






文章目录
一、opencv 贝叶斯分类(官方示例)
1.1示例1
opencv官方代码小改。以坐标系上的几个标注点为训练集,用训练得到的模型把整个坐标系的点分类标注。
#include <opencv2/core.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/imgcodecs.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/ml.hpp>
using namespace cv;
using namespace cv::ml;
int main(int, char**)
{
// 样本数据
int labels[4] = { 1, 1, -3, -1 };
float trainingData[4][2] = { { 10, 10 },{ 10, 20 },{ 450, 100 },{ 150, 400 } };
// 封装数据
Mat labelsMat(4, 1, CV_32SC1, labels);
Mat trainingDataMat(4, 2, CV_32F, trainingData);
// 训练
// 创建贝叶斯分类器
Ptr<NormalBayesClassifier> Bayes = NormalBayesClassifier::create();
#if 1
Bayes->train(trainingDataMat, ROW_SAMPLE, labelsMat);
#else
Ptr<TrainData> tData = TrainData::create(trainingDataMat, ROW_SAMPLE, labelsMat);
Bayes->train(tData);
#endif
// 预测
// Data for visual representation
int width = 512, height = 512;
Mat image = Mat::zeros(height, width, CV_8UC3);
// Show the decision regions given by the SVM
Vec3b green(0, 255, 0), blue(255, 0, 0), red(40, 80, 170);
for (int i = 0; i < image.rows; i++)
{
for (int j = 0; j < image.cols; j++)
{
Mat sampleMat = (Mat_<float>(1, 2) << j, i);
float response = Bayes->predict(sampleMat);
if (response == 1)
image.at<Vec3b>(i, j) = green;
else if (response == -1)
image.at<Vec3b>(i, j) = blue;
else
image.at<Vec3b>(i, j) = red;
}
}
// Show the training data
int thickness = -1;
circle(image, Point(501, 10), 5, Scalar(0, 0, 0), thickness);
circle(image, Point(255, 10), 5, Scalar(255, 255, 255), thickness);
circle(image, Point(501, 255), 5, Scalar(255, 255, 255), thickness);
circle(image, Point(10, 501), 5, Scalar(255, 255, 255), thickness);
imwrite("bayes-result.png", image); // save the image
imshow("Bayes Simple Example", image); // show it to the user
waitKey();
return 0;
}
1.2示例2
将发热数据作为训练集,对新的数据分类
#include "opencv2/opencv.hpp"
#include "opencv2/ml.hpp"
#include <iostream>
using namespace cv;
using namespace cv::ml;
using namespace std;
int main(int argc, char** argv)
{
//样本数据
float trainingData[10][3] = {
{ 34,1,1 },
{ 35,2,2 },
{ 36,3,3 },
{ 37,8,4 },
{ 38,9,5 },
{ 39,10,6 },
{ 40,7,7 },
{ 41,4,8 },
{ 42,5,9 },
{ 43,6,10 }
};
float labels[10] = { 1,1,1,-1,-1,-1,0,0,0,0 };
//封装数据
Mat trainingDataMat(10, 3, CV_32FC1, trainingData);
Mat labelsMat(10, 1, CV_32SC1, labels); //标签值,1代表冷感冒,-1代表肺炎,0代表热感冒
//训练
//创建正态贝叶斯分类器
Ptr<NormalBayesClassifier> model = NormalBayesClassifier::create();
model->train(trainingDataMat, ROW_SAMPLE, labelsMat);
//预测
//已知的测试样本导入并进行分类器预测
float myData[3] = { 40, 8, 10 };
Mat myDataMat(1, 3, CV_32FC1, myData);
float r = model->predict(myDataMat);
int result = r;
//结果输出
string output;
switch (result)
{
case 1:
output = "Cold-cold";
break;
case -1:
output = "Pneumonia";
break;
case 0:
output = "Hot-cold";
break;
default:
output = "Healthy";
break;
}
cout << endl << "The patient's disease was diagnosed as : " << output << endl << endl;
system("pause");
return 0;
}
二、朴素贝叶斯算法实现分类以及Matlab实现
2.1开始
参考链接
http://t.csdn.cn/p6pRK
其实在学习机器学习的一些算法,最近也一直在看这方面的东西,并且尝试着使用Matlab进行一些算法的实现。这几天一直在看得就是贝叶斯算法实现一个分类问题。大概经过了一下这个过程:
看书→→算法公式推演→→网上查询资料→→进一步理解→→搜集数据集开始尝试→→写代码→→调试→→代码整理与优化→→自编代码结果与Matlab自带函数fitcnb结果对比验证→→朴素贝叶斯算法优缺点总结
经过这几天的努力,总算是把这个算法彻底弄明白了,也发现,很多算法只有自己去亲自写一写才会发现自己的不足,还是需要多努力。
2.2贝叶斯分类





2.3Matlab程序实现
程序
使用Matlab实现朴素贝叶斯算法的数据来源:http://archive.ics.uci.edu/ml/machine-learning-databases/balance-scale/balance-scale.data
不多说先开始上程序吧
clc
clear
close all
data=importdata('data.txt');
%% 数据导入
A=importdata('balance-scale.data');
% data=importdata('data.txt'); %Stephen博客上程序需要小修改
wholeData=A.data; label=A.textdata;
%wholeData=data.data;
%交叉验证选取训练集和测试集
cv=cvpartition(size(wholeData,1),'holdout',0.2);%0.04表明测试数据集占总数据集的比例
trainData=wholeData(training(cv),:);
testData=wholeData(test(cv),:);
%label=data.textdata;
attributeNumber=size(trainData,2);
attributeValueNumber=5;
%%
%将分类标签转化为数据
sampleNumber=size(label,1);
labelData=zeros(sampleNumber,1);
for i=1:sampleNumber
if label{i,1}=='R'
labelData(i,1)=1;
elseif label{i,1}=='B'
labelData(i,1)=2;
else
labelData(i,1)=3;
end
end
trainLabel=labelData(training(cv),:);
trainSampleNumber=size(trainLabel,1);
testLabel=labelData(test(cv),:);
%计算每个分类的样本的概率
labelProbability=tabulate(trainLabel);
%P_yi,计算P(yi)
P_y1=labelProbability(1,3)/100;
P_y2=labelProbability(2,3)/100;
P_y3=labelProbability(3,3)/100;
%%
%
count_1=zeros(attributeNumber,attributeValueNumber);%count_1(i,j):y=1情况下,第i个属性取j值的数量统计
count_2=zeros(attributeNumber,attributeValueNumber);%count_1(i,j):y=2情况下,第i个属性取j值的数量统计
count_3=zeros(attributeNumber,attributeValueNumber);%count_1(i,j):y=3情况下,第i个属性取j值的数量统计
%统计每一个特征的每个取值的数量
for jj=1:3
for j=1:trainSampleNumber
for ii=1:attributeNumber
for k=1:attributeValueNumber
if jj==1
if trainLabel(j,1)==1&&trainData(j,ii)==k
count_1(ii,k)=count_1(ii,k)+1;
end
elseif jj==2
if trainLabel(j,1)==2&&trainData(j,ii)==k
count_2(ii,k)=count_2(ii,k)+1;
end
else
if trainLabel(j,1)==3&&trainData(j,ii)==k
count_3(ii,k)=count_3(ii,k)+1;
end
end
end
end
end
end
%计算第i个属性取j值的概率,P_a_y1是分类为y=1前提下取值,其他依次类推。
P_a_y1=count_1./labelProbability(1,2);
P_a_y2=count_2./labelProbability(2,2);
P_a_y3=count_3./labelProbability(3,2);
%%
%使用测试集进行数据测试
labelPredictNumber=zeros(3,1);
predictLabel=zeros(size(testData,1),1);
for kk=1:size(testData,1)
testDataTemp=testData(kk,:);
Pxy1=1;
Pxy2=1;
Pxy3=1;
%计算P(x|yi)
for iii=1:attributeNumber
Pxy1=Pxy1*P_a_y1(iii,testDataTemp(iii));
Pxy2=Pxy2*P_a_y2(iii,testDataTemp(iii));
Pxy3=Pxy3*P_a_y3(iii,testDataTemp(iii));
end
%计算P(x|yi)*P(yi)
PxyPy1=P_y1*Pxy1;
PxyPy2=P_y2*Pxy2;
PxyPy3=P_y3*Pxy3;
if PxyPy1>PxyPy2&&PxyPy1>PxyPy3
predictLabel(kk,1)=1;
disp(['this item belongs to No.',num2str(1),' label or the R label'])
labelPredictNumber(1,1)=labelPredictNumber(1,1)+1;
elseif PxyPy2>PxyPy1&&PxyPy2>PxyPy3
predictLabel(kk,1)=2;
labelPredictNumber(2,1)=labelPredictNumber(2,1)+1;
disp(['this item belongs to No.',num2str(2),' label or the B label'])
elseif PxyPy3>PxyPy2&&PxyPy3>PxyPy1
predictLabel(kk,1)=3;
labelPredictNumber(3,1)=labelPredictNumber(3,1)+1;
disp(['this item belongs to No.',num2str(3),' label or the L label'])
end
end
testLabelCount=tabulate(testLabel);
% 计算混淆矩阵
disp('the confusion matrix is : ')
C_Bayes=confusionmat(testLabel,predictLabel)
以上部分就是针对于这个已有的数据集进行的算法的实现。
结果与分析
C_Bayes是计算出来的混淆矩阵。
其结果为:

为了验证该自编程序是否可靠,我再使用了Matlab自带的贝叶斯算法的函数fitcnb进行该数据的分类测试
clc
clear
close all
data=importdata('data.txt');
%% 数据导入
A=importdata('balance-scale.data');
% data=importdata('data.txt'); %Stephen博客上程序需要小修改
wholeData=A.data; label=A.textdata;
%wholeData=data.data;
%交叉验证选取训练集和测试集
cv=cvpartition(size(wholeData,1),'holdout',0.04);%0.04表明测试数据集占总数据集的比例
trainData=wholeData(training(cv),:);
testData=wholeData(test(cv),:);
%label=data.textdata;
attributeNumber=size(trainData,2);
attributeValueNumber=5;
%%
%将分类标签转化为数据
sampleNumber=size(label,1);
labelData=zeros(sampleNumber,1);
for i=1:sampleNumber
if label{i,1}=='R'
labelData(i,1)=1;
elseif label{i,1}=='B'
labelData(i,1)=2;
else
labelData(i,1)=3;
end
end
trainLabel=labelData(training(cv),:);
trainSampleNumber=size(trainLabel,1);
testLabel=labelData(test(cv),:);
Nb=fitcnb(trainData,trainLabel);
y_nb=Nb.predict(testData);
C_nb=confusionmat(testLabel,y_nb)
其中C_nb是采用自带函数得到的结果的混淆矩阵
其结果为:

可以发现其结果是完全一样的。
为了进一步验证程序的可靠性,我改变了交叉验证中训练集和测试集的比例,设置为0.2,
此时采用自编程序得到的混淆矩阵为:
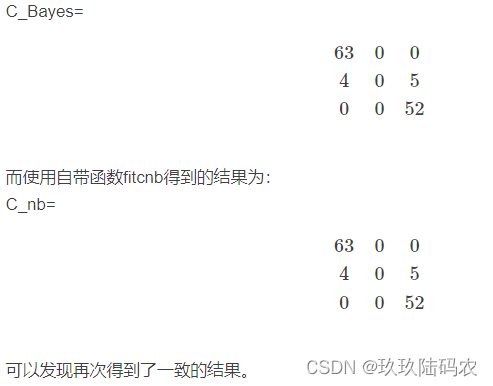

2.4问题
【1】为什么我用这个数据跑出来的结果和matlab内置函数结果不一样?
【回答】交叉验证的训练集和测试集是按比例随机分割的
2.6贝叶斯算法wine分类
close all;
clear;
clc;
format compact;
%% 数据提取
% 载入测试数据wine,其中包含的数据为classnumber = 3,wine:178*13的矩阵,wine_labes:178*1的列向量
load wine.mat;
% 选定训练集和测试集
% 将第一类的1-30,第二类的60-95,第三类的131-153做为训练集
train_wine = [wine(1:30,:);wine(60:95,:);wine(131:153,:)];
% 相应的训练集的标签也要分离出来
train_wine_labels = [wine_labels(1:30);wine_labels(60:95);wine_labels(131:153)];
% 将第一类的31-59,第二类的96-130,第三类的154-178做为测试集
test_wine = [wine(31:59,:);wine(96:130,:);wine(154:178,:)];
% 相应的测试集的标签也要分离出来
test_wine_labels = [wine_labels(31:59);wine_labels(96:130);wine_labels(154:178)];
Nb=fitcnb(train_wine,train_wine_labels);
y_nb=Nb.predict(test_wine)
C_nb=confusionmat(test_wine_labels,y_nb)

三、分类与监督学习
简述分类与聚类的联系与区别,简述什么是监督学习与无监督学习。
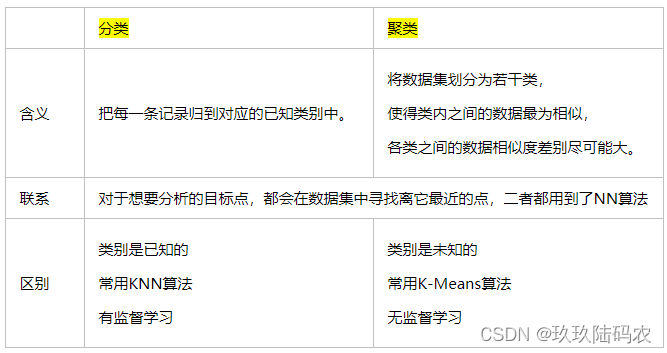
【1】监督学习:输入数据有标签,数据集的正确输出已知的情况下一类学习算法。因为输入和输出已知,意味着输入和输出之间有一个关系,监督学习算法就是要发现和总结这种“关系”。
应用:
根据人的照片预测图片中人的年龄。
对于肿瘤患者,预测肿瘤是恶性还是良性。
【2】无监督学习:输入数据没有标签,对无标签数据的一类学习算法。因为没有标签信息,意味着需要从数据集中发现和总结模式或者结构。
应用:
新闻主题分组。
市场客户群体划分。















 2622
2622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









