







文章目录
前言
本文是论文《LLMAAA: Making Large Language Models as Active Annotators》的阅读笔记,仅供参考。
一、简介
在有一些演示和精心设计的提示下大型语言模型(LLM)在许多任务中都有显著表现。
然而,随着快速发展,在广泛的下游生产应用中采用LLM存在巨大的潜在风险。
其中一个主要问题是数据隐私和安全。在流行的“LMaaS” 设置,用户需要将他们自己的数据(可能包括敏感或私人信息)提供给第三方LLM供应商以访问服务,这增加了数据泄露的风险。此外,LLM通常通过对API的连续请求来消耗大量令牌,其中边际成本和延迟在大规模或实时应用中变得很大,阻碍了LLM在成本敏感场景中的实际部署。
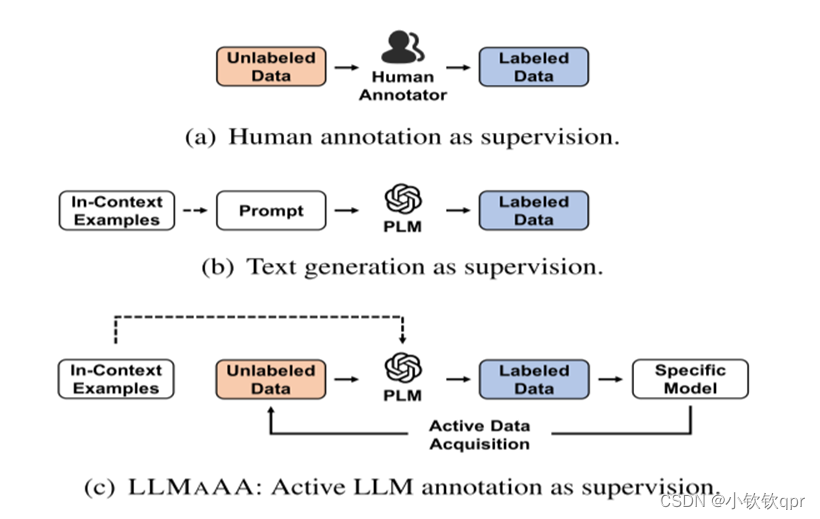
另一方面,训练NLP任务的特定任务模型(TAM)需要大量的标记数据。由于LLM较好的生成能力,一些研究人员试图将训练数据与文本生成合成,如下图。然而,生成的文本通常会遇到低质量的问题,并且可能会随着测试数据而表现出域偏移。为了利用丰富的未标记语料库,另一种选择是采用LLM作为注释器,其以零样本或少样本的方式生成标签。虽然这种方法看起来很有前途,但重要的是要承认LLM生成的标签不可避免地包含噪声,特别是当应用于具有挑战性的任务和特定领域的数据时。此外,更大的模型带来了更高的费用,在预算有限的情况下,降低注释成本也至关重要。
二、摘要
文中提出了LLMAAA,它将LLM作为注释器,并将它们放入一个主动学习循环中,以保证有效地注释。为了使用伪标签进行鲁棒学习,优化了注释和训练过程:(1)我们从一个小的演示池中提取k-NN样本作为上下文示例,(2)我们采用自动重新加权技术为训练样本分配可学习的权重。与以前的方法相比,LLMAAA具有效率和可靠性。文中对两个经典的自然语言处理任务,命名实体识别和关系提取进行了实验和分析。使用LLMAAA,从LLM生成的标签训练的特定于任务的模型可以在数百个带注释的示例中超越其老师LLM,这比其他基线更具成本效益。
三、框架
为了利用LLM很好的少样本性能和利用丰富的未标记数据,我们试图将LLM作为注释器并训练特定于任务的模型进行推理。一个理想的过程应该是:希望用最少的LLM生成的标签来鲁棒地学习TAM
具体地说,我们的解决方案是使LLM作为主动注释器。如图所示,LLMAAA包括三个关键组件:(1)生成给定数据的伪标签的利用提示工程优化的LLM注释器,(2)用于有效数据选择的主动获取机制,以及(3)自动重新加权技术,以确保对噪声标签的鲁棒学习。LLMAAA迭代这三个阶段以逐渐产生更强的TAM
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1578
1578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











