







目录
基于深度学习的平面抓取算法
二指机械手抓取模型
 标红字体为任务场景
标红字体为任务场景

平面抓取:
使机械抓手在x和y轴的转角设置为已知的定值(其实就是设置为初始值)
即roll和pitch为定值
那么剩下的就是获取抓取点的x,y值
以及沿着z轴方向的值
这样就是完整的抓取位姿
也是神经网络实际输出的值
平面抓取第一种模型

x,y,z是获取的抓取点位姿
表示沿着z轴的转角
w表示机械手张开的角度
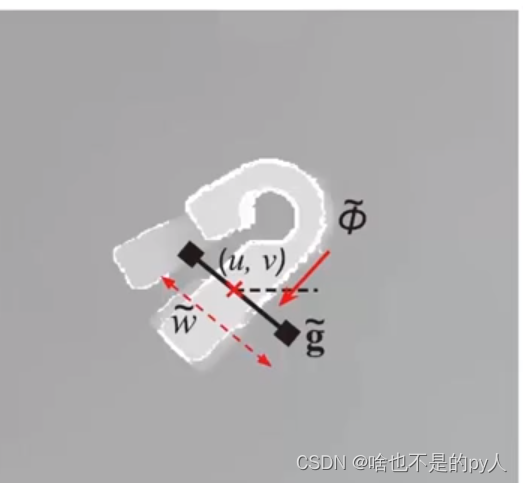
这个就是一个完整的抓取位姿图
z可以直接输出(抓取高度)
ggcnn实际上输入深度图输出此抓取位姿图

dex-net
实际上就是固定抓取宽度w
对深度图采样很多x,y,z,
然后把采样结果输入网络
网络输出很多个采样结果的预测
选取置信度最高的作为输出结果
平面抓取第二种模型

x,y是像素里的坐标
表示旋转角
n表示张开宽度
m表示抓取位置的集合或者是夹爪尺寸
但是第二种抓取模型有很多问题
所以现在一般先进的方法都不用了
平面抓取检测与神经网络结构
端到端
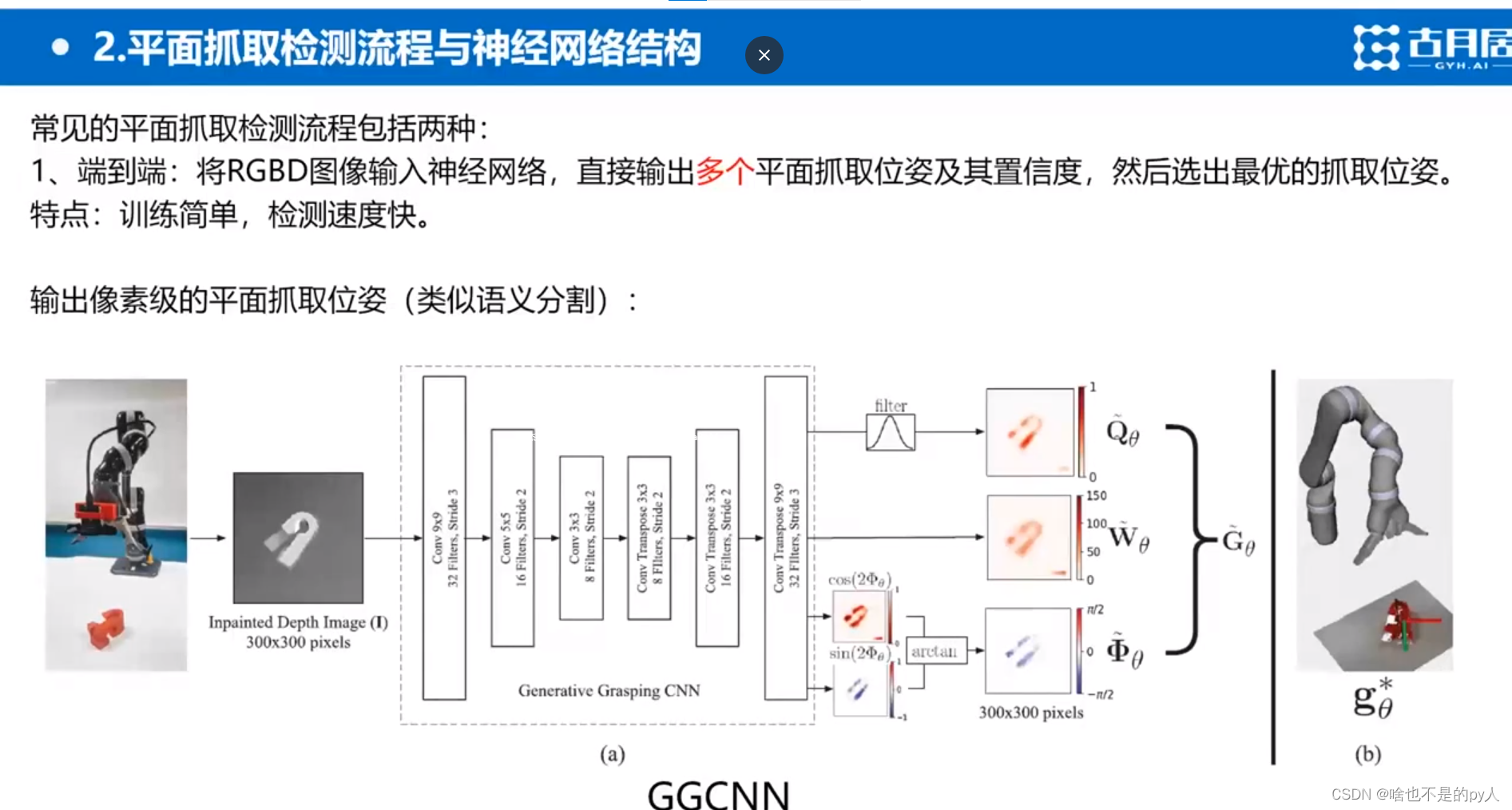
 代表对应抓取位置的成功率
代表对应抓取位置的成功率
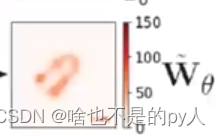 代表对应位置的抓取宽度
代表对应位置的抓取宽度
 代表对应位置的绕z轴旋转角度
代表对应位置的绕z轴旋转角度
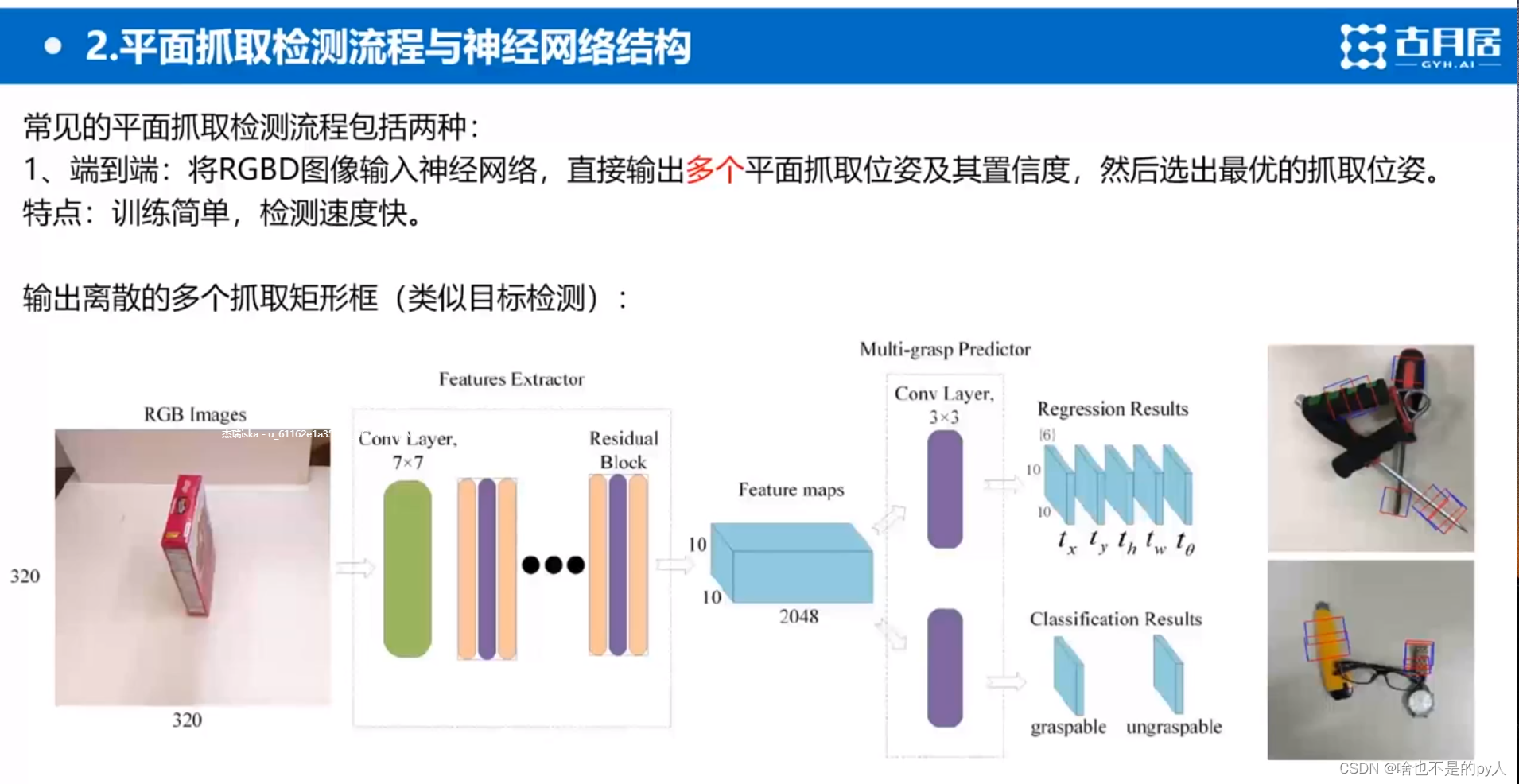
其实这个跟Fast—RCNN很像
因为也是输出很多框
 tx,ty。。。都是框的要素,坐标长宽,旋转角度
tx,ty。。。都是框的要素,坐标长宽,旋转角度
 graspable+ungraspable=1
graspable+ungraspable=1
因为是端到端的,所以其实只需要填入数据,贴上标签,得到结果
先采样后评估
这是Dex-net的方案
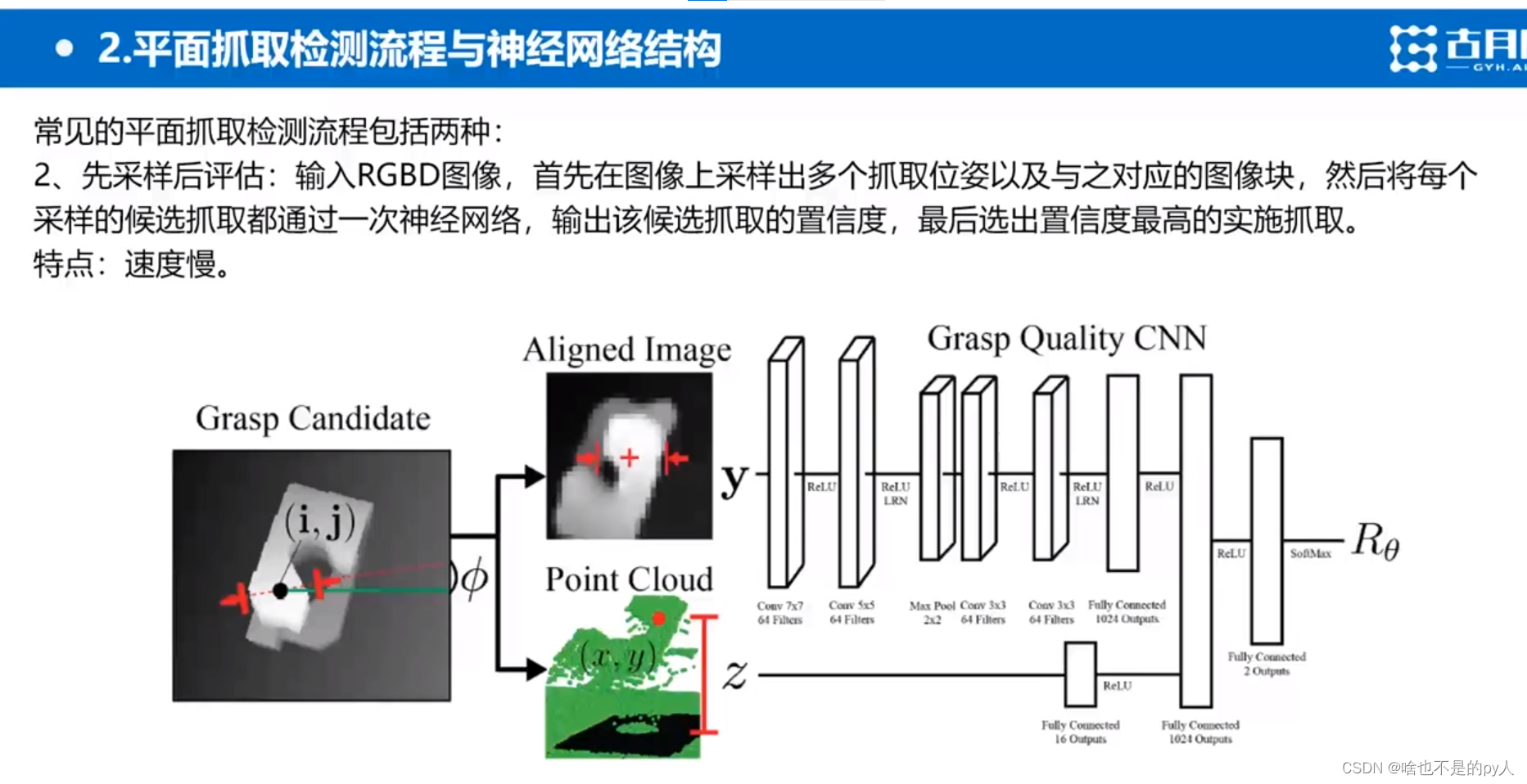
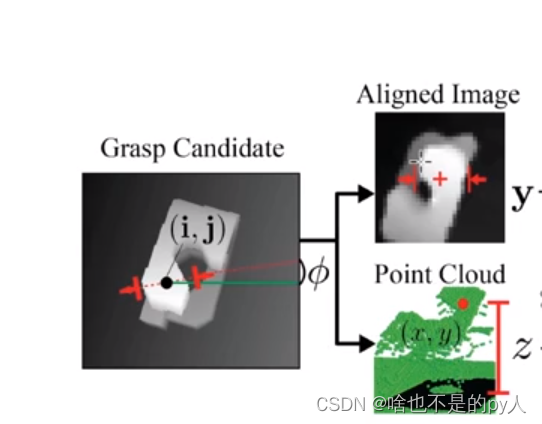
先输入rgbd图像
在图像上采样出多个抓取位姿以及与其对应的图像块
 i,j分别是横纵坐标还有
i,j分别是横纵坐标还有角度
抓取宽度是定值
裁剪出以(i,j)为中心点,为旋转角度 的图像块
把图像块和采样出来的抓取深度
作为网络输入
因为抓取深度是在cpu里运算的所以比较慢
平面抓取检测数据集

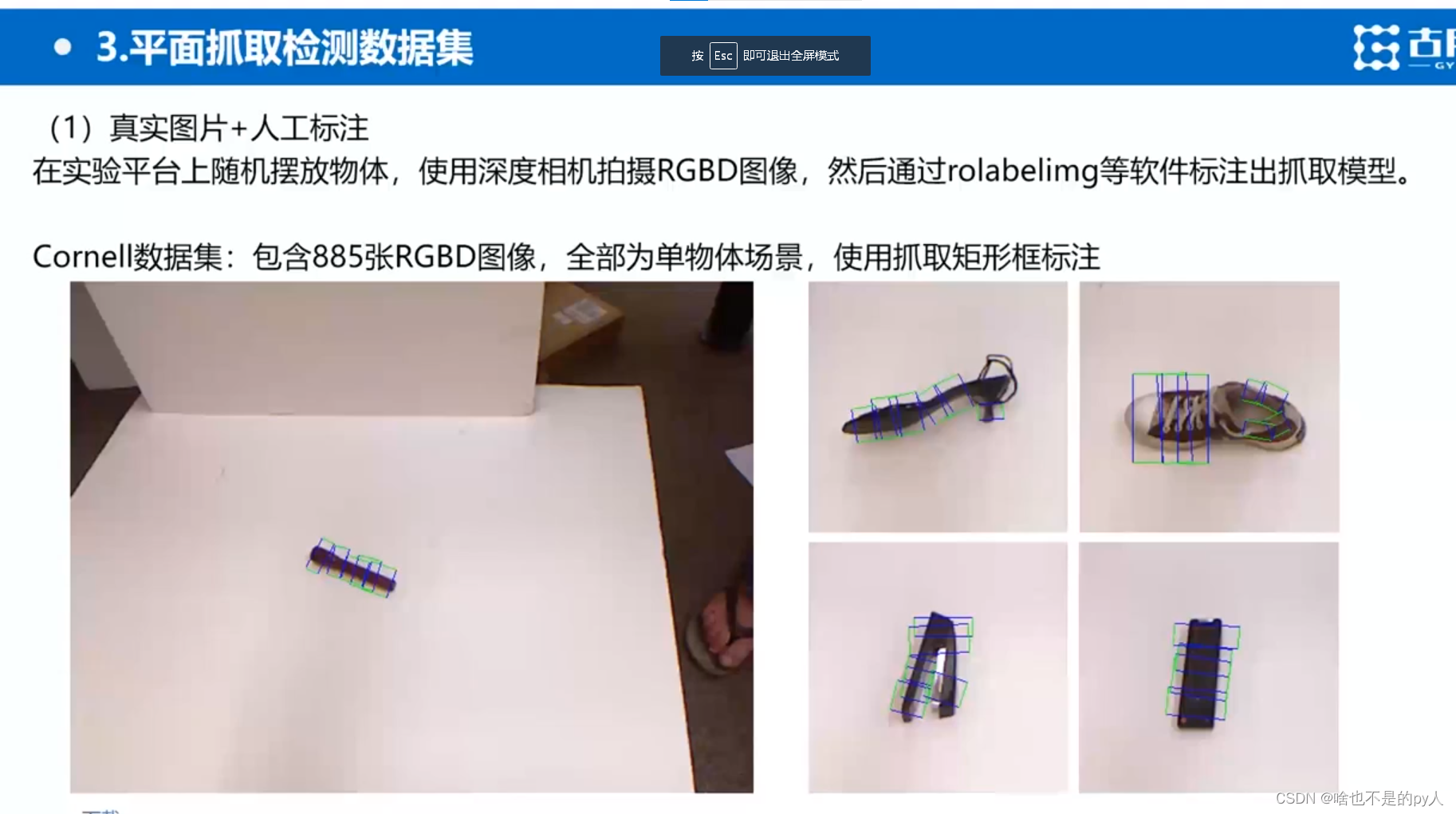
在实验平台也就是白板上
用深度相机拍摄rgbd图像
然后通过rolabelimg(旋转图形框)等软件人工标注出抓取模型
但是人觉得机械臂可以抓起来但是其实不一定可以抓起来
而且由于人的主观性会漏掉抓取位置
cornell下载

 clutter下载
clutter下载


费时费力,效果不好
title:learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection
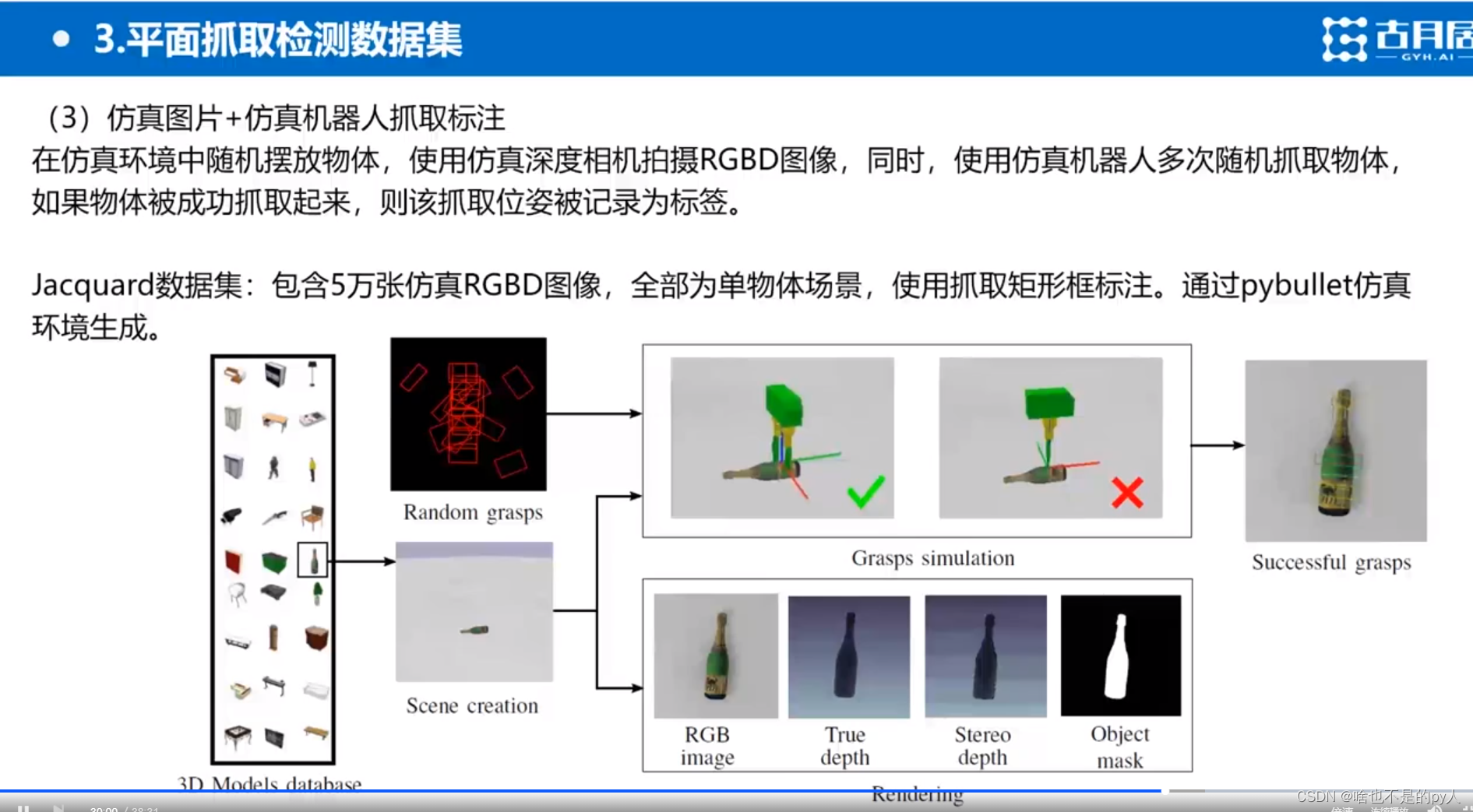
力螺旋理论及力封闭抓取的评价指标_DLUT_Hatim的博客-CSDN博客_力螺旋

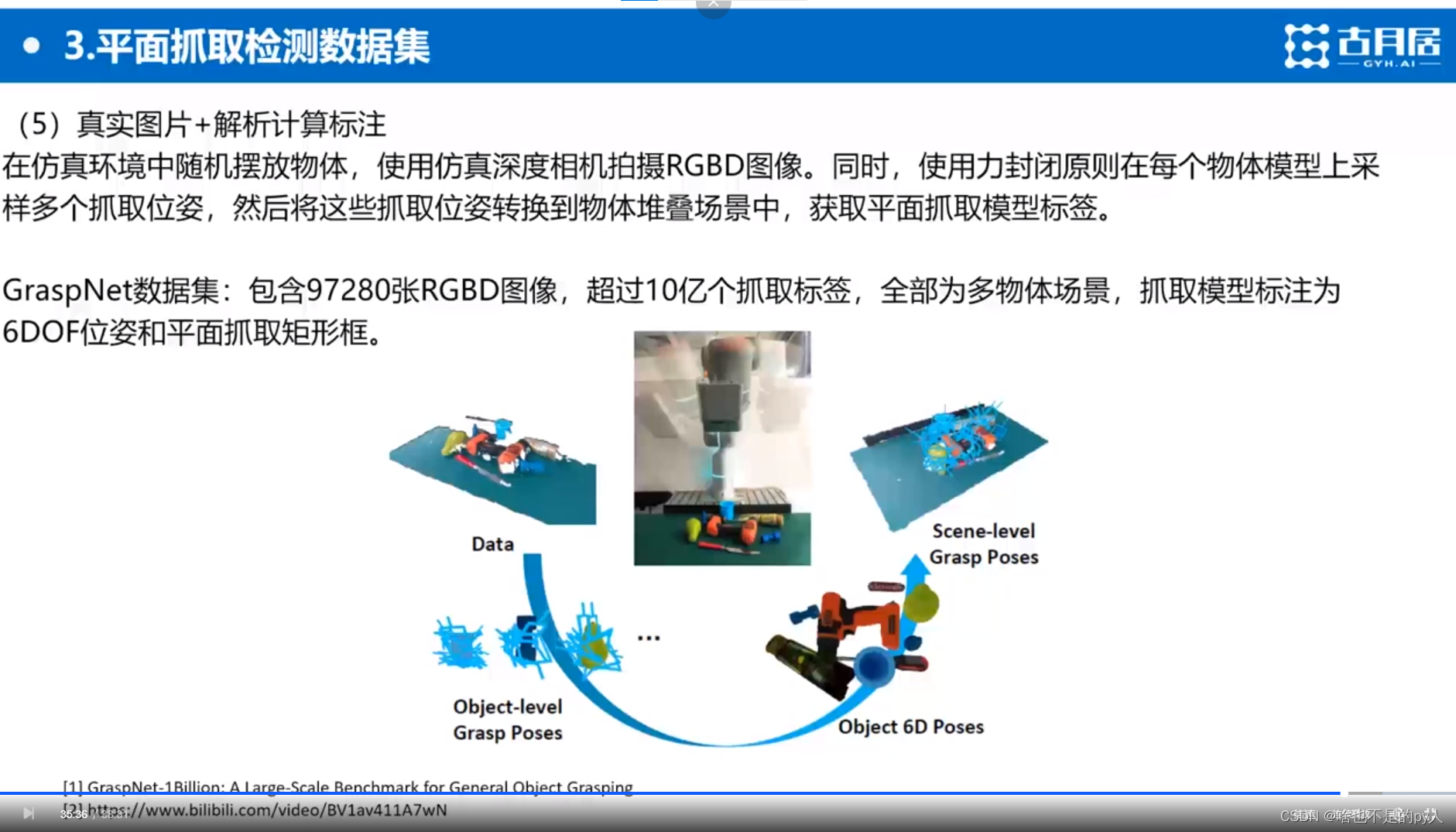
首先选取几十个物体
用相机构建完整的三维模型
然后人工标注每个物体的6D位姿
然后开始实验
相机捕捉到一张俯视图
再根据之前的物体建模生成很多3D姿态
再将对应方法生成到对应场景中
经典平面抓取算法

GGCNN

这是一种端到端的方法来进行抓取
以深度图作为输入
输出一种像素级的抓取位姿
概述
根据抓取的任务来确定网络的设计
根据抓取位姿来对数据集进行相关的标注
方便后续训练
网络结构

针对输入图像上的每一个像素点
以该像素点作为抓取点
 输入是300*300
输入是300*300
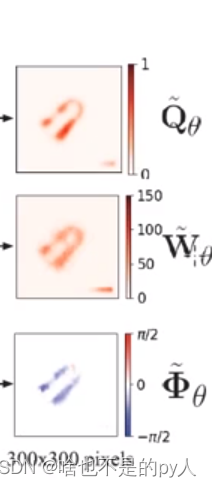 Q,W,
Q,W,也是输出的300*300

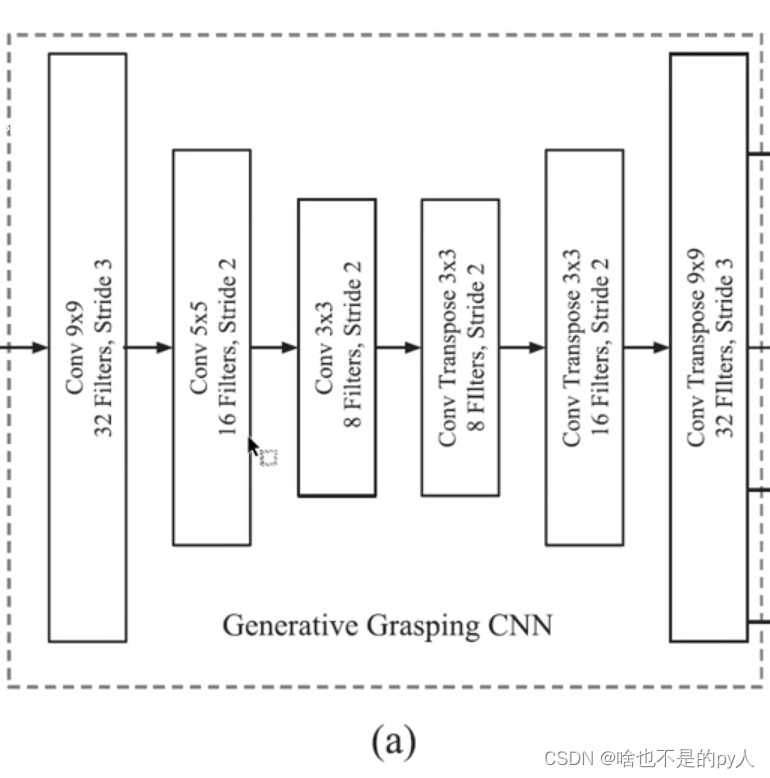
通过六个卷积
前三个卷积后面跟了池化来减小计算尺寸
后面三个是反卷积来增加尺寸
使得输出尺寸与输入尺寸相同
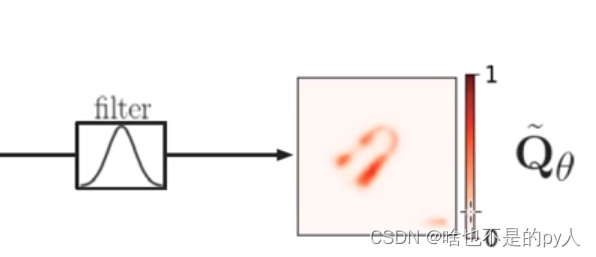
Q实际上就是置信度
sigmod输出成功概率Q(概率本来就是0-1)
0代表该像素点怎么抓都会失败
filter是一个高斯滤波
是输出更平滑
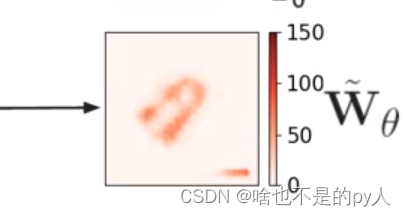 w是sigmod输出 乘上150
w是sigmod输出 乘上150
150是一个像素对应现实的长度
但实际上现实中是有差别的
有很多瑕疵
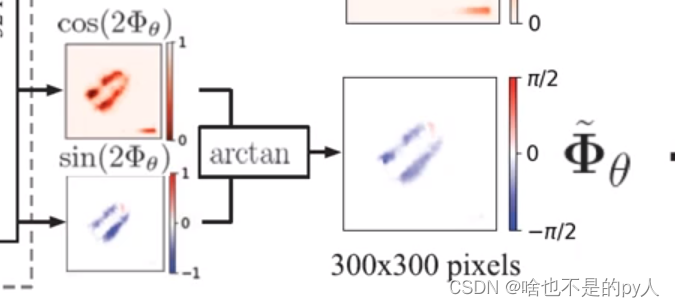
不是通过回归的方式输出
因为如果输出
0-
实际上对抓取来说0和是完全一样的
但在训练中可能导致混乱
转换成三角函数值就能使0和为一个值
避免了混乱
再通过简单的变换把旋转角输出成/2-(-
/2)

还有一种方法是分类
比如说把180度分类
分成18个类
每个类别10°
然后通过神经网络分类输出是属于哪一类
再将类别输出映射成实际的角度
所以根据网络结构
我们对数据集的标注就应该是
置信度Q,抓取宽度w,抓取角度
标注数据集中,置信度Q其实就是标注了就是1,没标注就是0

数据集构建
作者实际上借鉴了康奈尔数据集
康纳尔数据集实际上就是矩形框标注
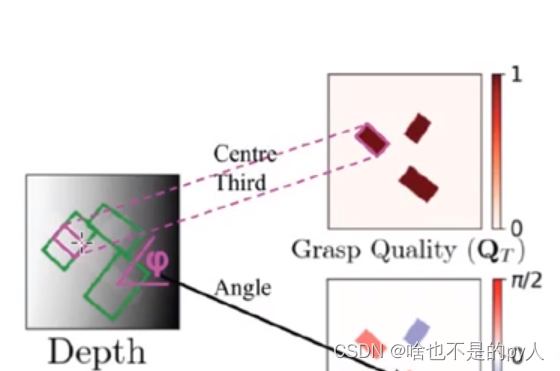
矩形框中心的1/3的点是位于物体上的
其余区域不是物体上的
GGCNN的作者就以1/3标注的抓取框中的点作为抓取点
然后直接把矩形框的抓取角设置为GGCNN的抓取角
然后宽度取相同的值
综上就获得了像素级抓取点
就不是离散的矩形框了
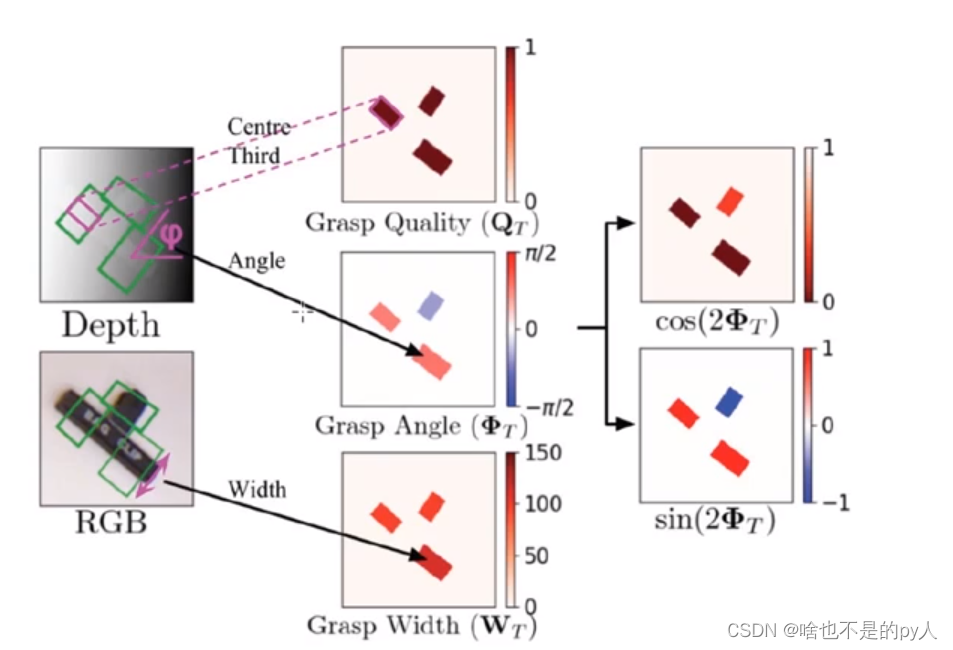
与像素点对应的抓取位置,抓取宽度,抓取角度
在数据集中对抓取宽度除以150即可
这样后面神经网络会把150乘回来

深度的输入
因为康奈尔数据集都是深度图构成的
是实际相机采集的
在训练的时候通过opencv的算法进行补全
减去均值进行归一化
归一化方法_百度百科![]() https://baike.baidu.com/item/%E5%BD%92%E4%B8%80%E5%8C%96%E6%96%B9%E6%B3%95/10089118
https://baike.baidu.com/item/%E5%BD%92%E4%B8%80%E5%8C%96%E6%96%B9%E6%B3%95/10089118
数据集训练的评判标准
数据集是有一个评判标准的
这里采用的是iou的评判标准

因为要输出和输入深度图同尺寸预测 的抓取图
在输出图中选择置信度最高的点
再选取对应这个点的抓取宽度和抓取旋转角度来得到抓取配置

真实的取自康奈尔数据集
如果预测的抓取角度和真值抓取的差值在30°以内
并且预测的抓取配置构成的矩形框与真实的差距在25%以内
认为是正确的
注意框的宽度不是网络预测输出的
而是直接用的康奈尔数据集,这也是GGCNN的瑕疵之一
后来也是出了GGCNN2
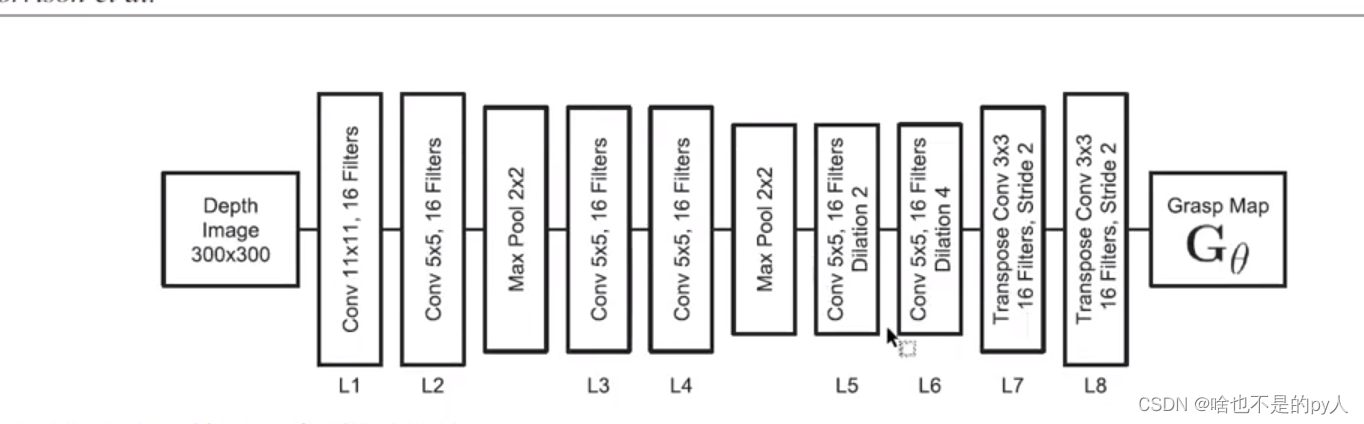
对反卷积层进行了改进
GGCNN方法简单但效果不太好
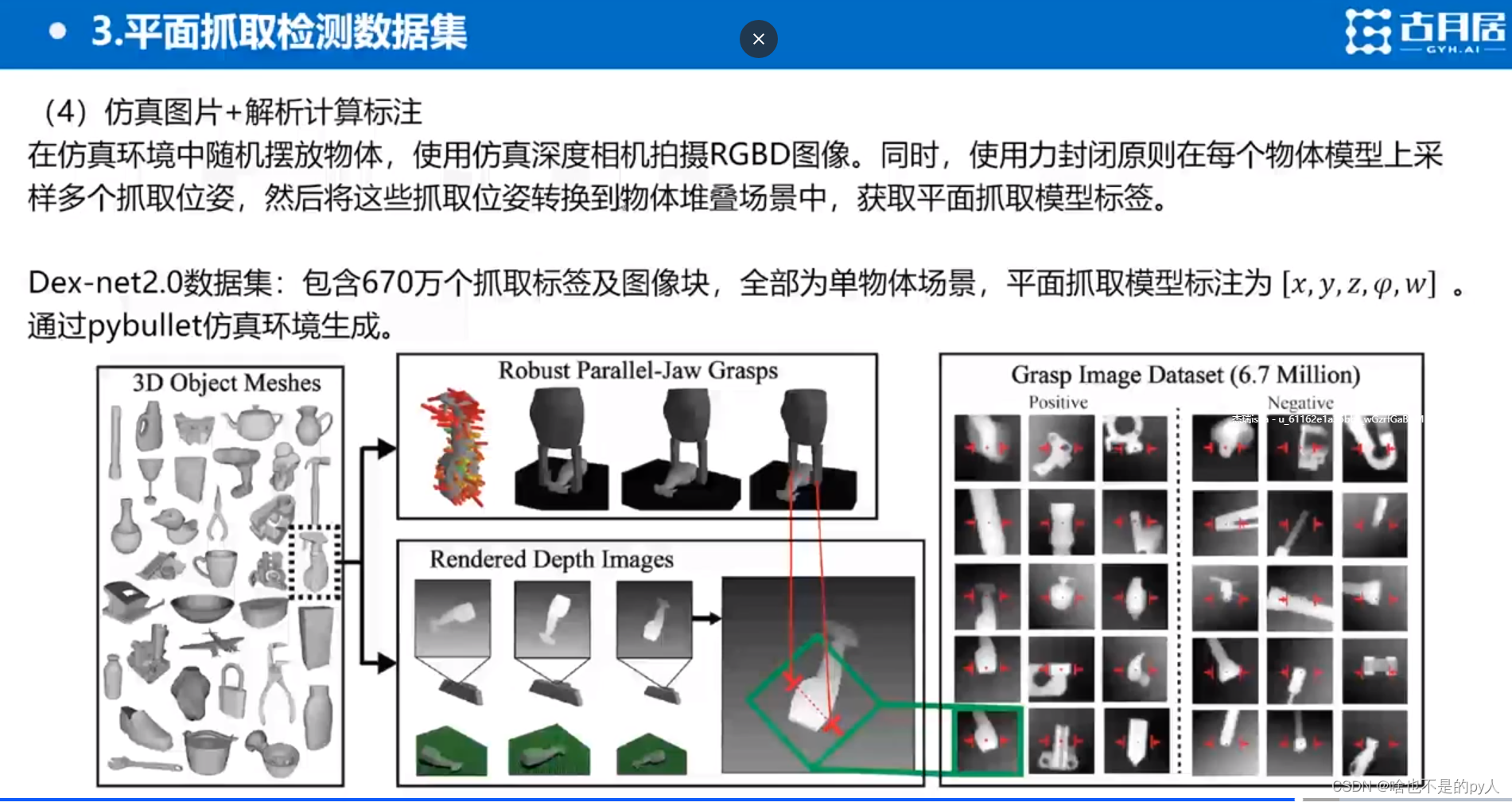
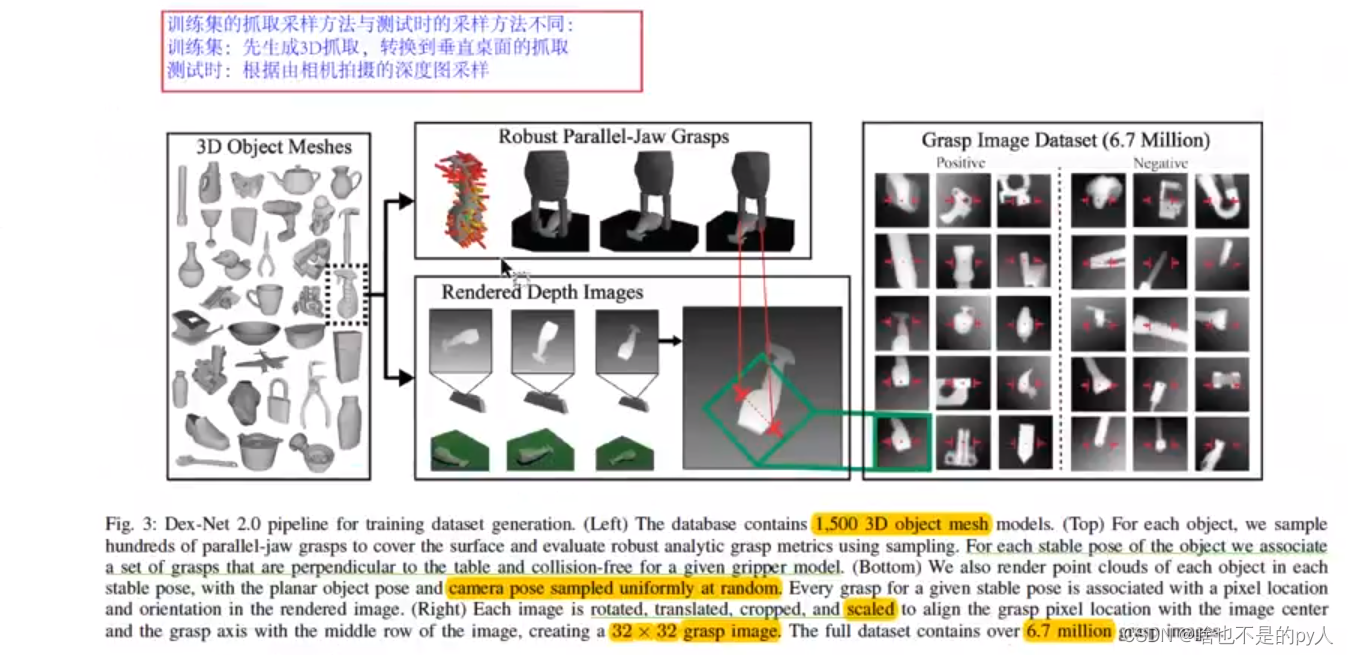
DEX-Ne t2.0
Dex-Net是先采样后评估的方法
这个方法知名度很高
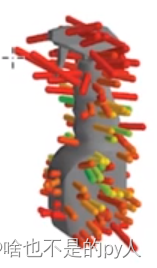 每一条线表示一个抓取位姿
每一条线表示一个抓取位姿
线的端点就是两个夹爪的位置
夹爪的闭合方向就是沿线的方向
Dex-Net 1.0 是生成3D物体的6D抓取位姿
Dex-Net 2.0 实际上就是基于Dex-Net 1.0生成这物体的平面抓取位姿
再通过碰撞检测筛选掉碰撞
针对筛选后的位姿
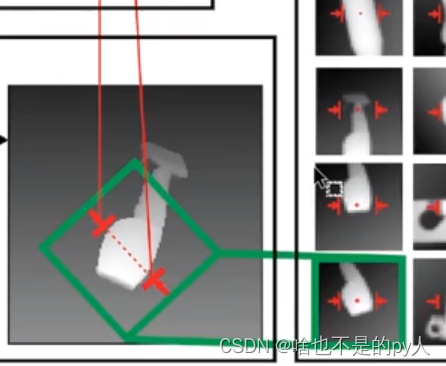
标注以位姿为中心的矩形框
把矩形框中的深度图像采点出来作为样本
![]()
所以样本量很大
因为对一个物体生成了很多平面抓取位姿
获取了很多图像框
把这些图像框作为图像块
还有对应的抓取深度
同时作为网络的输入
来预测给定抓取的置信度
方法的本质就是先采样再预测
所以它的速度很慢
采样过程需要耗费很长时间
Dex-Net 算是种先采样再预测做的最后的也是最好的一种方式了
这个方法精度很高
但是速度慢
并且只限于平面抓取
注:
因为数据集是基于仿真环境的,所以为了增加真实性,加了高斯噪声

方法是先对原始的深度乘上一个系数
来模拟实际深度值的可能的一个偏差
然后再加上的一个高斯噪声
但实际上真实的深度相机获取的图像可能受光照相机参数等影响
所以高斯噪声不能很好的模拟
注:
所以如果能把仿真图象做得很好的话也是一个非常好的方向
















 3013
3013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









