






一、特征选择
在一个数据集中,每个特征在标签预测或分类过程中发挥的作用其实都不同。对于那些没作用和作用小的数据,我们就可以删掉,来降低数据的维度,节省模型拟合时的计算空间。
方法:
(1)相关性热力图
# 对所有的标签和特征两两显示其相关性热力图(heatmap)
import seaborn as sns
sns.heatmap(df_LTV.corr(), cmap="YlGnBu", annot = True)
X_train_less_feature = X_train.drop(['R值'], axis=1) #特征训练集
X_valid_less_feature = X_valid.drop(['R值'], axis=1) #特征验证集
model_lr_less_feature = LinearRegression() #创建线性回归模型
model_lr_less_feature.fit(X_train_less_feature, y_train) #拟合线性回归模型
print('测试集上的R平方分数-线性回归: %0.4f' % r2_score(y_valid, model_lr.predict(X_valid)))
print('测试集上的R平方分数-少R值特征的线性回归: %0.4f' % r2_score(y_valid, model_lr_less_feature.predict(X_valid_less_feature)))(2)自动特征选择
在 sklearn 的 feature_selection 模块中,有很多自动特征选择工具。SelectKBest较为常用。SelectKBest 的原理和使用都非常简单,它是对每个特征和标签之间进行统计检验,根据 X 和 y 之间的相关性统计结果,来选择最好的 K 个特征,并返回。在调用 SelectKBest 的过程中,我们是指定了参数 score_func = mutual_info_regression,其中,mutual_info_regression 是用于对连续型标签进行特征评分。如果标签是离散型的,那么就是分类问题,我们就要用过 mutual_info_classif 来评分了。
from sklearn.feature_selection import SelectKBest, mutual_info_regression #导入特征选择工具
selector = SelectKBest(mutual_info_regression, k = 2) #选择最重要的两个特征
selector.fit(X, y) #用特征选择模型拟合数据集
X.columns[selector.get_support()] #输出选中的两个特征输出如下:
Index(['F值', 'M值'], dtype='object')(3)变量组合特征……
二、特征变换
(1)特征缩放
对连续特征来说,我们最常见的特征变换就是特征缩放(feature scaling),也就是改变特征的分布或者压缩特征的区间。因为有很多模型都喜欢范围比较小、分布有规律的数据,比如采用梯度下降方法求解最优化的模型,较小的数值分布区间能够提升收敛速度,还有 SVM、KNN、神经网络等模型,都要求对特征进行缩放。

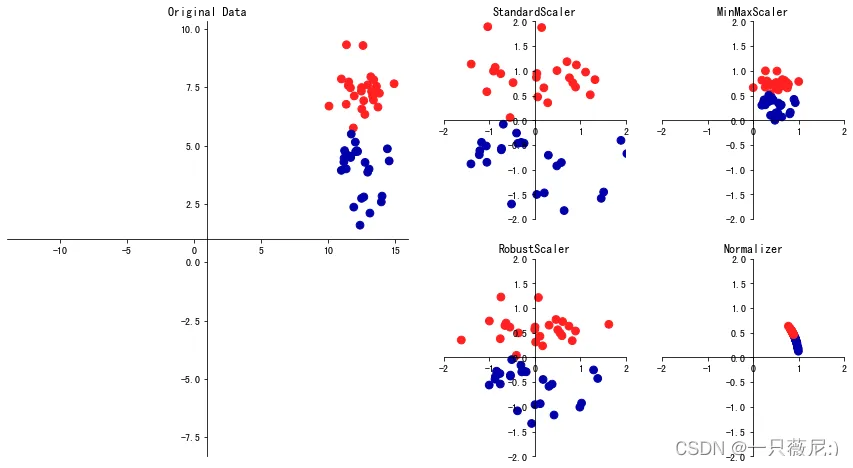
缩放:
from sklearn.preprocessing import StandardScaler #导入标准化缩放器
scaler = StandardScaler() #创建标准化缩放器
X_train_standard = scaler.fit_transform(X_train) #拟合并转换训练集数据
X_valid_standard = scaler.transform(X_valid) #转换验证集数据
X_test_standard = scaler.transform(X_test) #转换测试集数据在上面的代码中,你要特别注意,在创建标准化缩放器之后,我们对于训练集使用了 fit_transform 这个 API,这是 fit 和 transform 两个 API 的整合,它的意思是先根据训练集拟合数据,找到合适的标准化参数,然后再把参数应用在训练集上,给数据做缩放。
归一化:
from sklearn.preprocessing import MinMaxScaler #导入归一化缩放器
scaler = MinMaxScaler() #创建归一化缩放器
X_train_minmax = scaler.fit_transform(X_train) #拟合并转换训练集数据
X_valid_minmax = scaler.transform(X_valid) #转换验证集数据
X_test_minmax = scaler.transform(X_test) #转换测试集数据(2)对类别型特征的变换:虚拟变量和独热编码(见另一篇)
三、对数值型特征的离散化:分桶
四、特征构建
也就是新特征的衍生















 9618
9618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









