







目录
1.数据集搭建思路

比如说对于车牌识别,数据集应该都是一些车牌字符比较好
对于汽车识别的话,则是都为汽车的不同角度的图片比较好
并且对于数据集来说,有多通道的,有单通道的,这其中又有很多区别
还有像素高的和像素低的
这些都是要从效率角度去考虑
1.1数据集构成

文档里有很多可以参考的内容
看一下这个类的介绍:
表示Dataset的抽象类
所有数据集都应该子类话,继承这个父类
然后所有的子类都应当重写__len__和__getitem__这两个构造方法
前者提供了数据集的大小,后者支持整数索引,范围从0到len(self)。
1.2搭建数据集
先定义子类,继承torch文档规定的父类

然后定义init构造方法,用来传入标签值
标签值的目的是让数据跟识别的数值对应

以下是前处理后的数据(可以理解为网络的输入)
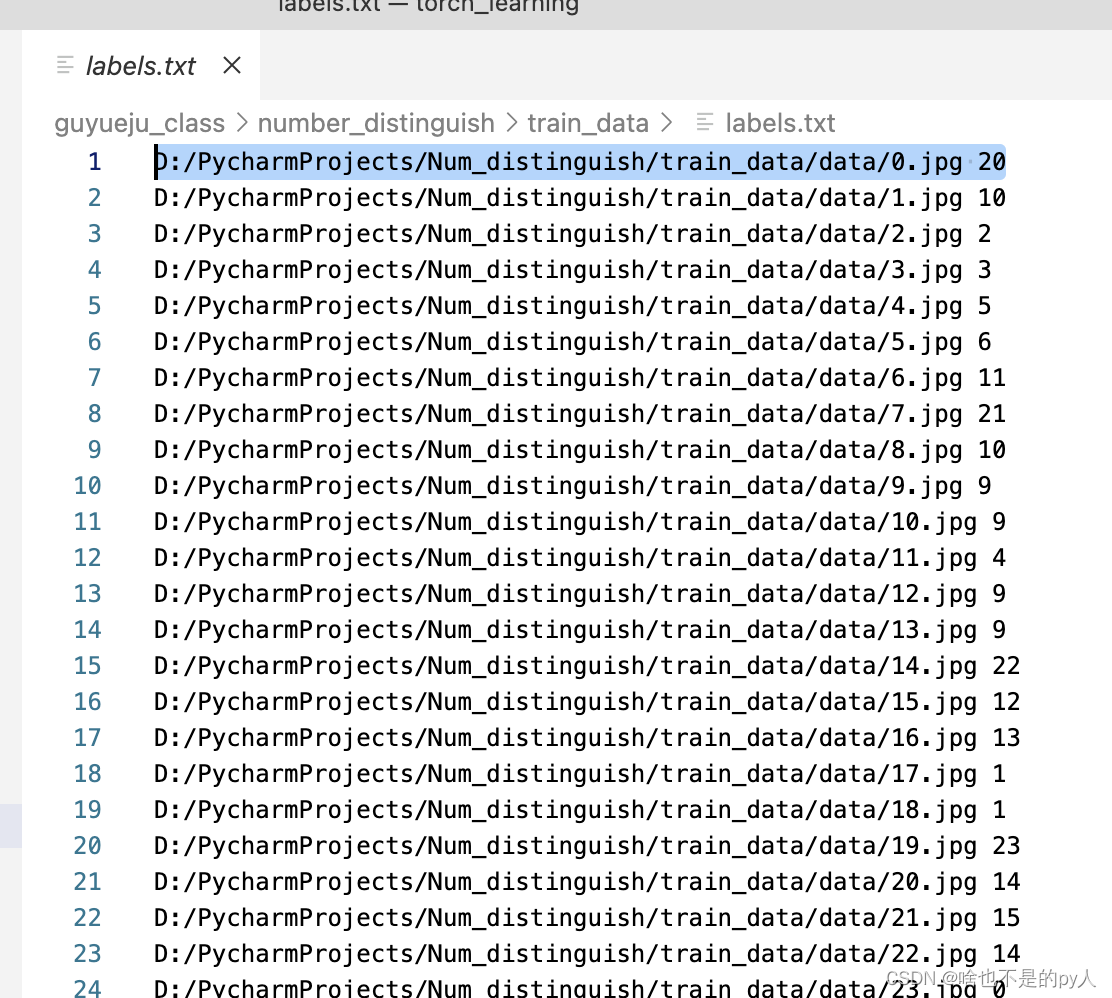
 label.txt的作用就是把图片和标签对应起来,可以理解为图片为x,标签为y
label.txt的作用就是把图片和标签对应起来,可以理解为图片为x,标签为y
让x进入网络得到预测值尽量跟y接近或者一样
就是网络的功能
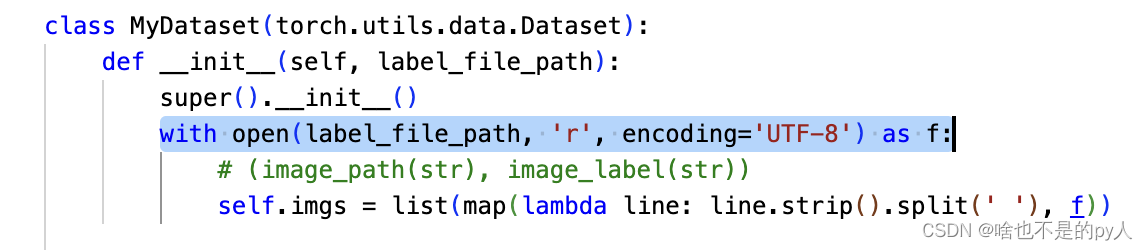
 以下是各label的实际意义(该文件相当于注释功能)
以下是各label的实际意义(该文件相当于注释功能)

然后是打开标签文件
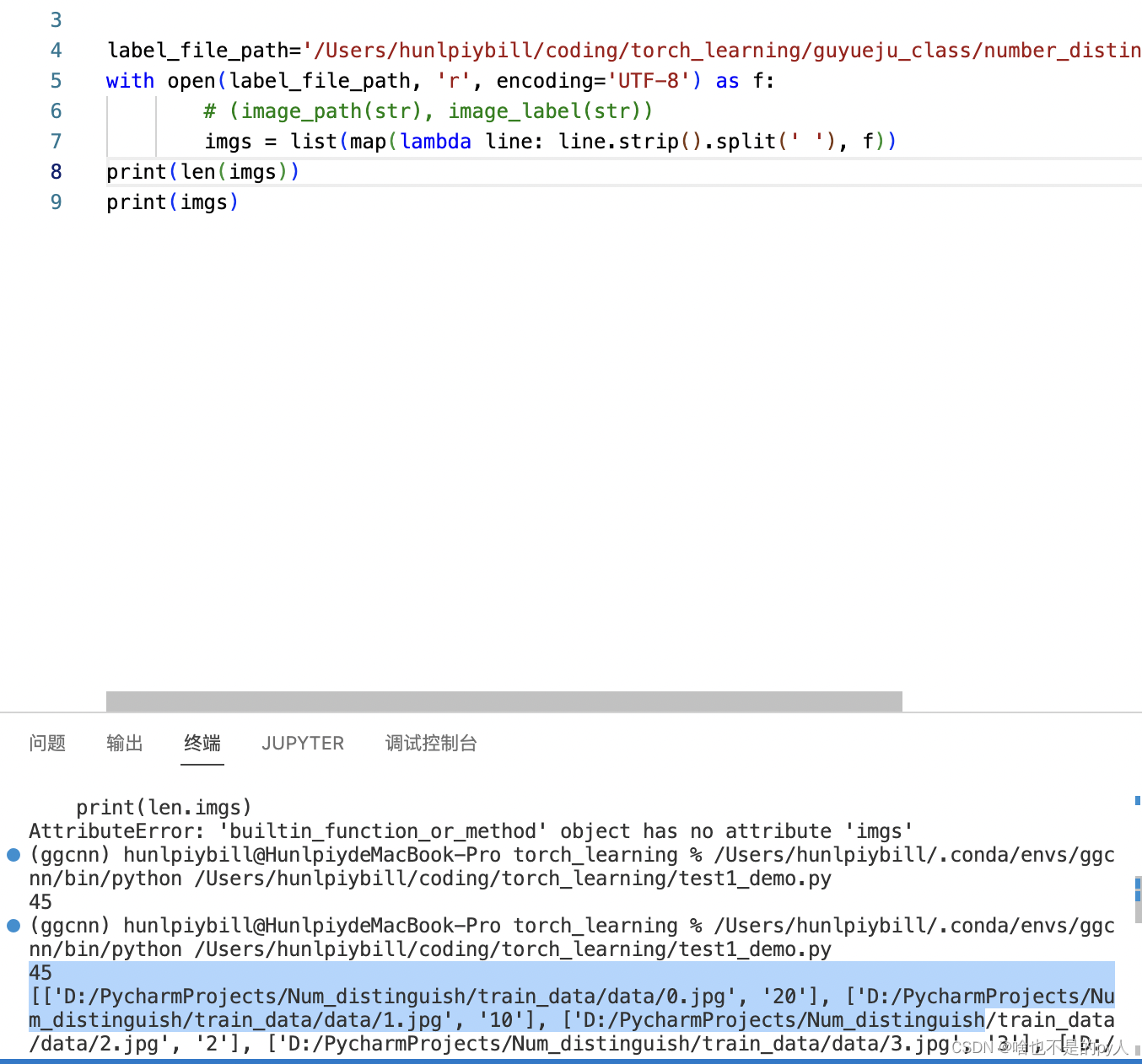
 然后读取到的带空格的数据
然后读取到的带空格的数据
空格前的数据作为输入图片也就是x
空格后的数据作为ground truth 也就是y

1.2.1__getitem__
这个构造方法是用来获得索引的
比如说当index是0的时候可以得到第一个数据的传入

里面有x和y

然后把图片和label处理成可以计算的数据
然后再返回

此处图片是被转换成了tensor
1.2.2__len__
返回数据集的长度

读取的是列表,是完整的所有数据
1.3加载数据集
先给路径
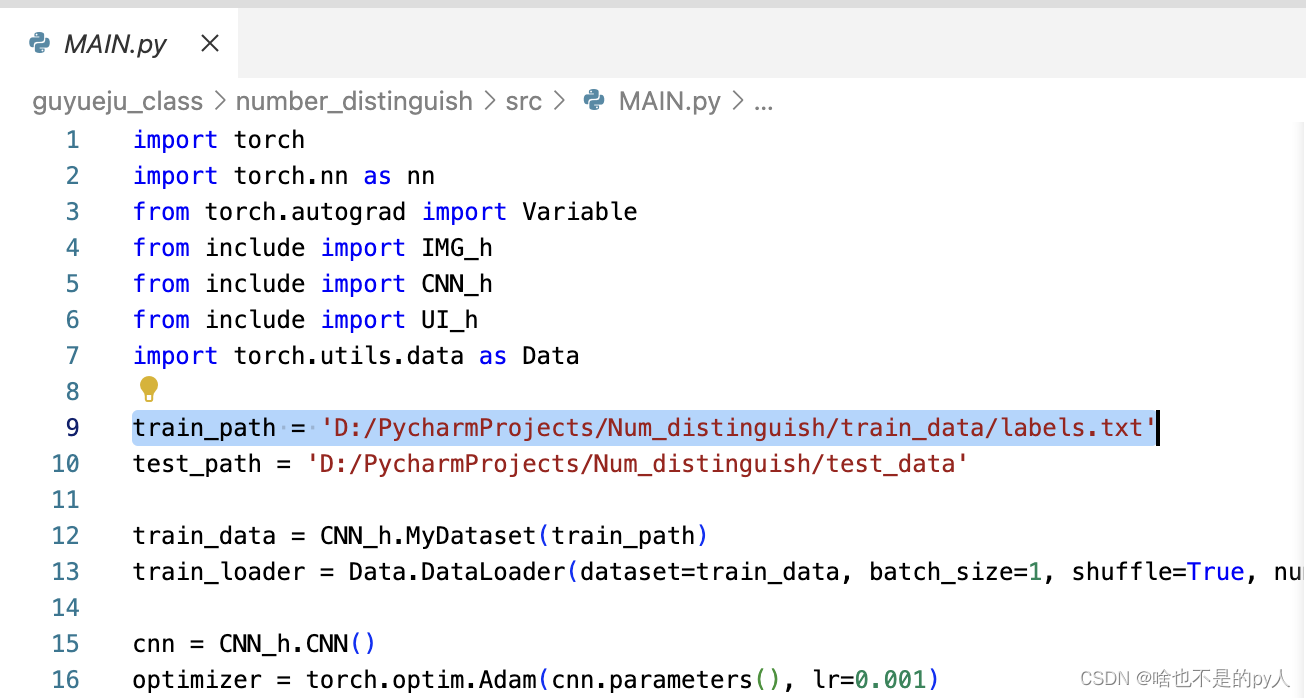
然后实例化数据集
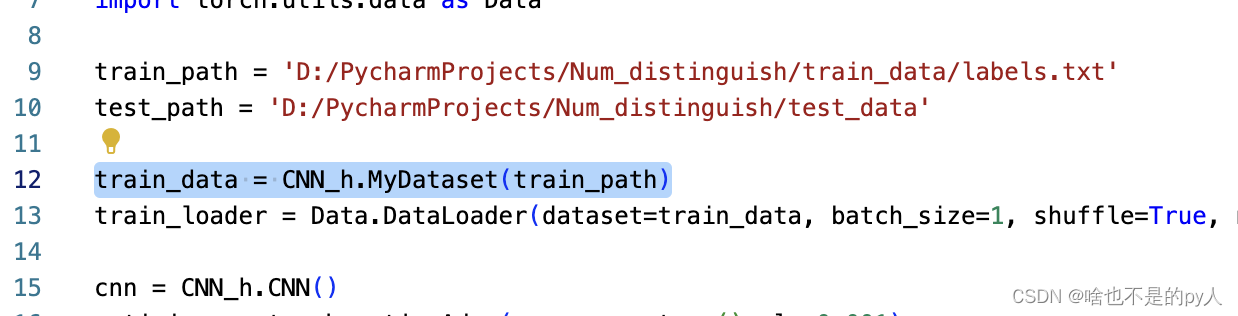
然后调用data封装的方法加载数据集
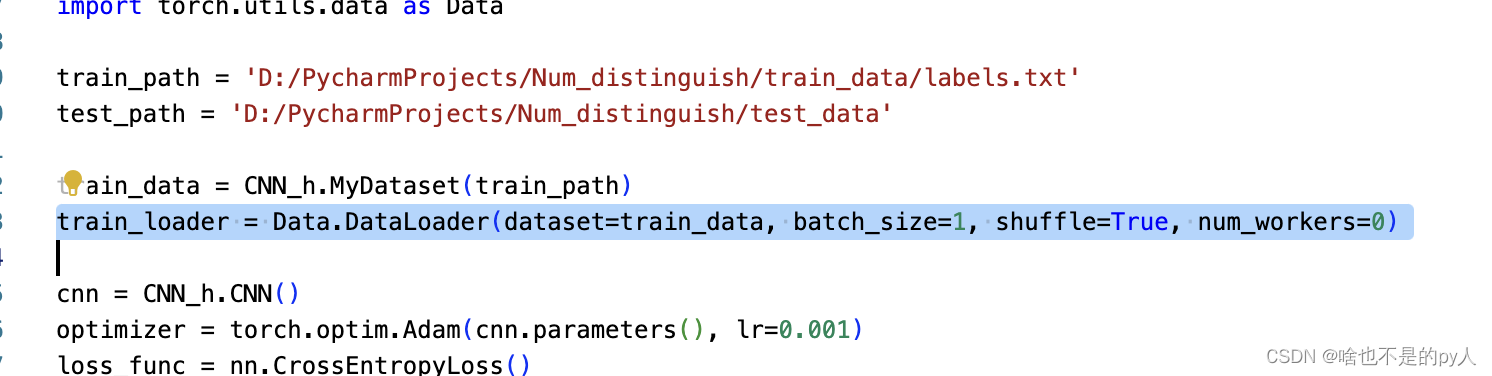
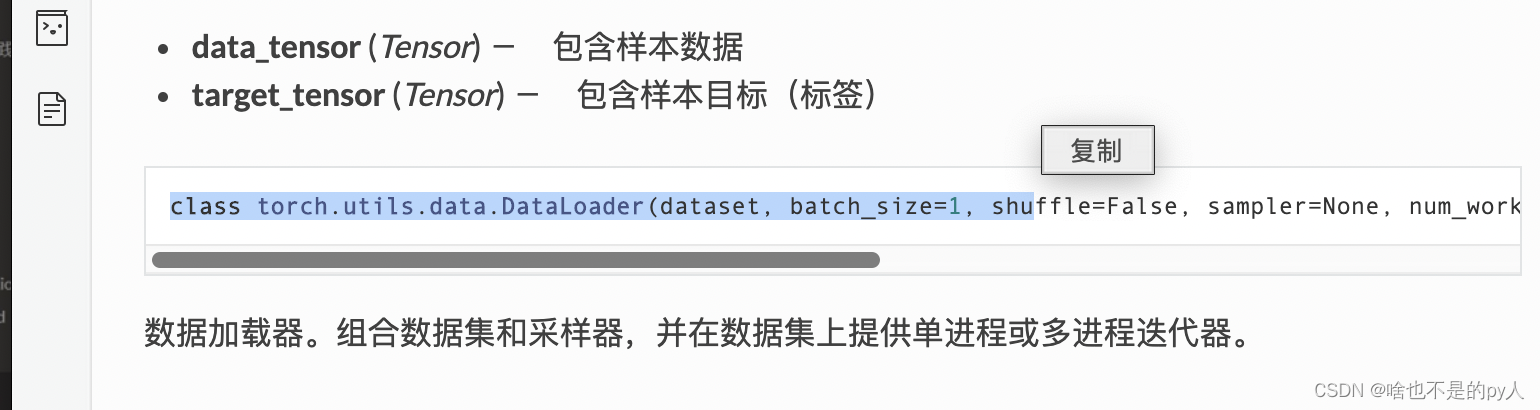
具体的在手册里讲的很详细
torch.utils.data - PyTorch中文文档
2.代码教程
对应下载好代码
这个是车牌的图像处理部分:
主要是对车牌先进行色域识别,再把各个字符切割,然后存储,然后作为数据集
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









