






文章目录
论文介绍:Document-Level Relation Extraction with Adaptive Focal Loss and Knowledge Distillation是关系提取领域-DocRED数据集的state-of-art
论文地址:2203.10900v1.pdf (arxiv.org)
摘要
Document-level Relation Extraction(DocRE) 相比句级关系提取来说更麻烦。它需要一次从多个句子中提取关系。这篇论文提出了一种半监督框架,并且有三个新颖点。第一,使用了一个轴向注意力模块来学习实体对的相关性;第二,提出了一个适应性焦距损失来解决DocRE的类不平衡问题;第三,使用知识蒸馏来克服人类标注数据与远程监督数据的差异性。
(轴向注意力就是先在竖直方向进行self-attention,然后再在水平方向进行self-attention;
远程监督数据指的是所有包含目标实体对,但是这些实体对不一定具有关系的数据,是关系提取常用的数据源,含有噪音)
1. 导言
DocRE的复杂性在于以下方面:1. DocRE的复杂性随着实体数量得到增多而呈平方级增长,假设文章有 n 个实体,那么需要在 n(n-1) 个实体对上做分类,而它们中的大多数并没有任何关系;2. 很多数据集里,除了正样本和负样本间的不平衡,正实体对的关系类型的分布也是高度不平衡的。
大多数DocER的方法利用依赖信息来建立一个文章级图,然后用图神经网络来做推理。另一部分则是使用基于transformer的架构,这些模型通常使用预训练语言模型来隐式地捕捉长距离关系。然而,以上方法有三个缺陷:1. 它们利用从预训练语言模型得到的语法特征,但是忽视了实体对的相互关系。2. 没有工作去明确地解决类不平衡问题。3. 几乎没有工作讨论如何利用远程监督数据。 Xu et al. 证明了使用远程监督数据可以提升文章级关系提取的性能。然而,他们使用这个方法的方式很幼稚。
第一,为了提升对两跳信息的推断,论文提出使用轴向注意力模块作为特征提取器。这个模块能够关注处于两跳逻辑路径的元素,并且捕捉到关系三元组间的相关性。(两跳指的是实体对
(
e
s
,
e
o
)
(e_s,e_o)
(es,eo) 可以划分成两个实体对
(
e
s
,
e
i
)
(e_s,e_i)
(es,ei),
(
e
i
,
e
o
)
(e_i,e_o)
(ei,eo),那么视为
e
s
e_s
es和
e
o
e_o
eo的距离为两跳)
第二,提出适应性焦距损失来解决类不平衡问题,这个损失函数能够让长尾分布的类别贡献更多的损失,即更关注这些类别。
第三,用知识蒸馏来克服人类标注数据与远程监督数据的差异性。具体来说,首先用少批量的标注数据训练一个教师模型,然后用这个模型来在大批量的远程监督数据上做预测。这些生成的预测作为软标签来预训练学生模型。最后,这个预训练的学生模型在人工标注的数据中做微调。
关于知识蒸馏的详细介绍,可见博客【经典简读】知识蒸馏(Knowledge Distillation) 经典之作 - 知乎 (zhihu.com)
2. 方法论
2.1 问题制定
已知文本D和它所包含的一系列实体 e i e_i ei,一个实体可能在文章中出现多次,因此对于每一个实体,会有多个mention。文章级的关系提取任务就是预测不同文本对间的关系,而一个文本对间可能有多个关系,所以这就是一个多标签分类问题。
2.2 模型架构
模型架构如下图:

有三个部分:1. 特征表示学习,2. 适应性焦距损失, 3. 知识蒸馏
- 我们首先用一个预训练的语言模型来提取实体对的上下文表示,然后这个表示会被轴向注意力模组增强,它能够编码实体对之间的相关性
- 然后我们用一个前馈神经网络分类器来得到 logits 并计算它们的损失。用适应性焦距损失来更好地从长尾分布的类别中学习
(logits一般指未归一化的概率,即softmax层的输入) - 我们用标注数据来训练一个教师模型,并用它的输出作为软标签。然后我们用这些软标签和远程标签来预训练一个学生模型,这个学生模型最后被标注数据微调。
2.2.1 特征表示学习
实体表示
我们用一个预训练语言模型作为编码器。对于一个长度为
l
l
l 的文本
D
=
[
x
t
]
t
=
1
l
D=[x_t]_{t=1}^l
D=[xt]t=1l,
x
t
x_t
xt 是在位置
t
t
t处的单词。依据一些先验工作,我们用特殊的记号来标记实体,在实体的mention的开始位置和结束位置会有一个特殊的记号’*'。然后我们用预训练的语言模型来得到这个文本的contextualized embeddings H。

如果这个文本长度超过PrLM设定的最大长度,就会把它编码成多个相互重叠的组块,然后平均这些组块的contextualized embedding。对于标志着mention开始的标记"*",将它的嵌入直接作为嵌入,而对于实体
e
j
e_j
ej 的 mentions
{
m
j
i
}
j
=
1
N
e
i
\{m_j^i\} _{j=1}^{N_{e_i}}
{mji}j=1Nei,
N
e
i
N_{e_i}
Nei 是实体
e
j
e_j
ej 的mentions的数量,它的全局表示由 logsumexp pooling 得到,数学公式如下:

context-enhanced 实体表示
之前的工作证明了上下文信息对关系分类任务很重要,这篇论文沿用了 Zhou et al.所使用的 contextual pooling method。对于每个实体
e
i
e_i
ei,先把它的mentions的 attention output 加和起来,公式如下:

对于实体对 (s,o),计算context vector
c
(
s
,
o
)
c^{(s,o)}
c(s,o) ,计算公式如下:

然后将context vector和实体表示联合起来,得到主体s的 context-enhanced 表示如下:

客体
z
o
z_o
zo 计算过程与 (5) 相近。
z
∈
R
d
z\in R^d
z∈Rd
实体对表示
仿效 Zhou 的做法,使用了分组的双线性函数做特征组合。实体的嵌入表示
z
s
z_s
zs 先被分成 k 个同等大小的组,
z
s
=
[
z
s
1
,
z
s
2
,
…
,
z
s
k
]
z_s = [z_s^1, z_s^2, \dots, z_s^k]
zs=[zs1,zs2,…,zsk],
z
o
z_o
zo 的划分同理。实体对表示
g
(
s
,
o
)
g^{(s,o)}
g(s,o)由以下公式得到:

对于有n个实体的文本D,需要对 n(n-1)个实体对排列做分类。为了方便对这些实体对和位置做编码,使用 (n,n,d) 大小的矩阵 G 来表示所有的文本对,(n,n)对角线上的向量忽略。
轴向注意力加强的实体对表示
论文提出使用两跳注意力来编码每个样本对表示的轴向周边信息。有人用过CNN来编码附近的信息,而作者相信注意样本对的轴向临近元素效果更好。
已知 (n,n) 大小的实体表,对于实体对
(
e
s
,
e
o
)
(e_s,e_o)
(es,eo),注意它的轴向元素就是注意实体对
(
e
s
,
e
i
)
(e_s,e_i)
(es,ei)和实体对
(
e
i
,
e
o
)
(e_i,e_o)
(ei,eo)。如果实体对
(
e
s
,
e
o
)
(e_s,e_o)
(es,eo)是一个两跳的关系,即这个关系可以被分解为
(
e
s
,
e
i
)
(e_s,e_i)
(es,ei),
(
e
i
,
e
o
)
(e_i,e_o)
(ei,eo),那么在区分实体对
(
e
s
,
e
o
)
(e_s,e_o)
(es,eo)时,最能提供信息的就是分解出来的这两个一跳关系。轴向注意力就是沿着实体表的横向和纵向计算自注意力,具体的计算公式如下:

这个计算与 Wang et al等人的计算方式相似,但是出发点不同。Wang et al是用轴向注意力代替整个矩阵的注意力计算来减少计算复杂度,而作者是为了引入一跳关系的信息。
2.2.2 适应性焦距损失 (Adaptive Focal Loss)
轴向注意力模块之上还有一个MLP,经过它会得到对所有关系的 logit,公式如下:

对于一般的多标签分类问题来说,一般会使用 binary cross-entropy 损失函数。不过这个问题需要一个全局概率阈值,来推断实体对间是否存在关系。
最近 Zhou et al提出了适应性阈值损失(ATL)来应对多标签分类问题。它没有对所有样本都是用同一个全局概率阈值,而是引入了一个特殊的类标签 TH,对每一个样本,都把它作为一个适应性的阈值。对于每一个实体对,预测类的 logit 高于 TH 的logit 的,就将它预测为正类,否则预测为负类。
作者基于ATL提出了AFL来应对长尾分布的类。损失函数由两部分构成,一部分关于正类,另一部分关于负类。训练时,基于 TH 类的 logit, 可以将类空间划分为正类集
P
T
P_T
PT 和负类集
N
T
N_T
NT,正类集包含了实体对
(
e
s
,
e
o
)
(e_s,e_o)
(es,eo) 之间的所有关系,如果没有关系,正类集就是空集;负类集包含了不属于正类集的其他关系。对于每一个正类,它的概率计算公式如下:

与ATL不同的是,ATL的分母是对所有正类的logit的 softmax
对于负类,用它们的 logit 来计算 TH 的概率:

为了简写,以上两个概率记为
P
(
r
i
)
P(r_i)
P(ri) 和
P
(
r
T
H
)
P(r_{TH})
P(rTH)。
由于正标签的分布一般是高度不平衡的,作者利用了焦距损失的思想,损失函数如下:
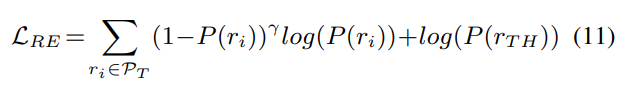
γ
\gamma
γ 是一个超参数。
如果
P
(
r
i
)
P(r_i)
P(ri) 比较小,那么
r
i
r_i
ri 对应的类对损失函数的贡献就会更大,因此对长尾分布的类更有利
2.2.3 Knowledge Distillation for Distant Supervision
作者比较了利用远程监督数据的两种策略:
Naive Adaptation(NA)
Xu et al所使用的方法,首先用远程监督数据和 (11)式的损失函数来预训练模型,然后用人工标注数据来做微调
Knowledge Distillation(KD)
作者用一个在人工标注数据上训练的关系分类模型作为教师模型。然后用教师模型在远程监督数据上生成软标签。具体来说,远程监督数据被喂到教师模型里,而生成的logit作为软标签。学生模型的构造和教师模型一致,但它同时用两个信号来训练。第一个信号是远程监督数据的硬标签,第二个信号是教师模型预测的软标签,并且在远程监督数据上训练。
在硬标签上计算的损失函数记为
L
R
E
L_{RE}
LRE,知识蒸馏计算得到的损失函数记为
L
K
D
L_{KD}
LKD。具体的计算公式如下:

学生模型的总的损失函数公式如下:

之后学生模型会在人工标注数据上进行微调。
3. 实验
3.1 数据集
实验使用的数据集如下图,可以看到DocRED中包含大量的远程监督数据。
HacRED是一个中文关系抽取数据集,关注硬关系。

3.2 实现细节
Pytorch+Huggingface Transformers
BERT:
- DocRED测试了Roberta-large 和 Bert-base
- HacRED测试了XLM-R base
优化器:AdamW
其他细节间原论文
3.3 方法比较
介绍了一些进行比较的模型
3.4 主要结果
知识蒸馏能够大幅提升作者的模型。不使用知识蒸馏,也能得到不错的效果。
模型在HacRED上的效果要比DocRED上的效果高很多,有两个可能的因素:
- HacRED的标注训练样本比DocRED多很多
- HacRED的关系类型分布要更均很
3.5 消融实验
首先把标签分为两个子集,第一个子集包含了最多的十个标签,占正标签的 59.4%,第二个自己包含了剩下的86个标签,将AFL更换为ATL,观察AFL的效果。实验发现更换为ATL之后,总性能的F1分数下降,且在长尾标签上的下降值要比在总标签和频繁标签上的下降值更大,说明AFL确实起到了效果。轴向注意力模块也对长尾标签更有利。
然后检验轴向注意力模块,作者还比较了 Zeng et al利用多跳关系的方法,实验结果说明轴向注意力模块有效且利用多跳注意力关系的方法更好。
3.6 对远程监督数据的利用
比较了三种方法:
- NA
- KD_KL: 使用KL divergence loss的知识蒸馏
- KD_MSE: 使用MSE的知识蒸馏
KD_MSE效果更好
4. 误差分析
作者结合模型的预测值和真实值做了一个误差分析,分析表如下:

发现模型犯的错误主要是:模型对实体对间是否存在关系的误判
作者在分析了数据集的采样后认为这可能是因为 DocRED数据集里面存在不完备的标注所导致的














 5395
5395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









