







🎈🎈🎈YOLO 系列教程 总目录
YOLOV1提出论文:You Only Look Once: Unified, Real-Time Object Detection
1、物体检测经典方法
- two-stage(两阶段):Faster-rcnn Mask-Rcnn系列
- one-stage(单阶段):YOLO系列
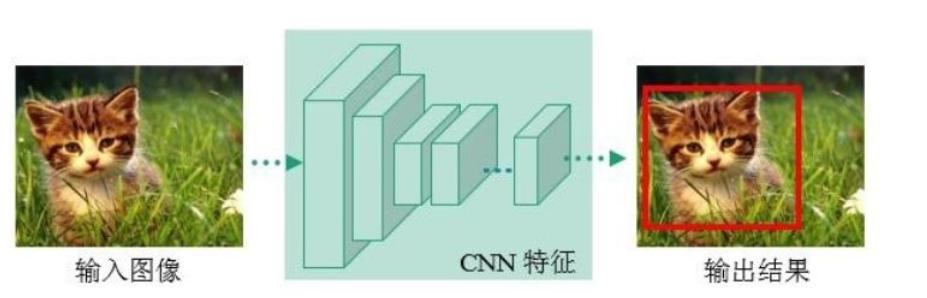
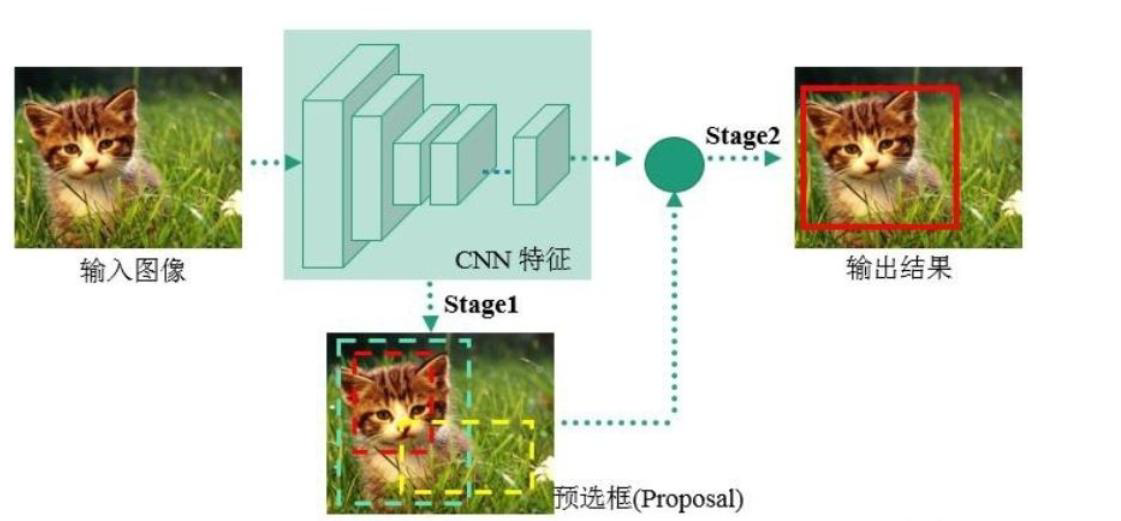
- 最核心的优势:速度非常快,适合做实时检测任务!
- 但是缺点也是有的,效果通常情况下不会太好!
2、机器学习分类任务评价指标
3、YOLOV1简介
- 经典的物体检测算法
- You Only Look Once,名字就已经说明了一切
- 把检测问题转化为回归问题,一个CNN就搞定了
- 可以对视频进行检测,应用领域非常广
只需要一个起始位置坐标,加上长和宽,即(x,y,w,h),就能把一个物体框出来了,这就是转化为回归问题

YOLO算法,在当时15、16年等了很久,因为Faster R-CNN精度高,但是太慢了,速度在当时比精度更重要
4、YOLOV1预测流程

- 把图像分词S*S个格子
- 遍历每个格子,如果哪一个物体的中心点落在了这个格子,那么这个格子就负责预测这个物体
- 得到了若干个格子,遍历每一个格子
- 根据当前的格子都生成两个候选框,找出一个接近的框
- 现在有了一个这个物体的位置,需要调整框的长宽来得到最终结果
- 在调整的过程中会得到很多个候选框,每个候选框都会得到一个confidence值(即置信度,这个置信度表示了当前框住的部分是否是一个我们需要检测的物体)
- 置信度低的框会被过滤掉(因为目标格子可能会有多个,但是不一定都符合)
总结:
首先输入就是一个S*S个格子,每一个格子都产生两个候选框,产生两个候选框进行微调,但是不是所有候选框都进行微调,需要切实有物体的,什么时候有物体,通过执行度来判断
5、整体网络架构
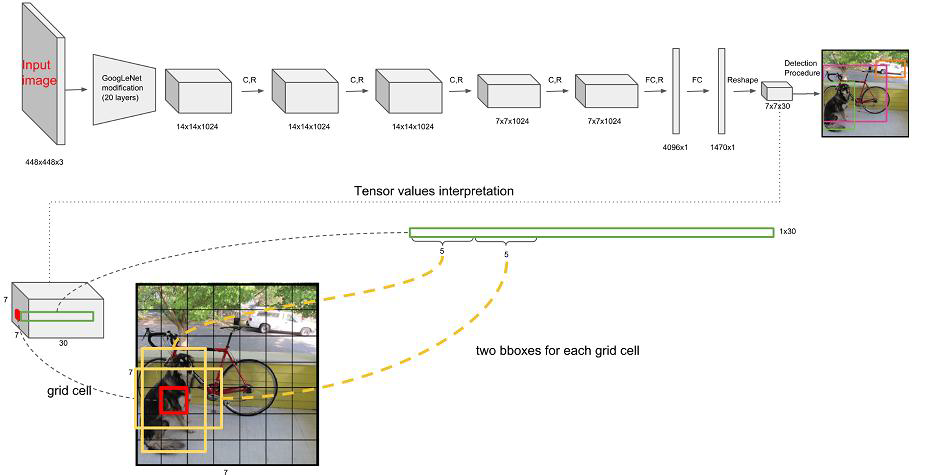
输入图像是一个448*448,是一个固定值(这个固定值并不意味着只能检测固定大小的东西,这个固定值是通过openCV的resize到固定值得到,里面的物体会进行缩放,最后的框会映射到一个完整的原始图像中),这个固定值也导致了一些问题,在v1版本中有一定的局限性
- 输入数据(448,448,3)
- 经过20层修改的GoogLeNet,得到(14,14,1024)
- 经过2次Conv+relu,得到(14,14,1024)
- 经过2次Conv+relu,得到(7,7,1024)
- 一次拉平操作+FC+relu,得到(4096,1)
- 一次全连接(1470,1)
- reshape(7,7,30)
- 生成检测
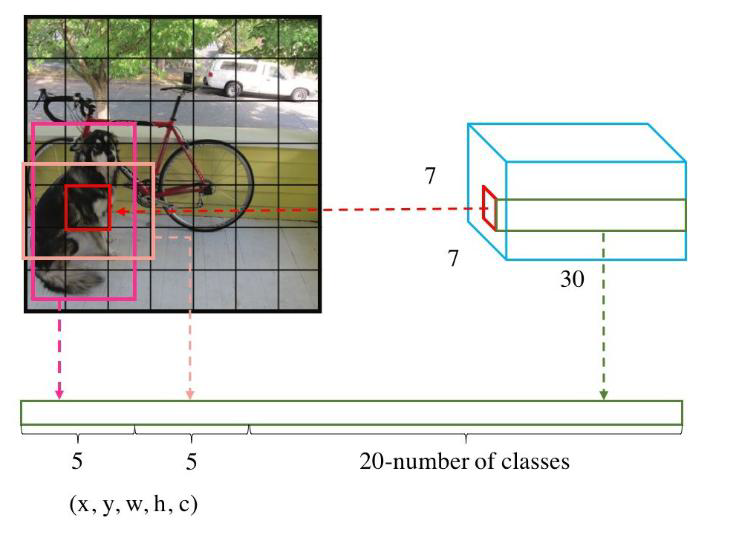
在网络的最后得到一个(7,7,30)的特征图,这个特征图表示的意义:77表示前面提到的SS个grid格子,在7*7的格子中,每一个格子都有30个值,每一个格子都要预测出30个值。
30个值的意义:
- 7*7个格子分别对应 B 1 B_1 B1、 B 2 B_2 B2两个框,比如 B 1 B_1 B1框,对应了4个值 ( x 1 , y 1 , w 1 , b 1 ) (x_1,y_1,w_1,b_1) (x1,y1,w1,b1)就可以表示成一个唯一的框,但是这里的 x 1 和 y 1 x_1和y_1 x1和y1不是一个具体的坐标值,是经过归一化后得到的一个在0到1之间的相对值
- 因此 B 2 B_2 B2框,也对应了4个值 ( x 2 , y 2 , w 2 , b 2 ) (x_2,y_2,w_2,b_2) (x2,y2,w2,b2)
- 此外每一个框,是不是有框住了物体呢?有一个置信度C值。
- 因此 B 1 B_1 B1框,对应5个值 ( x 1 , y 1 , w 1 , b 1 , C 1 ) (x_1,y_1,w_1,b_1,C_1) (x1,y1,w1,b1,C1), B 2 B_2 B2框,对应了5个值 ( x 2 , y 2 , w 2 , b 2 , C 2 ) (x_2,y_2,w_2,b_2,C_2) (x2,y2,w2,b2,C2)
- 在前面提到了一共有30个值,前10个对应了这10个值,后面的20个值,则是对应了20分类,也就是对应了20个类别的概率值。
了解了30个值的意义,就了解了(7,7,30),就基本懂了yolo-v1了
6、损失函数计算公式
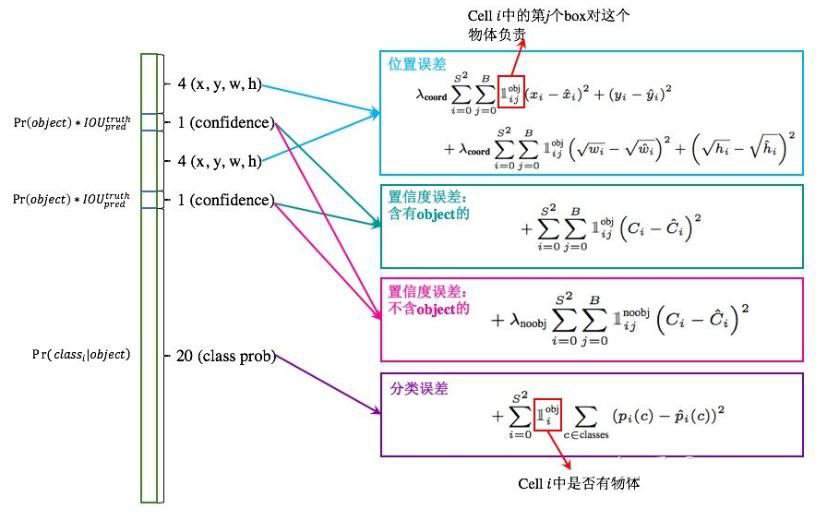
6.1 每个数字的意义
前面我们已经解释了每个数字的意义
- 10 = (X,Y,W,H,C)* 2
- 当前数据集有20个类别
- 7*7代表最终网格的大小
- SS(B*5+C)
6.2 坐标回归误差(中心点定位)
位置损失计算的是(X,Y,W,H)这4个值和真实值之间的误差
前面我们仔细解释了各项参数的含义,下面陆续给出整个损失计算公式,首先是位置损失,位置损失又包含两部分,分别是坐标和长宽,不是一个具体的坐标值,是经过归一化后得到的一个在0到1之间的相对值
λ
c
o
o
r
d
∑
i
=
0
S
2
∑
j
=
0
B
1
i
j
o
b
j
[
(
x
i
−
x
^
i
)
2
+
(
y
i
−
y
^
i
)
2
]
λ_{coord}\sum_{i=0}^{S^2}\sum_{j=0}^{B}1^{obj}_{ij}[(x_i-\hat{x}_i)^2+(y_i-\hat{y}_i)^2]
λcoordi=0∑S2j=0∑B1ijobj[(xi−x^i)2+(yi−y^i)2]
- λ c o o r d λ_{coord} λcoord=5:超参数,坐标损失的权重
- ∑ i = 0 S 2 \sum_{i=0}^{S^2} ∑i=0S2:遍历所有的grid cell格子
- ∑ j = 0 B \sum_{j=0}^{B} ∑j=0B:遍历所有的bounding box候选框
- 指示函数 1 i j o b j 1^{obj}_{ij} 1ijobj:挑选负责检测物体的bbox
- ( x i − x ^ i ) 2 + ( y i − y ^ i ) 2 (x_i-\hat{x}_i)^2+(y_i-\hat{y}_i)^2 (xi−x^i)2+(yi−y^i)2:中心点定位 预测值和 标签值 的差的平方和
6.3 坐标回归误差(长宽定位)
+ λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j [ ( w i − w ^ i ) 2 + ( h i − h ^ i ) 2 ] +λ_{coord}\sum_{i=0}^{S^2}\sum_{j=0}^{B}1^{obj}_{ij}[(\sqrt{w_i}-\sqrt{\hat{w}_i})^2+(\sqrt{h_i}-\sqrt{\hat{h}_i})^2] +λcoordi=0∑S2j=0∑B1ijobj[(wi−w^i)2+(hi−h^i)2]
- λ c o o r d λ_{coord} λcoord=5:超参数,坐标损失的权重
- ∑ i = 0 S 2 \sum_{i=0}^{S^2} ∑i=0S2:遍历所有的grid cell格子
- ∑ j = 0 B \sum_{j=0}^{B} ∑j=0B:遍历所有的bounding box候选框
- 指示函数 1 i j o b j 1^{obj}_{ij} 1ijobj:挑选负责检测物体的bbox
- ( w i − w ^ i ) 2 + ( h i − h ^ i ) 2 (\sqrt{w_i}-\sqrt{\hat{w}_i})^2+(\sqrt{h_i}-\sqrt{\hat{h}_i})^2 (wi−w^i)2+(hi−h^i)2 :宽高定位 预测值和标签值 算术平方根的差的平方和
求根号能使小框对误差更敏感
6.4 置信度回归误差(含有object)
主要是判断当前预测的是前景还是背景,含有object物体即为前景
∑
i
=
0
S
2
∑
j
=
0
B
1
i
j
o
b
j
(
C
i
−
C
^
i
)
2
\sum_{i=0}^{S^2}\sum_{j=0}^{B}1^{obj}_{ij}(C_i-\hat{C}_i)^2
i=0∑S2j=0∑B1ijobj(Ci−C^i)2
- ∑ i = 0 S 2 \sum_{i=0}^{S^2} ∑i=0S2:遍历所有的grid cell格子
- ∑ j = 0 B \sum_{j=0}^{B} ∑j=0B:遍历所有的bounding box候选框
- 指示函数 1 i j o b j 1^{obj}_{ij} 1ijobj:挑选负责检测物体的bbox
- ( C i − C ^ i ) 2 : (C_i-\hat{C}_i)^2: (Ci−C^i)2: 预测值和标签值差的平方和
- C i C_i Ci :从模型正向推断结果为SS(B*5+C)维向量找到这个bbox的confidence score
- C ^ i \hat{C}_i C^i :计算这个bbox与ground truth的IOU
6.5 置信度回归误差(不含有object)
λ n o o b j ∑ i = 0 S 2 ∑ j = 0 B 1 i j n o o b j ( C i − C ^ i ) 2 λ_{noobj}\sum_{i=0}^{S^2}\sum_{j=0}^{B}1^{noobj}_{ij}(C_i-\hat{C}_i)^2 λnoobji=0∑S2j=0∑B1ijnoobj(Ci−C^i)2
- λ n o o b j = 0.5 λ_{noobj}=0.5 λnoobj=0.5:超参数,非目标置信度损失的权重
- ∑ i = 0 S 2 \sum_{i=0}^{S^2} ∑i=0S2:遍历所有的grid cell格子
- ∑ j = 0 B \sum_{j=0}^{B} ∑j=0B:遍历所有的bounding box候选框
- 指示函数 1 i j n o o b j 1^{noobj}_{ij} 1ijnoobj:挑选不负责检测物体的bbox
- ( C i − C ^ i ) 2 (C_i-\hat{C}_i)^2 (Ci−C^i)2 :预测值和标签值差的平方和
6.6 分类误差
∑ i = 0 S 2 1 i o b j ∑ C ∈ c l a s s e s ( p i ( C ) − p ^ i ( c ) ) 2 \sum_{i=0}^{S^2}1^{obj}_{i}\sum_{C∈classes}(p_i(C)-\hat{p}_i(c))^2 i=0∑S21iobjC∈classes∑(pi(C)−p^i(c))2
- ∑ i = 0 S 2 \sum_{i=0}^{S^2} ∑i=0S2:遍历所有的grid cell格子
- 1 i o b j 1^{obj}_{i} 1iobj:挑选不负责检测物体的bbox
- ∑ C ∈ c l a s s e s \sum_{C∈classes} ∑C∈classes:遍历所有类别
7、指示函数
前面的误差计算公式提到了三个指示函数:
7.1 第1个 1 i o b j 1^{obj}_{i} 1iobj
1 i o b j = { 1 , 如果第 i 个网格单元包含目标。 0 , 否则。 1^{obj}_{i} = \begin{cases} 1, & \text{如果第 } i \text{ 个网格单元包含目标。} \\ 0, & \text{否则。} \end{cases} 1iobj={1,0,如果第 i 个网格单元包含目标。否则。
1 i o b j 1^{obj}_{i} 1iobj:第i个grid cell是否包含物体,也即是否有groud truth框的中心点落在grid cell中,若有则为1,否则为0
7.2 第2个 1 i j o b j 1^{obj}_{ij} 1ijobj
1
i
j
o
b
j
=
{
1
,
如果第
i
个网格单元中的第
j
个边界框预测到了目标。
0
,
否则。
1^{obj}_{ij} = \begin{cases} 1, & \text{如果第 } i \text{ 个网格单元中的第 } j \text{ 个边界框预测到了目标。} \\ 0, & \text{否则。} \end{cases}
1ijobj={1,0,如果第 i 个网格单元中的第 j 个边界框预测到了目标。否则。
1
i
j
n
o
o
b
j
1^{noobj}_{ij}
1ijnoobj:第i个grid cell的第j个bounding box若负责预测物体则为1,否则为0
7.3 第3个 1 i j n o o b j 1^{noobj}_{ij} 1ijnoobj
1
i
j
n
o
o
b
j
=
{
1
,
如果第
i
个网格单元中的第
j
个边界框没有预测到目标。
0
,
否则。
1^{noobj}_{ij} = \begin{cases} 1, & \text{如果第 } i \text{ 个网格单元中的第 } j \text{ 个边界框没有预测到目标。} \\ 0, & \text{否则。} \end{cases}
1ijnoobj={1,0,如果第 i 个网格单元中的第 j 个边界框没有预测到目标。否则。
1
i
j
n
o
o
b
j
1^{noobj}_{ij}
1ijnoobj:第i个grid cell的第j个bounding box若不负责预测物体则为1,否则为0
- 1 i j o b j 1^{obj}_{ij} 1ijobj为1, 1 i o b j 1^{obj}_{i} 1iobj也必为1
- 1 i j o b j 1^{obj}_{ij} 1ijobj为1, 1 i j n o o b j 1^{noobj}_{ij} 1ijnoobj必为0
8、NMS(非极大值抑制)
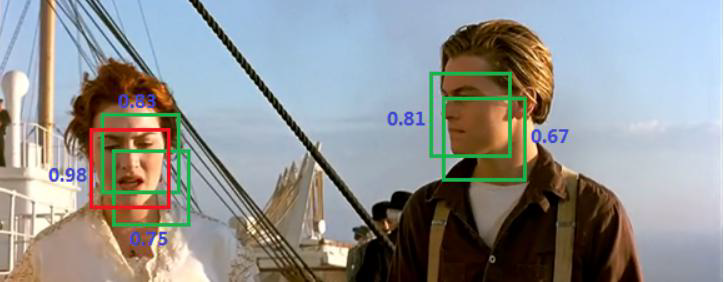
置信度是可以设置的,设置的较大的时候则比较严格,可能出现有些物体没有被检测,较小的时候可能一个物体出现多个预选框。
但是有时候就算设置较大的置信度,还是出现了多个预选框,我们可以进行非极大值抑制操作,对预选框的置信度进行排序,最终只选取较大的预选框。
YOLOV1到这里内容就全部都结束了,那YOLOV1有哪些问题呢?
- 小物体检测效果不好:当前一个grid cell只预测一个类别,当有两个物体高度重合在一起的时候,比如一只狗的旁边还有一只猫,那可能只能检测出狗。
- 多标签预测效果不好:这里介绍的是20分类,实际任务可以设置更多或者更少的分类,假设标签中有狗这个类别,还有斑点狗,还有哈士奇之类的,可能一个物体对应了两个标签,既是狗又是哈士奇,softmax可能无法拿到多个标签
那么YOLOV2做了哪些改进呢?















 681
681











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











