







算法algorithms
1. 算法概念
- 以有限的步骤, 解决逻辑或数学上的问题, 这 一专门科目我们称为算法(Algorithms)。
- 算法与数据结构(Data Structures , 亦即STL中的容器,本书4,5两章巳介绍)。
- 广义而言,我们所写的每个程序都是一个算法,其中的每个函数也都是一个算法,毕竟它们都用来解决或大或小的逻辑问题或数学问题。
- 唯有用来解决特定间题(例如排序、查找、最短路径、 三点共线…),并且获得数学上的效能分析与证明, 这样的算法才具有可复用性。
- 本章探讨的便是被收记录于STL之中,极具复用价值 的70余个STL算法, 包括赫赫有名的排序(sorting)、 查找(searching)、 排列组合(permutation)算法, 以及用于数据移动、 复制、 删除、 比较、 组合、 运算等等的算法。
- 特定的算法往往搭配特定的数据结构。
- 例如binary search tree (二叉查找树)和RB-tree(红黑树,5.2节)便是为了解决查找问题而发展出来的特殊数据结构。
- hashtable(散列表,5.7节)拥有快速查找的能力。
- 又例如max-heap(或min-heap) 可以协助完成所谓的heapsort (堆排序)。
- 几乎可以说,特定的数据结构是为了实现某种特定的算法。这一类”与特定数据结构相关"的算法,被本书(及STL)归 类于第5章“关系型容器"(associated containers)之列。
- 本章所讨论的,是可施行于“无太多特殊条件限制”之空间中的某一段元素区间的算法。
1.1 算法分析与复杂度表示O()
- 当发现一个可以解决问题的算法时,下一个重要步骤就是决定该算法所耗用的资源,包括空间和时间。这个操作称为算法分析(algorithm analysis)。
- 可以这么说,如果一个算法得耗用数GB的内存空间才能获得令人满意的效率,这种算法没有用。(至少在目前的计算机架构下没有实用价值)。
- 一般而言,算法的执行时间和其所要处理的数据量有关,两者之间存在某种函 数关系,可能是一次(线性,linear)、二次(quadratic)、三次(cubic)或对数(logarithm) 关系。
- 当数据量很小时,多项式函数的每一项都可能对结果带来相当程度的影响, 但是当数据量够大(这是我们应该关注的情况)时,只有最高次方的项目才具主导地位。
下面是三个复杂各异的问题:
- 最小元素问题:求取array中的最小元素。:最小元素问题的解法一定必须两两元素比对,逐一进行。N个元素需要N次比 对,所以数据量和执行时间呈线性关系。
- 最短距离问题:求取X-Y平面上的N个点中,距离最近的两个点。:“最短距离”问题所需计算的元素对(pairs) 共有N(N-1)/2!,所以大数据量和执行时间呈二次关系。
- 三点共线问题:决定X-Y平面上的N个点中,是否有任何三点共线。:"三点共线”问题要计算的元素对(pairs)共有N(N-1)(N-2)/3!, 所以大数据量和执行时间呈三次关系。
上述三种复杂度, 以所谓的Big-Oh标记法表示为O(N), O(N²), O(N³)。 这种 标记法的定义如下:
如果有任何正值常数c和N0(0下标), 使得当N ≥N0(0为下标)时,T(N) ≤ cF(N), 那么我们便可将T(N)的复杂度表示为O(F(N)) 。(注意,在此定义之下,意味着数据量必须足够大,而且最高次方的常系数和较低次方 的项, 都不应该出现在Big-Oh标记法中。)
Big-Oh并非唯一的复杂度标记法, 另外还有诸如Big-Omega, Big-Theta, Little-Oh等标记法, 各有各的优缺点。 一般而言,Big-Oh标记法最被普遍使用。 但是它并不适合用来标记小数据量下的情况。
以下三个问题出现一种新的复杂度形式:
-
需要多少bits才能表现出N个连续整数?
-
从X= 1开始, 每次将X扩充两倍, 需要多少次扩充才能使X≥N?
-
从X=N开始, 每次将X缩减一半, 需要多少次缩减才能使x≤1?
-
就问题1而言,B个bits可表现出2B(B上标)个不同的整数,因此欲表现N个连续整 数, 需满足方程式2B(B上标)≥N, 亦即B≥logN。
- 问题2称为 "持续加倍问题” , 必须满足方程式2K(K上标) ≥N, 此式同问题1, 因 此解答相同 。
- 问题3称为 "持续减半问题” ,与问题2意义相同, 只不过方向相 反, 因此解答相同。
- 如果有一个算法,花费固定时间(常数时间,O(1))将问题的规模降低某个固 定比例(通常是1/2), 基于上述问题3的解答,我们便说此算法的复杂度是O(logN)。
- 注意, 问题规模的降低比例如何, 并不会带来影响, 因为它会反应在对数的底上, 而底对于Big-Oh标记法是没有影响的(任何算法专论书籍, 都应该有其证明)。
1.2 STL算法总览
下图将所有的STL算法(以及一些非标准的SGI STL算法)的名称、用途、 文件分布等等,依算法名称的字母顺序列表。表格之中凡是不在STL标准规格之 列的SGI专属算法,都以*加以标示。
注:(以下 “质变 ” 栏意指mutating, 意思是 “会改变其操作对象之内容,)




1.3 质变算法mutating algorithms(会改变操作对象之值)
- 所有的STL算法都作用在由迭代器[first,last)所标示出来的区间上。
- 所 谓“质变算法”,是指运算过程中会更改区间内(迭代器所指)的元素内容。
- 诸如拷贝(copy)、互换(swap)、替换(replace)、填写(fill)、删除(remove)、 排列组合(permutation)、分割(partition)、随机重排(random shuffling)、排序(sort)等算法,都属此类。如果你将这类算法运用于一个常数区间上,例如
int ia[] = {
22 ,30,30 ,17,33,40,17, 23, 22,12, 20 };
vector<int> iv(ia, ia+sizeof(ia)/sizeof(int));
vector<int>::const_iterator cite1 =iv.begin();
vector<int>::const_iterator cite2 = iv.end();
sort(cite1,cite2);
针对上述的sort操作,编译器会有错误信息。
1.4 非质变算法nonmutating algorithms(不改变操作对象之值)
- 所有的STL算法都作用在由迭代器[first,last)所标示出来的区间上。
- 所谓“非质变算法",是指运算过程中不会更改区间内(迭代器所指)的元素内容。
- 诸如查找(find)、匹配(search)、计数(count)、巡访(for_each)、比较(equal,mismatch)、寻找极值(max,min)等算法,都属此类。但是如果你在for_each(巡访每个元素)算法身上应用一个会改变元素内容的仿函数(functor), 例如:
template<class T>
struct plus2{
void operator()(T& x)const
{
x +=2;}
};
int ia[] = {
22,30,30,17,33,40,17,23,22,12,20 };
vector<int>iv(ia, ia+sizeof(ia)/sizeof(int));
for_each(iv.begin(), iv.end(), plus2<int>());
那么当然元素会被改变。
1.5 STL算法的一般形式
-
所有泛型算法的前两个参数都是一对迭代器(iterators), 通常称为first和last,用以标示算法的操作区间。
-
STL习惯采用前闭后开区间(或称左涵盖区间)表示法,写成[first,last),表示区间涵盖first至last(不含last)之间的 所有元素。
-
当first==last时,上述所表现的便是一个空区间。
-
这个[first,last)区间的必要条件是,必须能够经由increment(累加)操作符的反复运用,从first到达last。
-
编译器本身无法强求这一点。如果这个条件不成立,会导致未可预期的结果。
根据行进特性,迭代器可分为5类(见3.4.5),每一个STL算法的声明,都表现出它所需的最低程度的迭代器类型。
- 例如find()需要一个lnputlterator, 这是它的最低要求, 但它也可以接受更高类型的迭代器, 如Forwardlterator, Bidirectionallterator或RandomAccesslterator , 因为, 由3.4.5图观之, 不论 ForwardIterator或Bidirectionallterator或RandomAccesslterator也都是 一 种 lnputtterator。但如果你交给find() 一个Outputtterator, 会导致错误。
- 将无效的迭代器传给某个算法,虽然是一种错误,却不保证能够在编译时期就被捕捉出来,因为所谓 “迭代器类型”并不是真实的型别,它们只是function template 的一种型别参数(type parameters)。
许多STL算法不只支持一个版本。这一类算法的某个版本采用缺省运算行为,另一个版本提供额外参数,接受外界传入一个仿函数(functor) , 以便采用其他策略。:
- 例如unique()缺省情况下使用equality操作符来比较两个相邻元素,但如果这些元素的型别并未供应equality操作符,或如果用户希望定义自己的equality操作符,便可以传一个仿函数(functor)给另一版本的unique()。
有些算法干脆 将这样的两个版本分为两个不同名称的实体,附从的那个总是以 _if作为尾词:
- 例如find_if ()。 另 一个例子是replace(), 使用内建的equality操作符进行比对操作,replace_if ()则以接收到的仿函数(functor)进行比对行为。
质变算法(mutating algorithms)通常提供两个版本:
-
一个是in-place(就地进行)版,就地改变其操作对象; 另 一个是copy (另地进行)版,将操作 对象的内容复制一份副本,然后在副本上进行修改并返回该副本。
-
copy版总是以 _copy作为函数名称尾词,例如replace ()和 replace_copy ()。
-
并不是所有质 变算法都有copy版, 例如sort()就没有。
-
如果我们希望以这类 “无copy版本 之质变算法施行于某一段区间元素的副本身上,我们必须自行制作并传递那一份副本。
所有的数值(numeric)算法,包括adjacent_difference(), accumulate(), inner_product () , partial_sum()等等,都实现于SGl<stl_numeric.h>之中,这是个内部文件,STL规定用户必须包含的是上层的。其他STL算 法都实现于SGI的<stl_algo.h>和<stl_algobase.h>文件中,也都是内部文件;欲使用这些算法,必须先包含上层相关头文件。
2. 算法的泛化过程
- 将一个叙述完整的算法转化为程序代码,是任何训练有素的程序员胜任愉快的工作。这些工作有的极其简单(例如循序查找),有的稍微复杂(例如快速排序法), 有的十分繁复(例如红黑树之建立与元素存取),但基本上都不应该形成任何难以跨越的障碍。
- 如何将算法独立于其所处理的数据结构之外,不受数据结构的羁绊,思想层面就不是那么简单了。
- 如何设计一个算法, 使它适用于任何(或大多数)数据 结构呢?换个说法, 我们如何在即将处理的未知的数据结构(也许是array, 也许 是vector, 也许是list, 也许是deque… )上, 正确地实现所有操作呢?
- 关键在于,只要把操作对象的型别加以抽象化,把操作对象的标示法和区间目 标的移动行为抽象化,整个算法也就在 一个抽象层面上工作了。 整个过程称为算法 的泛型化(generalized) , 简称泛化。
项目是个算法泛化的实例,以简单的循序查找为例,假设写个find()函数,在array中寻找特定值,面对整数array,我们直觉反应是:
int* find(int* arrayHead,int arraySize,int value)
{
for(int i=0;i<arraySize;++i)
if(arrayHead[i] == value)
break;
return &(arrayHead[i]);
}
- 该函数在某个区间内查找value。返回的是一个指针, 指向它所找到的第一个符合条件的元素;
- 如果没有找到, 就返回最后一个元素的下一位置(地址)。“最后元素的下一位置” 称为end。
- 返回 end以表示 “查找无结果” 似乎是个可笑的做法。 为什么不返回null? 稍后即将见到的, end 指针可以 对其他种类的容器带来泛型效果, 这是null所无法达到的。
- 使用array时千万不要超越其区间,但事实上一个指向array元素的指针, 不但可以合法地指向array内的任何位置, 也可以指向array尾端以外的任何位 置。
- 只不过当指针指向array尾端以外的位置时, 它只能用来与其他array指针 相比较, 不能提领(dereference)其值。 现在, 你可以这样使用find()函数:
const int arraySize = 7;
int ia[arraySize] = {
0,1,2,3,4,5,6};
int* end = ia+arraySize;//最后元素的下一个位置
int* ip = find(ia,sizeof(ia)/sizeof(int),4);
if(ip == end)//两个array指针比较
cout<<"4 not found"<<endl;
else
cout<<"4 found"<<*ip<<endl;
find()的这种做法暴露了容器太多的实现细节(例如arraySize) , 也因此 太过依附特定容器。为了让find()适用于所有类型的容器,其操作应该更抽象化 些。 让find()接受两个指针作为参数, 标示出一个操作区间, 就是很好的做法:
int* find(int* begin,int* end,int value)
{
while(begin !=end && *begin !=value)
++begin;
return begnin;
}
这个函数在“前闭后开”区间[begin,end)内(不含end;end指向array最后元素的下一位置)查找value,并返回一个指针,指向它所找到的第一个符合条件的元素;如果没有找到,就返回end。可以使用find()函数:
const int arraySize 7 ;
int ia[arraySize]={
0,1,2,3,4,5,6};
int* end = ia+arraySize;
int * ip = find(ia,end,4);
if(ip ==end)
cout<<"4 not found"<<endl;
else
cout<<"4 found"<<*ip<<endl;
find()函数也可以很方便地用来查找array的子区间:
int* ip =find(ia+2,ia+5,3);
if(ip == end)
cout<<"3 not found"<<endl;
else
cout<<"3 found"<<*ip<<endl;
由于find()函数之内并无任何操作是针对特定的整数array而发的,所以我们可将它改成一个template:
template <typename T>//关键字typename也可改为关键字class
T* find(T* begin,T* end,const T& value)
{
//注意,以下用到operator!=,operator*,operator++
while(begin !=end && *begin !=value)
++begin;
//注意,以下返回操作会引发copy行为
return begin;
}
请注意数值的传递由pass-by-value改为pass-by-reference-to-const , 因为 如今所传递的value, 其型别可为任意;于是对象一大, 传递成本便会提升, 这是 我们不愿见到的。pass-by-reference可完全避免这些成本。
这样的find()很好, 几乎适用于任何容器一一只要该容器允许指针指入, 而指针们又都支持以下四种find()函数中出现的操作行为:
- inequality (判断不相等)操作符
- dereferencelm (提领,取值)操作符
- prefix increment (前置式递增)操作符
- copy (复制)行为(以便产生函数的返回值)
- C++有一个极大的优点, 几乎所有东西都可以改写为程序员自定义的形式或行为。是的, 上述这些操作符或操作行为都可以被重载(overloaded) , 既是如此,何必将find限制为只能使用指针呢?何不让支持以上四种行为的、行为很 像指针的 "某种对象” 都可以被find()使用呢?
-
如此 一来, find()函数便可以从原生(native)指针的思想框框中跳脱出来。 如果我们以一个原生指针指向某个 list, 则对该指针进行"++ “操作并不能使它指向下一个串行节点。但如果我们设计一个class,拥有原生指针的行为,并使其”++"操作指向list的下一个节点,那么find()就可以施行于list容器身上了。
- 这便是迭代器(iterator,第三章)的观念。迭代器是一种行为类似指针的对象,换句话说,是一种smart pointerss。现在我将find()函数内的指针以迭代器取代, 重新写过:
-
template<class Iterator, class T>
Iterator find(Iterator begin, Iterator end, const T& value)
{
while(begin !=end && *begin !=value)
++begin;
return begin;
}
这便是一个完全泛型化的find()函数。你可以在任何C++标准库的某个头文件里看到它,长相几乎一模一样。SGI STL把它放在<stl_algo.h>之中。有了这样的观念与准备,再来看STL各式各样的泛型算法,就轻松多了。以 下列出(几乎)所有STL算法的源代码,并列有用途说明与操作示范。
3. 数值算法(stl_numeric.h)
这一节介绍的算法,统称为数值(numeric)算法。STL规定,使用它们客户端必须包含头文件。SGL将它们实现于<stl_numeric.h>文件中。
3.1 运用实例
- 观察这些算法的源代码之前,先示范其用法,是个比较好的学习方式。以下程序展示本节所介绍的每一个算法的用途。
- 例中使用ostream_iterator作为输出工具,第8章会深入介绍它,目前请想象它是个绑定到屏幕的迭代器;
- 只要将任何型别吻合条件的数据丢往这个迭代器,便会显于屏幕上,而这一迭代器会自动跳到下一个可显示位置。
- 例中使用ostream_iterator作为输出工具,第8章会深入介绍它,目前请想象它是个绑定到屏幕的迭代器;
#include<numeric>
#include<vector>
#include<functional>
#include<iostream>//ostream_iterator
#include<iterator>
using namespace std;
int main()
{
int ia[5] = {
1,2,3,4,5};
verctor<int> iv(ia,ia+5);
cout<<accumulate(iv.begin(),iv.end(),0)<<endl;
//15,i.e. 0+1+2+4+5
cout << accumulate(iv.begin() , iv.end(),0, minus<int> ())<< endl;
// -15, i.e. O -1 -2 -3 -4 -5
cout << inner_product(iv. begin() , iv.end() , iv.begin(),10)<<endl;
// 65, i.e. 10 + 1*1 + 2*2 + 3*3 + 4*4 + 5*5
cout << inner_product(iv.begin(), iv.end(), iv.begin(), 10,
minus<int>(), plus<int>()) << endl;
// -20, i.e. 10 -1+1 -2+2 -3+3 -4+4 -5+5
//以下这个迭代器将绑定到cout,作为输出用
ostream_iterator<int>oite (cout, " ");
partial_sum(iv.begin(),iv.end(),oite);
//1 2 6 10 15(第n个元素是前旧元素的相加统计)
partial_sum(iv.begin(),iv.end(),oite,minus<int>());
adjacent_difference(iv.begin(),iv.end(),oite);
// 1 1 1 1 1(#1元素照录,#n新元素等于#n旧元素-#n-1旧元素)
adjacent_difference(iv.begin(),iv.end(),oite,plus<int>());
//1 3 5 7 9(#1元素照录,#n新元素等于op(#n旧元素,#n-1旧元素))
cout<<power(10,3)<<endl;//1000 i.e 10*10*10
cout<<power(10,3,plus<int>())<<endl;//30 i.e 10+10+10
int n= 3;
iota(iv.begin(),iv.end(),n);//在指定区间内填入n,n+1,n+2...
for(int i=0;i<iv.size();++i)
cout<<iv[i]<<' ';//3 4 5 6 7
}
3.2 accumulate
//版本1
template<class InputIterator,class T>
T accumulate(InputIterator first,InputIterator last,T init){
for( ;first !=last;++first)
init = init+*first;//将每个元素值累加到初值init身上
return init;
}
//版本2
template<class InputIterator,class T,class BinaryOperation>
T accumulate(InputIterator first,InputIterator last,Tinit,BinaryOperator binary_op){
for( ; first !=last;++first)
init = binary_op(init,*first);//对每一个元素执行二元操作
return init;
}
- 算法 accumulate用来计算init和[first,last)内所有元素的总和。 注意, 你一定得提供一个初始值init, 这么做的原因之一是当[first,last)为空区间时仍能获得一个明确定义的值。 如果希望计算[first,last)中所有数值的 总和, 应该将init设为0。
- 式中的二元操作符不必满足交换律(commutive)和结合律。是的,accumulate的行为顺序有明确的定义:先将init初始化,然后针对 [first.last)区间中的每一个迭代器i,依序执行
init= init +*i(第一版本)或init=binary_op(init,*i)(第二版本)。
3.3 adjacent_ dfference
//版本1
template <class InputIterator,class OutputIterator>
OutputIterator adjacent_difference(InputIterator first, InputIterator last,OutPutIterator result){
if(first == last) return result;
*result=*first;//首先记录第一个元素
return _adjacent_difference(first, last,result,value_type(first));
//侯捷认为(并经实证),不需像上行那样传递调用,可改用以下写法(整个函数):
// if (first== last) return result;
// *result= *first;
// iterator_traits<InputIterator>::value_type value= *first;
// while (++first != last)( //走过整个区间
// ... 以下同__adjacent_difference()的对应内容
//这样的观念和做法,适用于本文件所有函数,以后不在叙述
}
template <class InputIterator, class OutputIterator, class T>
OutputIterator __adjacent_difference(InputIterator first, InputIterator last,OutputIterator result,T*){
T value = *first;
while(++first !=last){
T tmp = *first;
*++result = tmp-value;//将相邻两元素的差额(后-前),赋值给目的端
value = tmp;
}
return ++result;
}
//版本2
template <class InputIterator,class OutputIterator,class BinaryOperation>
OutputIterator adjacent_difference(InputIterator first, InputIterator last,OutputIterator result,BinaryOperation bianry_op){
if(first == last) return result;
*result = *first;//首先记录第一个元素
return __adjacent_difference(first,last,reuslt,value_type(first),binary_op);
}
template<class InputIterator,class OutputIterator,class T,class BinaryOperation>
OutputIterator __adjacent_difference(InputIterator first,InputIterator last,OutputIterator result,T*,BinaryOperation binary_op){
T value = *first;
while(++first !=last){
//走过整个区间
T tmp = *first;
*++result = binary_op(tmp,value);//将相邻两元素结果,赋值给目的端
value = tmp;
}
return ++result;
}
算法adjacent_difference用来计算[first,last)中相邻元素的差额。也就是说,它将*first赋值给*result,并针对[first+1,last)内的每个迭代器i,将*i-*(i-1)之值赋值给*(result+(i-first))。
注意,你可以采用就地(in place)运算方式,也就是令result等于first 。是的,在这种情况下它是一个质变算法(mutating algorithm)。
- “储存第一元素之值,然后储存后继元素之差值”这种做法很有用,因为这么一来便有足够的信息可以重建输入区间的原始内容。
- 如果加法与减法的定义一如常规定义,那么adjacent_difference与partial_surn(稍后介绍)互为逆运算。
- 这意思是,如果对区间值1,2,3,4,5执行adjacent_difference,获得结果为 1,1,1,1,1 再对此结果执行partial_surn,便会获得原始区间值1,2,3,4,5。
- 第一版本使用operator-来计算差额,第二版本采用外界提供的二元仿函数。 第一个版本针对[first+1,last)中的每个迭代器i,将
*i-*(i-1)赋值给*(result+(i-first)),第二个版本则是将binary_op(*i,* (i-1))的运算结 果赋值给*(result+(i-first))。
3.4 inner_product
//版本1
template<class InputIterator1,class InputIterator2,class T>
T inner_product(InputIterator1 first1,InputIterator1,last1,InputIterator2 first2,T,init){
//以第一序列之元素个数为据,将两个序列都走一遍
for( ; first1 !=last1;++first1,++first2)
init = init+(*first1 * *first);//执行两个序列的一般内积
return init;
}
//版本2
template <class InputIterator1, class InputIterator2, class T,
class BinaryOperation1, class BinaryOperation2>
T inner_product(InputIterator1 first1, InputIterator1 last1, InputIterator2 first2, T init, BinaryOperation1 binary_op1,BinaryOperation2 binary_op2){
//以第一序列之元素个数为据,将两个序列都走一遍
for(;first1 !=last1;++first1,++first2)
//以外界提供的仿函数来取代第一版本的operator*和operator+
init = binary_op1(init,binary_op2(*first1,*first2));
return init;
}
- 算法inner_product能够计算[first1, last1)和[first2, first2 + (last1 - first1))的一般内积(generalized inner product)。
- 注意, 你一定得提供初值init。 这么做的原因之一是当[first,last)为空时,仍可获得一个明确 定义的结果。
- 如果你想计算两个vectors的一般内积, 应该将init设为0。
- 第一个版本会将两个区间的内积结果加上init 。也就是说, 先将结果初始化为init, 然后针对[firstl,last1)的每一个迭代器i,由头至尾依序执行
result = result + (*i)* *(first2+(i-first1))。
第二版本与第一 版本的唯一差异是以外界提供之仿函数来取代operator+ 和operator。就是说,首先将结果初始化为init, 然后针对[firstl, last1) 的每一个迭代器 i, 由头至尾依序执行 result = binary_op1(result, binary_op2(*i, *(first2+(i-first1)))。
式中所用的二元仿函数不必满足交换律(commutative)和结合律(associative)。inner_product所有运算行为的顺序都有明确设定。
3.5 partial_sum
//版本1
template <class InputIterator,class OutputIterator>
OutputIterator partial_sum(InputIterator first,InputIterator last,OutputIterator result){
if(first == last)return result;
*result = *first;
return __partial_sum(first,last,result,value_type(first));
}
template <class InputIterator,class OutputInterator,class T>
OutputIterator __partial_sum(InputIterator first,InputIterator last,OutputIterator result,T*){
T value = *first;
while(++fitst !=last){
value = value+*first;//前n个元素的总和
*result = value;//指定给目的端
}
return ++result;
}
//版本2
template<class InputIterator,class OutputIterator,class BinaryOperation>
OutputIterator partial_sum(InputIterator first,InputIterator last,OutputIterator,Binaryeratorion binary_op){
if(first == last)return result;
*result = *first;
return __partial_sum(first,last,reuslt,value_type(first),binary_op);
}
template <class InputIterator,class OutputIterator,class T,
class BinaryOperation>
OutputIterator __partial_sum(InputIterator first,InputIterator last,OutputIterator result,T*,BinaryOperation binary_op(){
T value = *first;
while(++first !=last){
value = binary_op(value,*first);//前n个元素的总计
*++result = value;//指定给目的端
}
return ++reuslt;
}
- 算法partial_sum用来计算局部总和。它会将
*first赋值给*result, 将*(first+1)和*(result+1)的和赋值给*(result+1),依此类推。 - 注意,result可以等于first,这使我们得以完成就地(in place)计算。在这种情况下它是一个质变算法(mutating algorithm)。
- 运算中的总和首先初始为
*first, 然后赋值给*result。 - 对于 [first+1,last)中每个迭代器i,从头至尾依序执行
sum=sum+*i(第一版本)或sum=binary_op(sum, *i)(第二版本),然后再将sum赋值给*(result +(i -first))。 - 此式所用之二元仿函数不必满足交换律(commutative)和结合 律(associative)。所有运算行为的顺序都有明确设定。
- 本算法返回输出区间的最尾端位置:result+(last-first)。
如果加法与减法的定义一如常规定义,那么partial_sum与先前介绍过的adjacent_difference互为逆运算。这里的意思是,如果对区间值1,2,3,4,5执行partial_sum,获得结果为1,3,6,10,15,再对此结果执行adjacent_difference, 便会获得原始区间值1,2,3,4,5。
3.6 power
这个算法由SGI专属,并不在STL标准之列。它用来计算某数的n幕次方。 这里所谓的n幕次是指自己对自已进行某种运算,达n次。运算类型可由外界指定; 如果指定为乘法,那就是乘幕。
//版本1,乘幂
template<class T,class Integer>
inline T power(T x,Integer n){
return power(x,n,multiples<T>());//指定运算型式为乘法
}
//版本二,幕次方。如果指定为乘法运算,则当n>= 0时返回x^n
//注意,"MonoidOperation"必须满足结合(associative)
// 但不需满足交换律(commutative)
template <class T, class Integer, class MonoidOperation>
T power(T x, Integer n, MonoidOperation op) {
if(n ==0)
return identity_element(op);//取出“证同元素"identity_element;证同元素见7.3节
else{
while((n & 1) == 0){
n>>=1;
x = op(x,x);
}
T result = x;
n >>=1;
while(n !=0){
x = op(x,x);
if((n & 1) !=0)
reuslt = op(result,x);
n>>=1;
}
return result;
}
}
3.7 itoa
这个算法由SGI专属,并不在STL标准之列。它用来设定某个区间的内容,使其内的每一个元素从指定的value值开始,呈现递增状态。它改变了区间内容,所以是一种质变算法(mutating algorithm)。
//侯捷:iota是什么的缩写?
//函数意义:在[first,last)区间内填入value,value+1, value+2 ...
template <class ForwardIterator, class T>
void iota(ForwarIterator first, ForwardIterator last, T value) {
while(first !=last) *frist++ = value++;
}
4.基本算法(stl_algobase)
STL标准规格中并没有区分基本算法或复杂算法,然而SGI却把常用的一些算法定义于<stl_algobase.h>之中,其它算法定义于<stl_algo.h>如中。以下列举这些所谓的基本算法。
4.1 运用实例
以下程序展示本节介绍的每一个算法的用途(但不含copy,copy_backward的用法,这两者另有范例程序)。本例使用for_each搭配一个自制的仿函数(functor) display作为输出工具,关于仿函数,第7章会深入介绍它,目前请想象它是一个有着函数行径(也就是说,会被function call操作符调用起来)的东西。至于for_each,将在6.7介绍,目前请想象它是一个可以将整个指定区间遍历一遍的循环:
#include<algorithm>
#include<vector>
#include<functional>
#include<iostream>
#include<iterator>
#include<string>
using namespace std;
template <class T>
struct dispaly{
void operator(){
const T& x)const
{
cout<<x<<' ';}
};
int main()
{
int ia[9] = {
0,1,2,3,4,5,6,7,8};
vector<int> iv1(ia,ia+9);
vector<int> iv2(ia,ia+9);
//{0,1,2,3,4} v.s {0,1,2,3,4,5,6,7,8};
cout<<*(mismatch(iv1.begin(),iv1.end(),iv2.begin()).first);//?
cout<<*(mismatch(iv1.begin(),iv1.end(),iv2.begin()).second);//5
//以上判断两个区间的第一个不匹配点。返回一个由两个迭代器组成的pair,
//其中第一个迭代器指向第一区间的不匹配点,第二个迭代器指向第二区间的不匹配点
//上述写法很危险,应该先判断迭代器是否不等于容器的end(),然后才可以做输出操作
//如果两个序列在[first,last)区间内相等,equal()返回true
//如果第二序列的元素比较多,多出来的元素不予考虑
cout << equal(iv1.begin(), iv1.end(), iv2.begin()); // 1, true
cout<<equal(iv1.begin(),iv.end(),,&ia[3]);//0,false
//{0,1,2,3,4}不等于{3,4,5,6,7}
cout<<equal(iv1.begin(),iv1.end(),&ia[3],less<int>());//1
//{0,1,2,3,4}小于{3,4,5,6,7}
fill(iv1.begin(),iv1.end(),9);//区间区间内全部填9
for_each(iv1.begin(),iv1.end(),dispaly<int>());//9 9 9 9 9
fill_in(iv1.begin(),3,7);//从迭代器所指位置开始,填3个7
for_each(iv1.begin(),iv1.end(),dispaly<int>());//7 7 7 9 9
vector<int>::iterator ite1 = iv1.begin();//指向7
vector<int>::iterator ite2 =ite1;
advance(ite2,3);//指向9
iter_swap(ite1,ite2);//将两个迭代器所指元素对调
cout<<*ite1<<' '<<*ite2<<endl;//9 7
for_each(iv1.begin(),iv1.end(),dispaly<int>());//9 7 7 7 9
//以下取两值之最大
cout<<max(*ite1,*ite2)<<endl;//9
//以下取两值之最小
cout<<min(*ite1,*ite2)<<endl;//7
//千万不要错写成以下那样。那意思是,取两个迭代器(本身)之大者(或小者),
//然后再打印其所指之值。注意,迭代器本身的大小,对用户没有意义
cout<<*max(ite1,ite2)<<endl;//7
cout<<*min(ite1,ite2)<<endl;//9
//此刻状态,iv1:{9 7 7 7 9},iv2:{0 1 2 3 4 5 6 7 8}
swap(*iv1.begin(),*iv2.begin());//将两数值对调
for_each(iv1.begin(),iv1.end(), display<int>()); //0 7 7 7 9
for_each(iv2. begin(),iv2.end(), display<int>()); //9 1 2 3 4 5 6 7 8
//准备两个字符串数组
struct stra1[]={
"Jamie","JJHou","Jason"};
struct stra2[]={
"Jamie","JJhou","Jerry"};
cout<<lexicographical_compare(stra1,stra1+2,stra2+2);
//1 (stra1小于stra2)
cout<<lexicographoical_compare(stra1,stra1+2,stra2,stra2+@,greate<string>());
//0 (stra1不大于stra2)
}
4.2 equal,fill,fill_n,iter_swap,lexicogrphical_compare,max,min,mismatch,swap
这一小节列出定义于<stl_algobase.h>头文件中的所有算法, copy () , copy _backward ()除外,因为这两个函数复杂许多,在效率方面有诸多 考虑,我把它们安排在另外的小节。
①.equal
如果两个序列在[first,last)区间内相等,equal()返回true。如果第二序列的元素比较多,多出来的元素不予考虑。因此,如果我们希望保证两个序列完全相等,必须先判断其元素个数是否相同:
if(vec1.size() == vec2.size() && equal(vec1.begin(),vec1.end(),vec2.begin());
抑或使用容器所提供的equality操作符,例如vec1==vec2。如果第二序列的元素比第一序列少,这个算法内部进行迭代行为时,会超越序列的尾端,造成不可预测的结果。第一版本缺省采用元素型别所提供的equality操作符来进行大小比较,第二版本允许我们指定防函数pred作为比较依据。
template<class InputIterator1,class InputIterator2>
inline bool equal(InputIterator1 first,InputIterator1 last1,InputIterator2 first){
//以下,将序列一走一遍,序列二亦步亦趋
//如果序列一的元素个数多过序列2的元素个数,就糟糕了
for( ;first1 !=last1;++first1,++first2)
if(*first1 =*first2)//只要对应元素不相等
return false;//就结束并返回false
return true;//至此,全部相等,返回true
}
template<class InputIterator1,class InputIterator2,class BinaryPredicate>
inline bool equal(InputIterator1 first1,InputIterator1 last,InputIterator2 first2,BinaryPredicate binary_pred){
for( ; first1 !=last1;++first1,++first2)
if(!binary_pred(*first1,*fitst2))
return false;
return true;
}
②.fill
将[first,last)内的所有元素改填新值。
template<class ForwardIterator,class T>
void fill(ForwardIterator first,ForwardIterator last,const T& value){
for( ;first !=last;++first)//迭代器走过整个区间
*first = value;//设定新值
}
③.fill_n
将[first,last)内的前n个元素改填新值,返回的迭代器指向被填入的1最后一个元素的下一个位置。
template<class OutputIterator,class Size,class T>
OutputIterator fill_n(OutputIterator first,Size n,const T& value){
for( ;n>0;--n;++first)//经过n个元素
*first = value;
reurn first;
}
如果n超越容器的现有大小,会造成声明结果?例如:
int ia[3] = {
0,1,2};
vecctor<int> iv(ia,ia+3);
fill_n(iv.begin(),5,7);
从fill_n的源代码知道,由于每次迭代器进行的是assignment操作,是一种覆写(overwirte)操作,所以一旦操作区间超越了容器大小,就会造成不可预期的结果。解决办法之一是,利用inserter()产生一个具有插入(insert)而非覆写(overwirte)能力的迭代器。insert()可产生一个用来修饰迭代器的配接器(iterator adapter),用法如下:
int ia[3] = {
0,1,2};
vector<int> iv(ia,ia+3);//0 1 2
fill_n(inserter(iv,iv.begin()),5,7);//7 7 7 7 7 0 1
④.iter_swap
将两个ForwardIterators所指的对象对调,如下图:
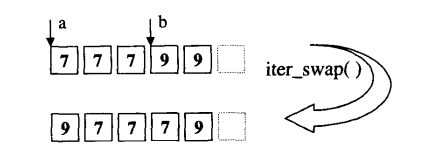
template <class ForwardIterator1, class ForwardIterator2>
inline void iter_swap(ForwardIterator1 a, ForwardIterator2 b) {
_iter_swap(a, b, value_type(a)); //注意第三参数的型别!
}
template <Class ForwardIiterator1, class ForwardIterator2,class T>
inline void __iter_swap(ForwardIterator a,ForwardIterator2 b,T*){
T tmp = *a;
*a = *b;
*b = tmp;
}
- iter_swap ()是"迭代器之value type"派上用场的一个好例子。是的,该函数必须知道迭代器的value type, 才能够据此声明一个对象,用来暂时存放迭代器所指对象。
- 为此,上述源代码特别设计了一个双层构造,第一层调用第二层,并多出 一个额外的参数value_type(a)。
- 么一来,第二层就有value type可以用了。乍见之下你可能会对这个额外参数在调用端和接受端的型别感到讶异,调用端是 value_type(a),接受端却是
T*。
只要找出value_type()的定义瞧瞧,就一点也不奇怪了:
//以下定义于<stl_iterator.h>
template <class Iterator>
inline typename iterator_traits<Iterator>::value_type*
value_type(const Iterator&) {
return static_cast<typename irterator_traits<Iterator>::value_type*>(0);
}
这种双层构造在SGI STL源代码中十分普通,其实并非必要,直接这么写:
template<class ForwardIterator1, class ForwardIterator2>
inline void iter_swap(ForwardIterator1 a, ForwardIterator2 b) {
typename iterator_traits<Forwardator1>::value_type
tmp = *a;
*a = *b;
*b= tmp;
}
⑤.lexicographical_compare
以”字典排列方式”对两个序列[first1,last1)和[first2,last2)进行比较。比较操作针对两序列中的对应位置上的元素进行,并持续直到(1)某一组对 应元素彼此不相等;(2)同时到达last1和last2(当两序列的大小相同);(3)到达last1或last2(当两序列的大小不同)。
当这个函数在对应位置上发现第一组不相等的元素时,有下列几种可能:
- 如果第一序列的元素较小,返回true。否则返回false。
- 如果到达last1而尚未到达last2,返回true。
- 如果到达last2而尚未到达last1,返回false。
- 如果同时到达last1和last2(换句话说所有元素都匹配),返回false;
也就是说,第一序列以字典排列方式(lexicographically)而言不小于第二序列。 举个例子,给予以下两个序列:
string stra1 [] = ("Jamie", "JJHou", "Jason" } ;
string stra2 [] = ("Jamie", "JJhou", "Jerry" } ;
这个算法面对第一组元素对,判断其为相等,但面对第二组元素对,判断其为不等。就字符串而言,“JJHou"小于"JJhou”,因为‘H’在字典排列次序上小于 ‘h’ (注意,并非“大写”字母就比较“大”,不信的话看看你的字典。事实卜 大写字母的ASCII码比小写字母的ASCII码小)。于是这个算法在第二组“元素对 "停了下来, 不再比较第三组 “元素对“ 。比较结果是true。
第二版本允许你指定一个仿函数comp作为比较操作之用,取代元素型别所提供的less-than (小于)操作符。
template <class InputIterator1, class InputIterator2>
bool lexicographical_compare(InputIterator1 first1, InputIterator1 last1,InputIterator2 first2,InputIterator2 last2){
//以下, 任何一个序列到达尾端,就结束。 否则两序列就相应元素一一进行比对
for ( ;first1 != last1 && first2 != last2; ++first1, ++first2) {
if (*first1< *first2)//第一序列元素值小于第二序列的相应元素值
return true;
if (*first2 < *first1) //第二序列元素值小于第一序列的相应元素值
return false;
//如果不符合以上两条件, 表示两值相等, 那就进行下一组相应元素值的比对
}
//进行到这里, 如果第一序列到达尾端而第二序列尚有余额, 那么第一序列小于第二序列
return first1 == lastl && first2 ! = last2;
}
ternplate <class InputIterator1, class InputIterator2, class Cornpare>
bool lexicographical_compare(InputIterator1 first1, InputIteratorl last1,InputIterator2 first2,InputIterator2 last2,Compare comp){
for ( ;first1 !=last1 && first2 !=last2;++first1,++first2){
if(comp(*first1,*first2))
return true;
if(comp(*first2,*first1))
return false;
}
return first1 == last1 && first2 1+last2;
}
为了增进效率,SGI还设计了一个特化版本,用于原生指针const unsigned char*:
inline bool
lexicographical_compare(const usingned char* first1,const usingned char* last1,const usingned char* first2,const usingned char* last2)
{
const size_t len1= last1-first1;//第一序列长度
const size_t len2 = last2-first2; //第二序列长度
//先比较相同长度的一段。memcmp()速度极快
const int result=memcmp(first1,first2,min(len1, len2)); //如果不相上下,则长度较长者被视为比较大
return result != 0? result< 0 : lenl < len2;
}
其中memcmp()是C标准函数,正是以unsigned char的方式来比较两序列中对应的每一个bytes。除了这个版本,SGI还提供另一个特化版本,用于 原生指针const char*, 形式同上,就不列出其源代码了。
⑥.max
取出两个对象中较大的值,有两个版本,版本一使用对象型别T所提供的greater-than操作符来判断大小,版本二使用仿函数comp来判断大小:
template<class T>
inline const T& max(const T& a,const T& b){
return a<b?b:a;
}
template <class T,class Compare>
inline const T& max(const T& a,const T& b,Compare comp){
return comp(a,b)?b:a;//由comp决定“大小比较”标准
}
⑦.min
取两个对象中的较小值。有两个版本,版本一使用对象型别T所提供的 less-than操作符来判断大小,版本二使用仿函数comp来判断大小。
template <class T>
inline const T& min 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2312
2312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









