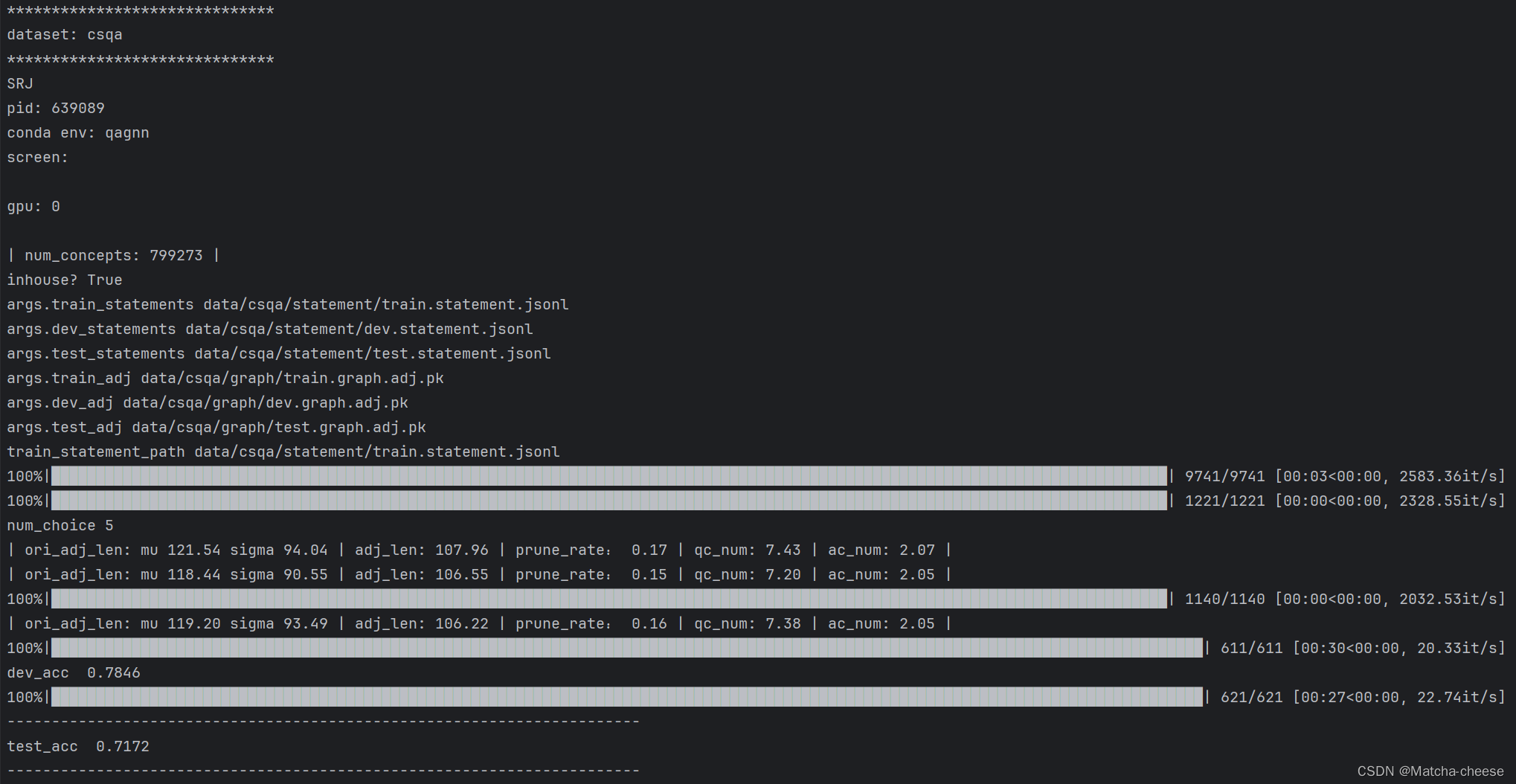
同理:
./run_qagnn__obqa.sh./eval_qagnn__obqa.sh注意:我们发现 OpenBookQA 的训练不稳定(例如,当使用不同的种子、不同版本的transformer/python库等时,最佳开发准确性会有所不同),这可能是因为数据集很小。我们建议尝试不同的种子。稳定训练的另一种潜在方法是使用下面提供的成功检查点之一初始化模型,例如通过添加参数。
--load_model_path obqa_model.pt

五、结果
(1)对于 CommonsenseQA

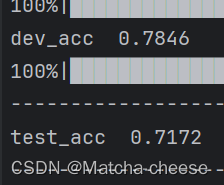
(2)对于OpenBookQA

















 2148
2148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









