






Bagging模型(随机森林)
Bagging:训练多个分类器取平均
f
(
x
)
=
1
/
M
∑
m
=
1
M
f
m
(
x
)
f(x)=1/M\sum^M_{m=1}{f_m(x)}
f(x)=1/M∑m=1Mfm(x)
全称: bootstrap aggregation(说白了就是并行训练一堆分类器)
最典型的代表就是随机森林,现在Bagging模型基本上也是随机森林。
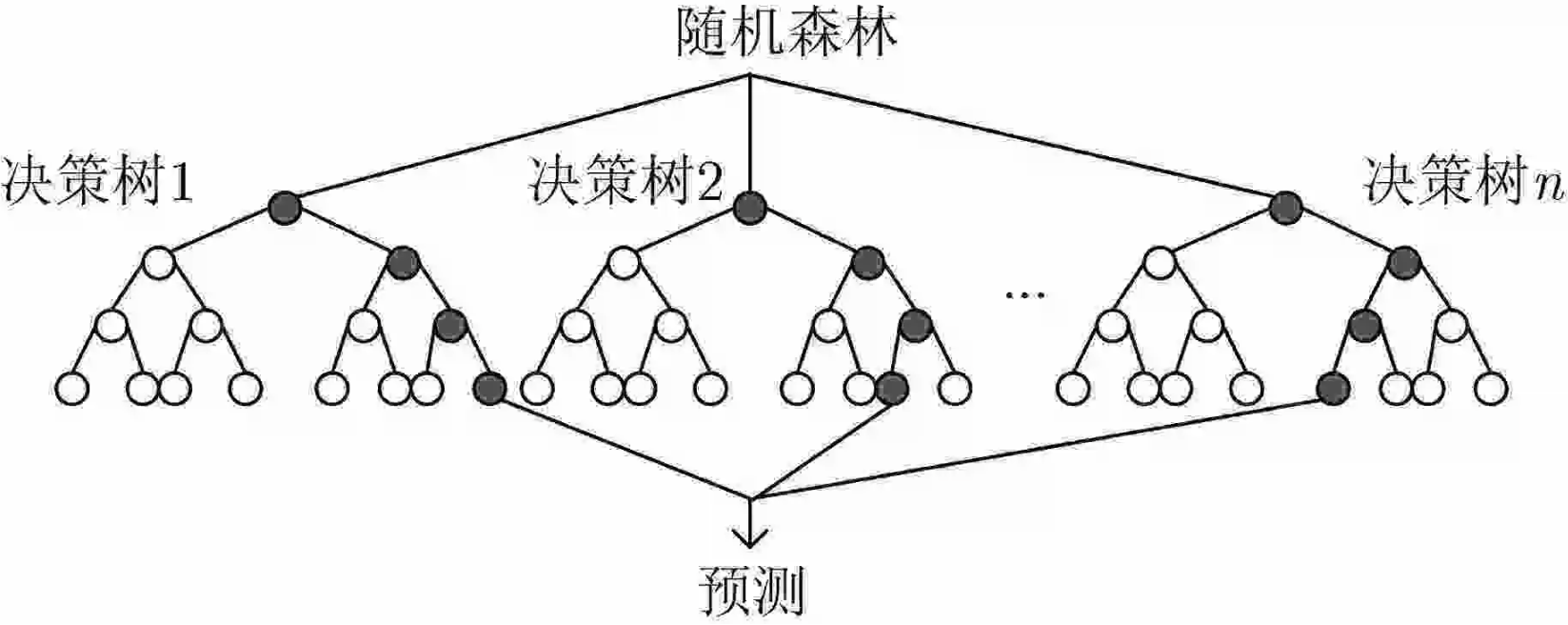
随机:数据采样随机,每棵树只用部分数据;数据有多个特征(属性)组成,每棵树随机选择部分特征。随机是为了使得每个分类器拥有明显差异性。
森林:很多个决策树并行放在一起
如何对所有树选择最终结果?分类的话可以采取少数服从多数,回归的话可以采用取平均值。
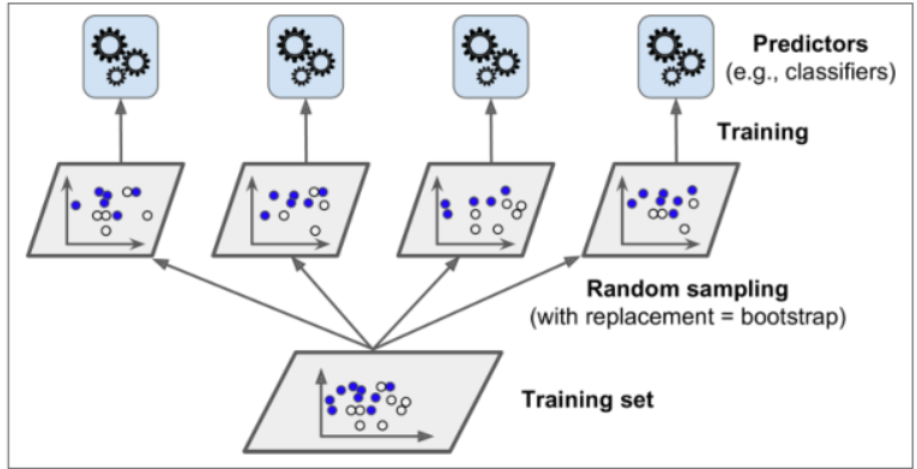
Bagging策略
首先对训练数据集进行多次采样(有放回的取样),保证每次得到的采样每份数据都是不同的(但是每份数据里面可能和其他数据有相同)
分别训练多个模型,例如树模型
预测时需得到所有模型结果再进行集成
import numpy as np
import os
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
import warnings
warnings.filterwarnings('ignore')
np.random.seed(42)
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
X,y = make_moons(n_samples=500, noise=0.30, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
plt.plot(X[:,0][y==0],X[:,1][y==0],'yo',alpha = 0.6)
plt.plot(X[:,0][y==0],X[:,1][y==1],'bs',alpha = 0.6)
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
# DecisionTreeClassifier 采用树模型
# n_estimators 500个分类器
# max_samples 每次采样100条数据
# bootstrap = True 有放回的随机采样
bag_clf = BaggingClassifier(DecisionTreeClassifier(),
n_estimators = 500,
max_samples = 100,
bootstrap = True,
n_jobs = -1,
random_state = 42
)
bag_clf.fit(X_train,y_train)
y_pred = bag_clf.predict(X_test)
# Bagging策略的结果
accuracy_score(y_test,y_pred)
结果:0.904
# 不使用Bagging策略,为了对比公平,random_state都为42
tree_clf = DecisionTreeClassifier(random_state = 42)
tree_clf.fit(X_train,y_train)
y_pred_tree = tree_clf.predict(X_test)
accuracy_score(y_test,y_pred_tree)
结果:0.856
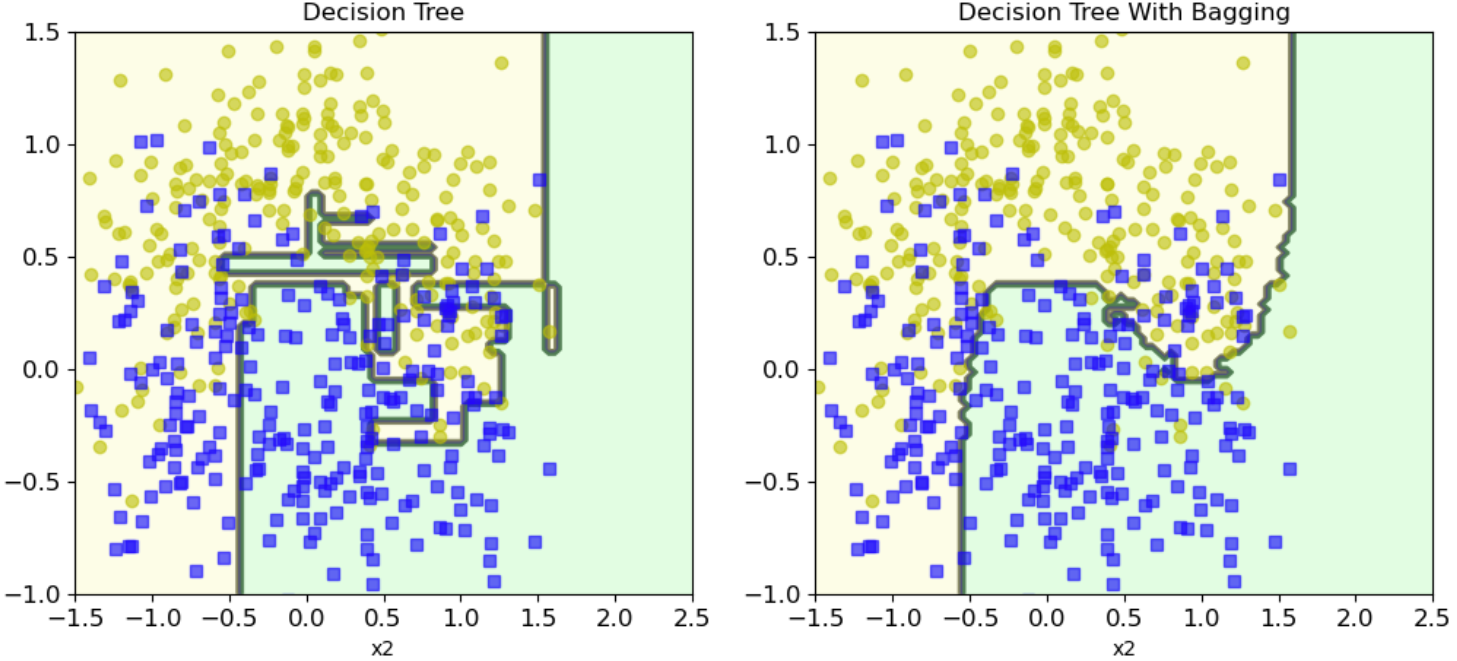
决策边界
集成与传统方法对比
from matplotlib.colors import ListedColormap
def plot_decision_boundary(clf,X,y,axes=[-1.5,2.5,-1,1.5],alpha=0.5,contour =True):
x1s=np.linspace(axes[0],axes[1],100)
x2s=np.linspace(axes[2],axes[3],100)
x1,x2 = np.meshgrid(x1s,x2s)
X_new = np.c_[x1.ravel(),x2.ravel()]
y_pred = clf.predict(X_new).reshape(x1.shape)
custom_cmap = ListedColormap(['#fafab0','#9898ff','#a0faa0'])
plt.contourf(x1,x2,y_pred,cmap = custom_cmap,alpha=0.3)
if contour:
custom_cmap2 = ListedColormap(['#7d7d58','#4c4c7f','#507d50'])
plt.contour(x1,x2,y_pred,cmap = custom_cmap2,alpha=0.8)
plt.plot(X[:,0][y==0],X[:,1][y==0],'yo',alpha = 0.6)
plt.plot(X[:,0][y==0],X[:,1][y==1],'bs',alpha = 0.6)
plt.axis(axes)
plt.xlabel('x1')
plt.xlabel('x2')
plt.figure(figsize = (12,5))
plt.subplot(121)
plot_decision_boundary(tree_clf,X,y)
plt.title('Decision Tree')
plt.subplot(122)
plot_decision_boundary(bag_clf,X,y)
plt.title('Decision Tree With Bagging')
可以看出Bagging的分类结果更加平滑
OOB(Out Of Bag)策略
在Bagging中,假如总共有100条数据,每颗树只随机取80条数据(有放回),那么Out Of Bag的意思就是选择每次剩下20条数据作为验证集。
# oob_score = True 开启oob
bag_clf = BaggingClassifier(DecisionTreeClassifier(),
n_estimators = 500,
max_samples = 100,
bootstrap = True,
n_jobs = -1,
random_state = 42,
oob_score = True
)
bag_clf.fit(X_train,y_train)
print('验证集的结果为:')
bag_clf.oob_score_
验证集的结果为:
0.9253333333333333
y_pred = bag_clf.predict(X_test)
print('测试集的结果为:')
accuracy_score(y_test,y_pred)
测试集的结果为:
0.904
随机森林
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier()
rf_clf.fit(X_train,y_train)
特征重要性:
sklearn中是看每个特征的平均深度
from sklearn.datasets import load_iris
iris = load_iris()
rf_clf = RandomForestClassifier(n_estimators=500,n_jobs=-1)
rf_clf.fit(iris['data'],iris['target'])
for name,score in zip(iris['feature_names'],rf_clf.feature_importances_):
print (name,score)
sepal length (cm) 0.11105536416721994
sepal width (cm) 0.02319505364393038
petal length (cm) 0.44036215067701534
petal width (cm) 0.42538743151183406
Mnist中哪些特征比较重要呢?
# from sklearn.datasets import fetch_mldata
# mnist = fetch_mldata('MNIST original')
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1, cache=True)
rf_clf = RandomForestClassifier(n_estimators=500,n_jobs=-1)
rf_clf.fit(mnist['data'],mnist['target'])

rf_clf.feature_importances_.shape
# (784,)
def plot_digit(data):
# 将一维(784,)的feature_importances_改成二维正方形(28,28)
image = data.reshape(28,28)
plt.imshow(image,cmap=matplotlib.cm.hot)
plt.axis('off')
plot_digit(rf_clf.feature_importances_)
char = plt.colorbar(ticks=[rf_clf.feature_importances_.min(),rf_clf.feature_importances_.max()])
char.ax.set_yticklabels(['Not important','Very important'])

















 6052
6052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











