







简介
论文:https://arxiv.org/pdf/2003.04618.pdf
github:https://github.com/autonomousvision/convolutional_occupancy_networks
隐式方法的关键限制因素是其简单的全连接网络结构,不允许在观测中集成局部信息或纳入归纳偏差,如平移等方差
论文通过将卷积编码器与隐式占用解码器相结合,模型纳入了归纳偏差,使三维空间中的结构化推理成为可能
论文关键思想是建立丰富的输入特征,结合归纳偏差,整合局部和全局信息,利用卷积运算来获得平移等方差,并利用三维结构的局部自相似性
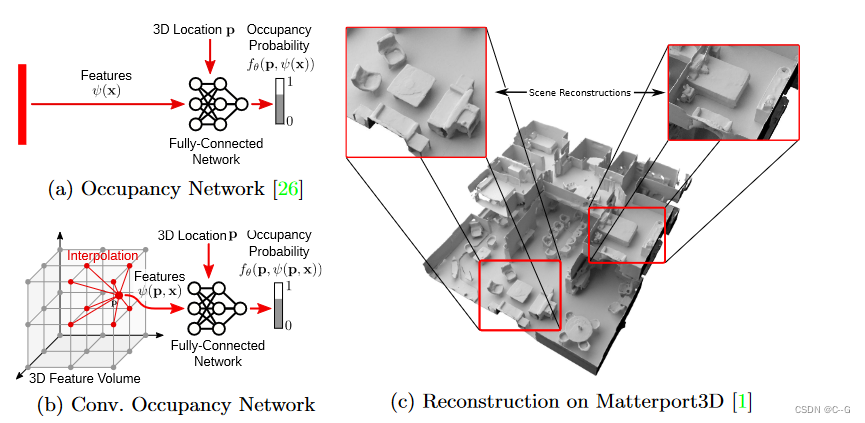
传统的隐式模型(a)由于其全连接的网络结构,其表达能力有限。论文提出利用卷积的卷积占用网络(b),从而产生可伸缩的等变隐式表示。使用线性插值查询3D位置p∈R3的卷积特征。与占用网络(ONet)相比,提出了特征表示ψ(p, x),因此同时依赖于输入x和3D位置p。图©显示了Matterport3D数据集上从噪声点云重建的两层建筑。
贡献点
- 确定了当前隐式3D重建方法的主要局限性
- 提出了一种灵活的平移等变架构,可实现从对象到场景级别的精确3D重建
- 模型能够从合成场景到真实场景以及新颖对象类别和场景的泛化。
实现流程
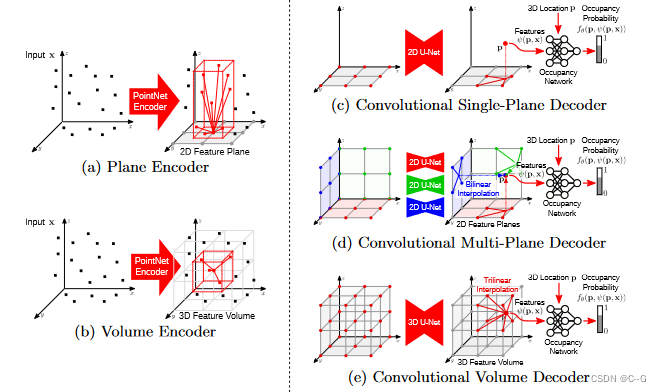
编码器(左)首先使用特定任务的神经网络将3D输入x(例如,噪声点云或粗体素网格)转换为特征。接下来,利用平均池化将特征投影到一个或多个平面(图2a)或一个体(图2b)。卷积解码器(右)使用2D/3D U-Nets处理生成的特征平面/体积,以聚合局部和全局信息。对于查询点p∈R3,通过双线性(图2c和图2d)或三线性(图2e)插值得到逐点特征向量ψ(x, p)。给定位置p处的特征向量ψ(x, p),利用全连通网络fθ(p, ψ(p, x))预测占据概率。
Encoder
Plane Encoder 平面编码器
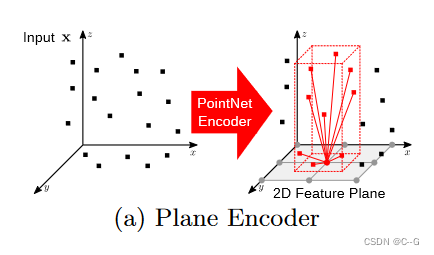
对于每个输入点,我们在标准平面(即与坐标系轴线对齐的平面)上进行正交投影,以H × W像素单元的分辨率离散该标准平面
对于体素输入,将体素中心视为一个点,并将其投射到平面上,使用平均池化的方法将投影到同一个像素上的特征进行聚集,得到的平面特征维数为H × W × d,其中d为特征维数
模型的两种变体,一是将特征投影到地平面上,二是特征被投影到所有三个正则平面上,前者的计算效率更高,而后者允许在z维中恢复更丰富的几何结构
Volume Encoder 体积编码器
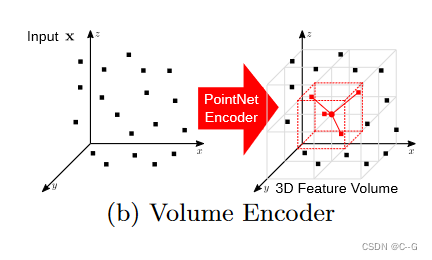
平面特征表示允许在大空间分辨率(128^2 像素以上)进行编码,但是仅限于二维,为此提出体积编码器,可以更好地表示3D信息,但仅限于更小的分辨率(在我们的实验中通常为32^3体素),与平面编码器一样,使用平均池化,但这次是对所有属于同一体素细胞的特征进行池化,从而产生一个维数为H × W × D × D的特征体积。
Decoder
使用2D和3D卷积沙漏(U-Net)网络处理编码器中的特征平面和特征体积,使模型具有平移等方差,U-Net网络由一系列带跳跃连接的下采样和上采样卷积组成,以整合局部和全局信息。选择U-Net的深度,使接收域等于各自的特征平面或体积的大小
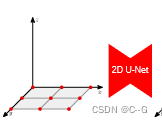
单平面解码器(图2c)使用2D U-Net处理地平面特征
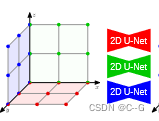
多平面解码器(图2d)使用权重共享的2d U-Nets对每个特征平面进行单独处理
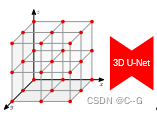
体积解码器(图2e)使用3D U-Ne
由于卷积运算是平移等变的,所以输出特征也是平移等变的,从而使结构化推理成为可能。此外,卷积操作能够在保留全局信息的同时“inpaint”特征,从而支持从稀疏输入进行重构。
Occupancy Prediction
给定聚合的特征图,估计任意点p在三维空间中的占用概率
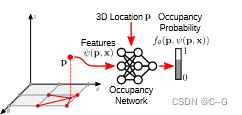
对于单平面解码器,将每个点p投影到地平面上,通过双线性插值查询特征值(图2c)。
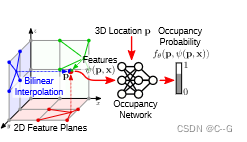
对于多平面解码器(图2d),通过对所有3个平面的特征求和来聚合来自3个正则平面的信息。
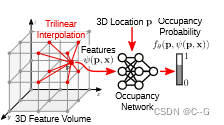
对于体积解码器,使用三线性插值(图2e)。输入x在p点处的特征向量为ψ(p, x),我们用一个小的全连通占用网络来预测p的占用情况:
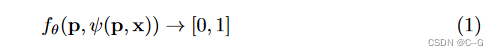
网络由多个ResNet块组成,在每个ResNet块的输入特征上加上ψ,对隐藏层使用32的特征维
Training and Inference
在感兴趣的体积内均匀采样查询点p∈R3,并预测其占用值。应用二元交叉熵损失之间的预测ˆop和真实占用值op
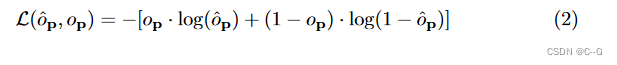
使用Adam优化器,学习率为10−4。在推理过程中,应用Multiresolution IsoSurface Extraction (MISE)来提取给定输入x的网格。由于模型是完全卷积的,能够通过在推理时以“滑动窗口”的方式应用它来重建大型场景。
效果
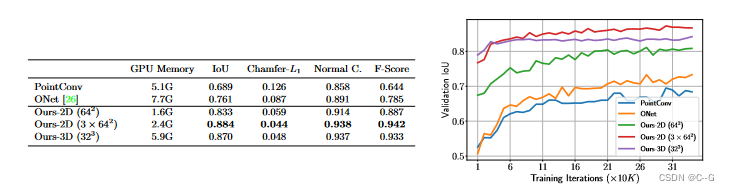
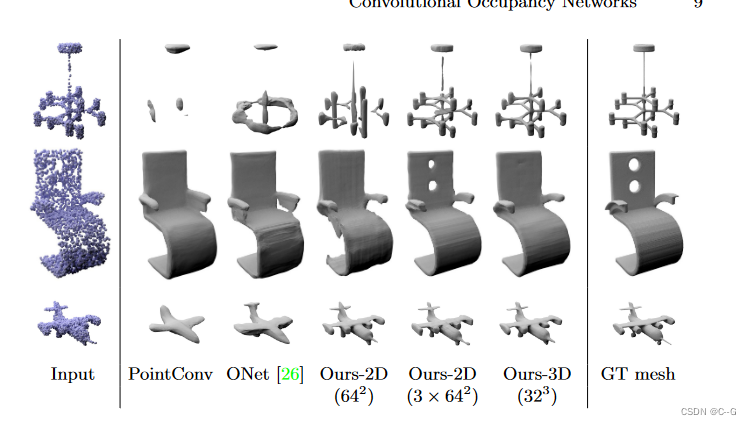
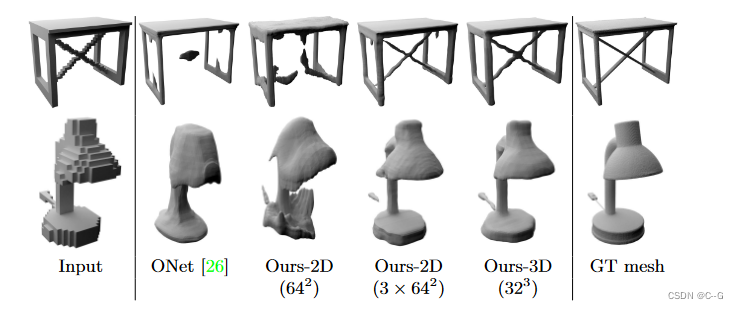















 1009
1009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









