







文章目录
1 注意力机制(Attention)
Attention机制可以描述将一个Query和一组Key-Value对映射到一个输出,其中 d Q u e r y = d K e y d_{Query}=d_{Key} dQuery=dKey ,而输出向量序列 A t t Att Att 的维度 d A t t = d V a l u e d_{Att}=d_{Value} dAtt=dValue。
这这里对于没了解Attention的人来说可能会有疑问?Query、Key、Value是什么?哪里冒出来的?
先不考虑那么多,先知道对于Attention来说的输入就是三个向量,就当作Query、Key、Value你都事先已知了
剧透:它们是由X或者其它Input的线性变化而来;
1.1 注意力机制(Attention)
注意力机制通过计算输入序列中各位置之间的相似性(即注意力权重),并利用这些权重对信息进行加权平均来实现。具体来说:
-
计算相似性得分:对给定的查询向量(Query)和所有键向量(Key),计算相似性得分,也可以理解为权重值。
在邱锡鹏《神经网络与深度学习》这本书中计算相似性得分(Score)使用的函数统称为注意力打分函数** s ( K , Q ) s(K,Q) s(K,Q)**。我们常用也是最简单的打分函数是点积模型:
s ( Q , K ) = Q K ⊺ s(Q,K)=Q K^\intercal s(Q,K)=QK⊺
[!NOTE]
打分函数采用点积模型的注意力机制也可以被称为点积注意力机制(Dot-Product Attention)
如果打分函数定义为内积模型,那么Q和K的维度就必须保证是一致的,这也是为什么在最开头我说 d Q u e r y = d K e y d_{Query}=d_{Key} dQuery=dKey
这里需要特别注意一下维度,我们借助Figure 1来理解一下打分函数 s ( Q , K ) s(Q,K) s(Q,K):
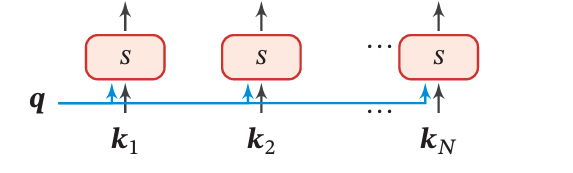
Figure 1: The Score of Query and Key
s ( Q , K ) s(Q,K) s(Q,K) 函数中的 K = [ [ k 1 ] , [ k 2 ] , [ k 3 ] , . . . , [ k n ] ] K=[[k_1],[k_2],[k_3],...,[k_n]] K=[[k1],[k2],[k3],...,[kn]] ,其中 k i ∈ R 1 × d k k_i\in\mathbb{R}^{1\times d_k} ki∈R1×dk。Figure 1中的 q q q 表示** Q = [ [ q 1 ] , [ q 2 ] , [ q 3 ] , . . . , [ q t ] ] Q=[[q_1],[q_2],[q_3],...,[q_t]] Q=[[q1],[q2],[q3],...,[qt]]**中的某个给定的 q i ∈ R 1 × d k q_i\in\mathbb{R}^{1\times d_k} qi∈R1×dk。所以Figure 1中的每个 s s s 实际上是一个标量,所有的 s s s 组合起来才是 q i q_i qi 对应的相似性得分向量 s i ∈ R 1 × n s_i\in\mathbb R^{1\times n} si∈R1×n。而 Q ∈ R t × d k Q\in\mathbb R^{t\times d_k} Q∈Rt×dk,一共有 t 个 q i q_i qi,所以 s ( Q , K ) s(Q,K) s(Q,K) 函数最后得到的就是一个 R t × n \mathbb R^{t\times n} Rt×n 的矩阵。
这里的n和t可以相同可以不同,取决于Key-Value和Query的来源,因为Query的长度可以和Key-Value不同,所以用t表示
-
归一化得分:通过softmax函数将相似性得分归一化为注意力权重,表示不同位置的相对重要性。
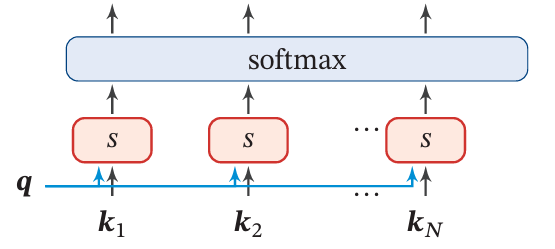
Figure 2: The Softmax of Score
这一步很简单(如Figure 2),就是对1.中的每个 s i s_i si 做一次softmax归一,公式就是:
α i = s o f t m a x ( s ( q i , K ) ) ∈ R 1 × n \alpha_i=\mathrm{softmax}\left(s(q_i,K)\right)\in\mathbb R^{1\times n} αi=softmax(s(qi,K))∈R1×n
总的公式就是:
α = s o f t m a x ( s ( Q , K ) ) ∈ R t × n \alpha=\mathrm{softmax}\left(s(Q,K)\right)\in\mathbb R^{t\times n} α=softmax(s(Q,K))∈Rt×n
在邱锡鹏《神经网络与深度学习》中将 α i \alpha_i αi 称为注意力分布向量,那么 α \alpha α 不妨就称为注意力分布矩阵。 -
加权求和:使用注意力分布矩阵对值向量(Value)进行加权平均,得到最终的输出。
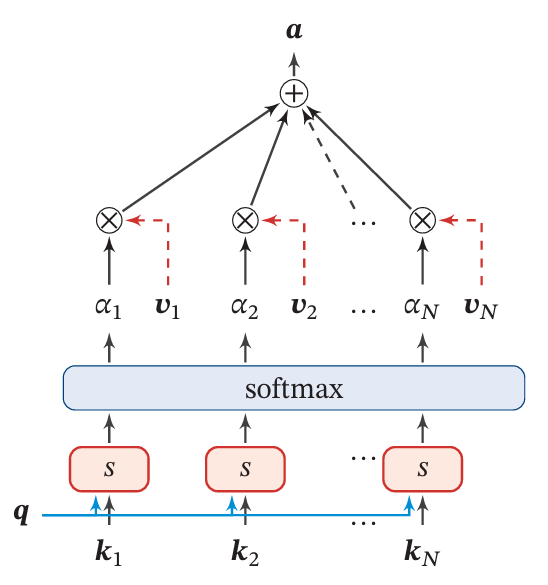
Figure 3:The Key-Value Pair Mode
Note:下面没有特别说明的话, α i \alpha_i αi向量等于Figure 3中的 [ α 1 , α 2 , α 3 , . . . , α n ] [\alpha_1,\alpha_2,\alpha_3,...,\alpha_n] [α1,α2,α3,...,αn],图中的 α \alpha α是标量
如Figure 3,每一个
q
i
∈
R
1
×
d
k
q_i\in\mathbb{R}^{1\times d_k}
qi∈R1×dk 都会对应一个注意力分布向量
α
i
∈
R
1
×
n
\alpha_i\in\mathbb R^{1\times n}
αi∈R1×n,
α
i
\alpha_i
αi 对应整个
V
a
l
u
e
=
[
[
v
1
]
,
[
v
2
]
,
[
v
3
]
,
.
.
.
,
[
v
n
]
]
∈
R
n
×
d
v
Value=[[v_1],[v_2],[v_3],...,[v_n]]\in\mathbb{R}^{n\times d_v}
Value=[[v1],[v2],[v3],...,[vn]]∈Rn×dv,故:
a
t
t
i
=
α
i
V
∈
R
1
×
d
v
att_i=\alpha_iV\in\mathbb R^{1\times d_v}
atti=αiV∈R1×dv
即为
q
i
q_i
qi 对应的attention结果;总公式用矩阵运算表示为:
Attention
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
s
(
Q
,
K
)
V
=
s
o
f
t
m
a
x
(
Q
K
T
)
V
∈
R
t
×
d
v
\text{Attention}(Q, K, V) = \mathrm{softmax}(s(Q,K)V=\mathrm{softmax}(QK^T)V\in\mathbb R^{t\times d_v}
Attention(Q,K,V)=softmax(s(Q,K)V=softmax(QKT)V∈Rt×dv
[!IMPORTANT]
小结(如Figure 4):我们以端到端的思维来看整个Attention机制的话,模型的输入是 Q u e r y ∈ R t × d k Query\in\mathbb R^{t\times d_k} Query∈Rt×dk、 K e y ∈ R n × d k Key\in\mathbb R^{n\times d_k} Key∈Rn×dk、 V a l u e ∈ R n × d v Value\in\mathbb R^{n\times d_v} Value∈Rn×dv,输出是 A t t ∈ R t × d v Att\in\mathbb R^{t\times d_v} Att∈Rt×dv。
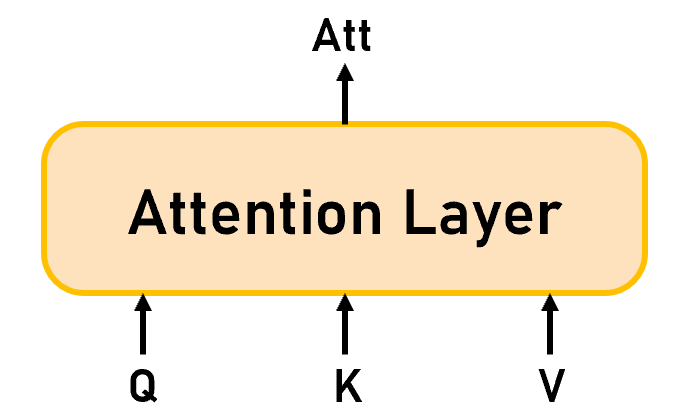
Figure 4:Attention Layer
1.2 缩放点积注意力机制(Scaled Dot-Product Attention)
《Attention is All You Need》:We call our particular attention “Scaled Dot-Product Attention”
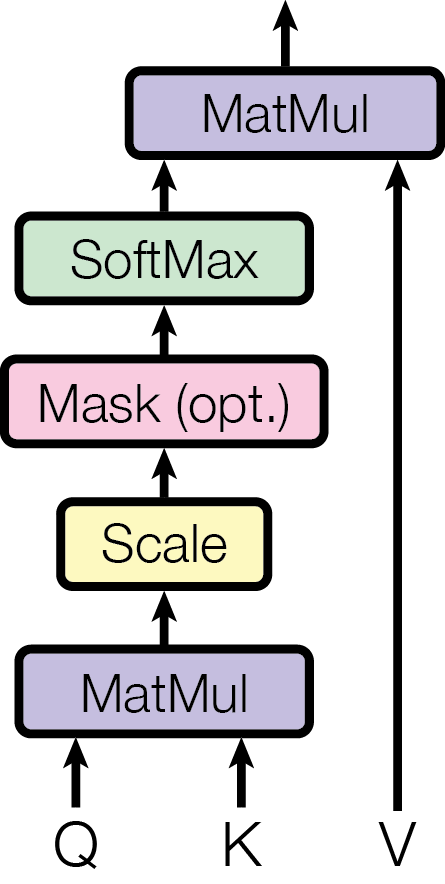
Figure 5: Scaled Dot-Product Attention
在Transformer中就使用的是Scaled Dot-Product Attention(图Figure 5),其实名字取得很唬人,实际上和我们上面讲的Attention的差别就是一个缩放而已。具体的表达式如下:
Attention
(
Q
,
K
,
V
)
=
softmax
(
Q
K
T
d
k
)
V
∈
R
t
×
d
v
\begin{equation}\text{Attention}(Q,K,V)=\text{softmax}(\frac{QK^T}{\sqrt{d_k}})V\end{equation}\in\mathbb R^{t\times d_v}
Attention(Q,K,V)=softmax(dkQKT)V∈Rt×dv
Scaled Dot-Product Attention和我们上面提到的Dot-Product Attention只多乘了
1
d
k
\frac{1}{\sqrt{d_k}}
dk1,其它的部分完全相同,这里就不再重复解释了。
[!TIP]
这里其实一般会有一个疑问:既然其它过程完全都一样, d k \sqrt{d_k} dk 不就是一个固定的数吗?那为什么要除以 d k \sqrt{d_k} dk 呢?
这个在《Attention is All You Need》中给出的解释是:We suspect that for large values of d k d_k dk, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients. To counteract this effect, we scale the dot products by 1 d k \frac{1}{\sqrt{d_k}} dk1.
翻译:我们认为,对于较大的 d k d_k dk 值,点积在数量级上的幅度会越来越大,从而将 softmax 函数推向梯度极小的区域。为了消除这种影响,我们用 1 d k \frac{1}{\sqrt{d_k}} dk1来缩放点积。
通俗理解:########理解不了一点,之后再写############
1.3 自注意力机制(Self-Attention)
之前我们都是直接假设已知了Query、Key、Value。那这一节就能知道它们的来源之一了
为了提高模型能力,Self-Attention经常采用查询-键-值(Query-Key-Value,QKV)模式(如Figure 3),其计算过程如Figure 6所示,其中红色字母表示矩阵的维度。
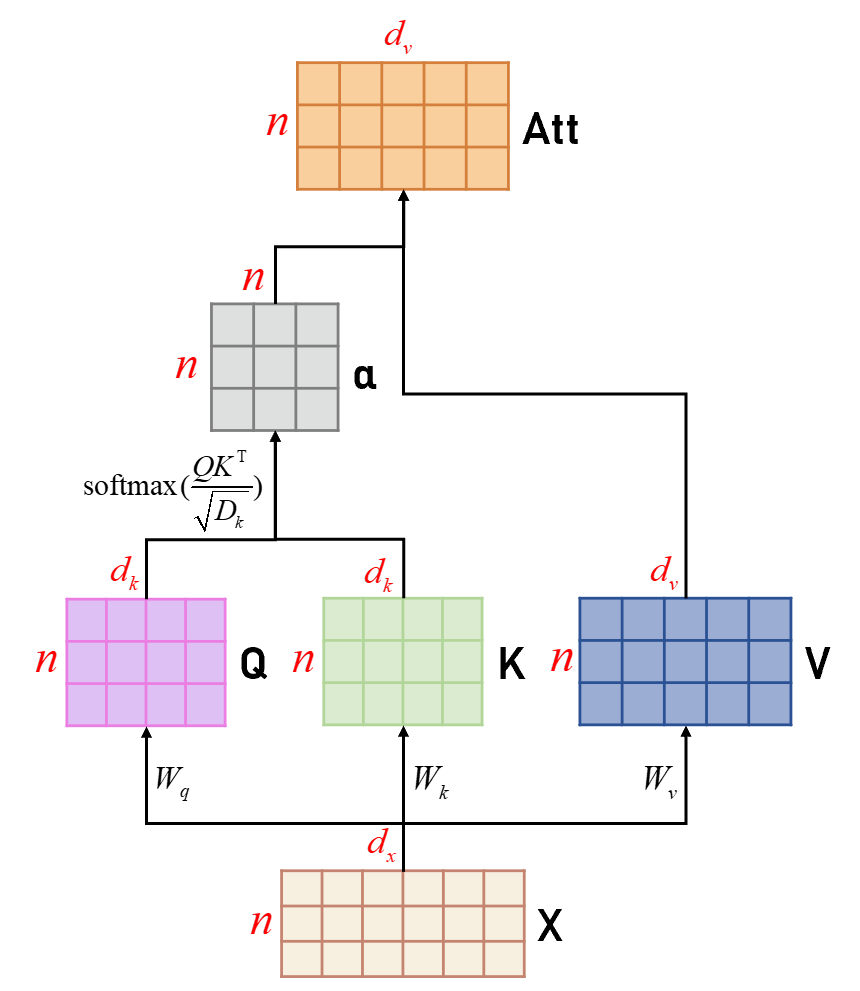
Figure 6: The Calculation Process of Self-Attention
其实看着Figure 6就可以明显的看出,Self-Attention只是比之前讲的Scaled Dot-Product Attention多了一层线性转换:通过Input X去映射Query、Key、Value。我们具体来看一下:
对于每个输入 x i ∈ R 1 × d x x_i\in\mathbb R^{1\times d_x} xi∈R1×dx ,我们首先将其线性映射到三个不同的空间,得到查询向量 q i ∈ R 1 × d k q_i\in\mathbb R^{1\times d_k} qi∈R1×dk、键向量 k i ∈ R 1 × d k k_i\in\mathbb R^{1\times d_k} ki∈R1×dk和值向量 v i ∈ R 1 × d v v_i\in\mathbb R^{1\times d_v} vi∈R1×dv。按照Figure 6中X由 n n n 个 x i x_i xi 组成,所以对于整个序列 X X X ,最终映射出来的 Q 、 K 、 V Q、K、V Q、K、V 的长度均为 n n n。
对于整个输入序列
X
∈
R
n
×
d
x
X\in\mathbb R^{n\times d_x}
X∈Rn×dx ,线性映射过程可以简写为:
Q
=
X
W
q
∈
R
n
×
d
k
K
=
X
W
k
∈
R
n
×
d
k
V
=
X
W
v
∈
R
n
×
d
v
\boldsymbol{Q}=\boldsymbol{X}\boldsymbol{W}_q\in\mathbb{R}^{n\times d_k} \\\boldsymbol{K}=\boldsymbol{X}\boldsymbol{W}_k\in\mathbb{R}^{n\times d_k} \\\boldsymbol{V}=\boldsymbol{X}\boldsymbol{W}_v\in\mathbb{R}^{n\times d_v}
Q=XWq∈Rn×dkK=XWk∈Rn×dkV=XWv∈Rn×dv
其中
W
q
∈
R
d
x
×
d
k
W_q\in\mathbb R^{d_x\times d_k}
Wq∈Rdx×dk、
W
k
∈
R
d
x
×
d
k
W_k\in\mathbb R^{d_x\times d_k}
Wk∈Rdx×dk、
W
v
∈
R
d
x
×
d
v
W_v\in\mathbb R^{d_x\times d_v}
Wv∈Rdx×dv。
而我们由Figure 4可以知道,已知 Q 、 K 、 V Q、K、V Q、K、V便可通过Attention Layer得到输出。所以Self-Attention就像是Linear Layer + Attention Layer的组合。
[!IMPORTANT]
小结(如Figure 7):我们以非端到端的思维来看整个Self-Attention机制的话,模型的输入是 X ∈ R n × d x X\in\mathbb R^{n\times d_x} X∈Rn×dx,会通过线性层映射为 Q u e r y ∈ R n × d k Query\in\mathbb R^{n\times d_k} Query∈Rn×dk、 K e y ∈ R n × d k Key\in\mathbb R^{n\times d_k} Key∈Rn×dk、 V a l u e ∈ R n × d v Value\in\mathbb R^{n\times d_v} Value∈Rn×dv,输出是 A t t ∈ R n × d v Att\in\mathbb R^{n\times d_v} Att∈Rn×dv。值得注意的是:由于Q-K-V都是由X来的,所以Q-K-V-Att的长度都和X一样,不变的是 d A t t = d v d_{Att}=d_v dAtt=dv。
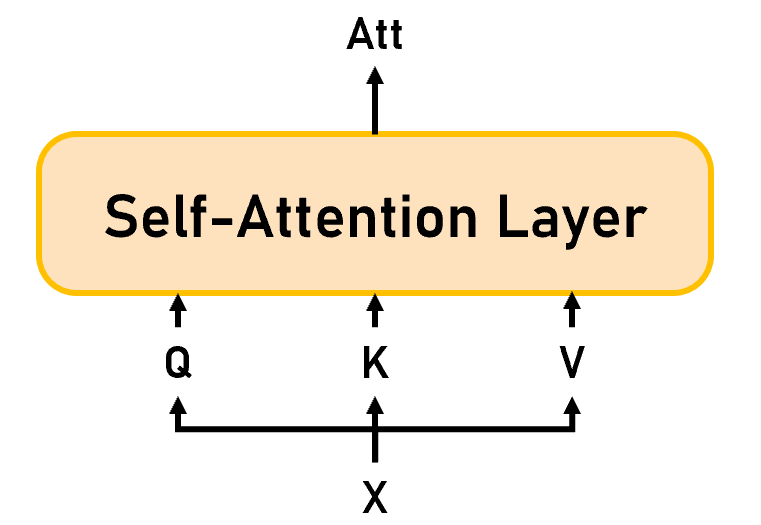
Figure 7: Self-Attention Layer
1.4 多头注意力机制(Multi-Head Attention)
单一的注意力机制在计算注意力权重时,只能关注输入序列中的一个特定模式或关系。多头注意力机制通过并行计算多个注意力头,每个注意力头可以在不同的子空间中独立地学习和捕捉不同的语义信息。多头注意力机制允许模型在多个子空间中进行并行计算,使得模型可以同时学习多个不同的特征表示。这种并行处理大大增加了模型的学习能力和参数空间,使模型能够更好地拟合复杂的数据分布。

(图片来源:架构师带你玩转AI): Multi-Head Attention GIF
一句话来描述Multi-Head Attention的话:将查询、键和值分别线性变换成多个子空间中的查询、键和值,计算每个子空间中的注意力,然后将所有头的结果拼接起来,再通过一个线性变换就可以得到输出(如Figure 8)
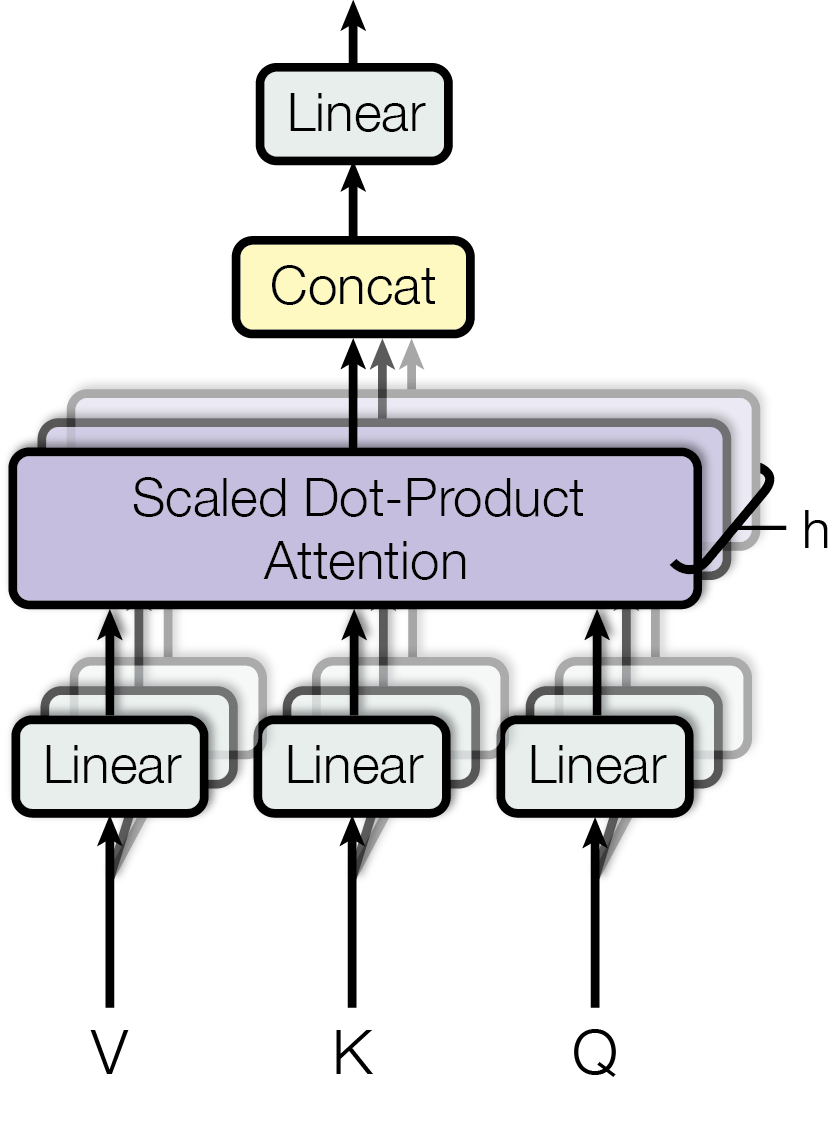
Figure 8: Multi-Head Attention
假设一共采用
h
h
h 个 head 的Attention,我们知道Attention的输入是一组Query-Key-Value,所以
h
h
h 个 head 的Attention就是有
h
h
h 组Query-Key-Value。那么如何在初始只有一组的情况下变为
h
h
h 组呢?采用的就是执行
h
h
h 次的Linear Layer:
Q
i
=
Q
W
i
Q
∈
R
t
×
d
k
K
i
=
K
W
i
K
∈
R
n
×
d
k
V
i
=
V
W
i
V
∈
R
n
×
d
v
Q_i=QW_i^Q\in\mathbb R^{t\times d_k} \\K_i=KW_i^K\in\mathbb R^{n\times d_k} \\V_i=VW_i^V\in\mathbb R^{n\times d_v}
Qi=QWiQ∈Rt×dkKi=KWiK∈Rn×dkVi=VWiV∈Rn×dv
其中,
i
=
1
,
2
,
3...
,
h
i=1,2,3...,h
i=1,2,3...,h;在每个
head
i
\text{head}_i
headi 中都存在一组
W
i
Q
∈
R
d
m
o
d
e
l
×
d
k
W_i^Q\in\mathbb{R}^{d_{\mathrm{model}}\times d_k}
WiQ∈Rdmodel×dk,
W
i
K
∈
R
d
m
o
d
e
l
×
d
k
W_i^K\in\mathbb{R}^{d_{\mathrm{model}}\times d_k}
WiK∈Rdmodel×dk,
W
i
V
∈
R
d
m
o
d
e
l
×
d
v
W_i^V\in\mathbb{R}^{d_{\mathrm{model}}\times d_v}
WiV∈Rdmodel×dv,那么
h
h
h 个 head 就有8组权重项,这也说明了在Multi-Head Attention的Linear Layer使用的并不是共享权重参数。
[!CAUTION]
这里需要解释一下在 W i Q 、 W i K 、 W i V W_i^Q、W_i^K、W_i^V WiQ、WiK、WiV 维度中使用的 d m o d e l d_{model} dmodel ,这里的 d m o d e l d_{model} dmodel 是值Q-K-V初始的维度。因为线性映射你可以是映射为同维、高维or低维,都是可以的,所以用 d m o d e l d_{model} dmodel 表示初始的Q-K-V维度。当然Q-K的映射结果维度都设置为相同的 d k d_k dk 也是因为需要做点积运算。
接着使用Scaled Dot-Product Attention去学习每组Query-Key-Value对就可以得到对应的输出头
head
i
\text{head}_i
headi :
where head
i
=
Attention
(
Q
i
,
K
i
,
V
i
)
=
Attention
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
\text{where head}_\mathrm{i} =\text{Attention}(Q_i,K_i,V_i)=\text{Attention}(QW_i^Q,KW_i^K,VW_i^V)
where headi=Attention(Qi,Ki,Vi)=Attention(QWiQ,KWiK,VWiV)
其中
head
i
∈
R
t
×
d
v
\text{head}_i\in\mathbb R^{t\times d_v}
headi∈Rt×dv 。
之后的Concat Layer和Linear Layer就比较简单了,就是直接将输出的
h
h
h 个
head
i
\text{head}_i
headi 做连接然后映射为
d
M
u
l
A
t
t
d_{MulAtt}
dMulAtt 维:
M
u
l
t
i
H
e
a
d
(
Q
,
K
,
V
)
=
C
o
n
c
a
t
(
h
e
a
d
1
,
.
.
.
,
h
e
a
d
h
)
W
O
∈
R
t
×
d
M
u
l
A
t
t
\mathrm{MultiHead}(Q,K,V)=\mathrm{Concat}(\mathrm{head}_1,...,\mathrm{head}_\mathrm{h})W^O\in\mathbb R^{t\times d_{MulAtt}}
MultiHead(Q,K,V)=Concat(head1,...,headh)WO∈Rt×dMulAtt
我们知道每个
head
i
∈
R
t
×
d
v
\text{head}_i\in\mathbb R^{t\times d_v}
headi∈Rt×dv ,所以
C
o
n
c
a
t
(
h
e
a
d
1
,
.
.
.
,
h
e
a
d
h
)
∈
R
t
×
h
d
v
\mathrm{Concat}(\mathrm{head}_1,...,\mathrm{head}_\mathrm{h})\in\mathbb R^{t\times hd_v}
Concat(head1,...,headh)∈Rt×hdv。所以
W
O
∈
R
h
d
v
×
d
M
u
l
A
t
t
W^{O}\in\mathbb R^{hd_v\times d_{MulAtt}}
WO∈Rhdv×dMulAtt 。
[!IMPORTANT]
小结(如Figure 9):从端到端的角度看Multi-Head Attention可以知道,Multi-Head Attention的输入和Attention一样都是一组 Q u e r y ∈ R t × d m o d e l Q Query\in\mathbb R^{t\times d_{modelQ}} Query∈Rt×dmodelQ、 K e y ∈ R n × d m o d e l K Key\in\mathbb R^{n\times d_{modelK}} Key∈Rn×dmodelK、 V a l u e ∈ R n × d m o d e l V Value\in\mathbb R^{n\times d_{modelV}} Value∈Rn×dmodelV ,这里的 d m o d e l d_{model} dmodel 可以相同也可以不同。输出是 M u l t i H e a d ∈ R t × d M u l A t t MultiHead\in\mathbb R^{t\times d_{MulAtt}} MultiHead∈Rt×dMulAtt
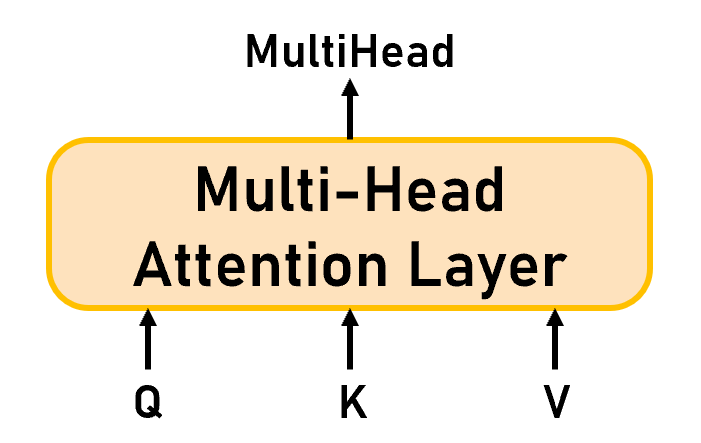
Figure 9: Multi-Head Attention Layer
1.5 多头自注意力机制(Multi-Head Self-Attention)
在了解过了Multi-Head Attention再来看Multi-Head Self-Attention就简单很多了。Multi-Head Self-Attention同样也只比Multi-Head Attention多了一层从 X 提取信息的Linear Layer。
个人觉得可以简单理解为:Multi-Head Self-Attention = Linear Layer + Multi-Head Attention
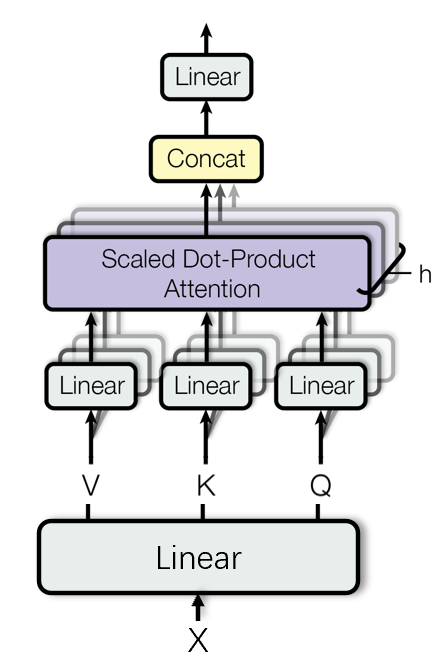
Figure 10: Multi-Head Self-Attention
打分函数使用 s ( Q , K ) = Q K ⊺ s(Q,K)=Q K^\intercal s(Q,K)=QK⊺ 的话,需要保证 d m o d e l Q = d m o d e l K d_{modelQ}=d_{modelK} dmodelQ=dmodelK
在变换得到Q-K-V之后的流程就和Multi-Head Attention一样了,不再过多叙述了。
[!IMPORTANT]
小结(如Figure 11):从非端到端的思维来看整个Multi-Head Self-Attention的话,模型的输入是 X ∈ R n × d x X\in\mathbb R^{n\times d_x} X∈Rn×dx,会通过线性层映射为 Q u e r y ∈ R n × d m o d e l Q Query\in\mathbb R^{n\times d_{modelQ}} Query∈Rn×dmodelQ、 K e y ∈ R n × d m o d e l K Key\in\mathbb R^{n\times d_{modelK}} Key∈Rn×dmodelK、 V a l u e ∈ R n × d m o d e l V Value\in\mathbb R^{n\times d_{modelV}} Value∈Rn×dmodelV,输出是 M u l t i H e a d ∈ R n × d M u l A t t MultiHead\in\mathbb R^{n\times d_{MulAtt}} MultiHead∈Rn×dMulAtt。
!!!我们在这里写的输出维度是 M u l t i H e a d ∈ R n × d M u l A t t MultiHead\in\mathbb R^{n\times d_{MulAtt}} MultiHead∈Rn×dMulAtt,在Self-Attention中的输出维度是 A t t ∈ R n × d v Att\in\mathbb R^{n\times d_v} Att∈Rn×dv,这里的长度 n n n 都和 X 匹配,而通常也会让 d M u l A t t = d v \boldsymbol{d_{MulAtt}=d_v} dMulAtt=dv 来方便计算和模型交叉使用。
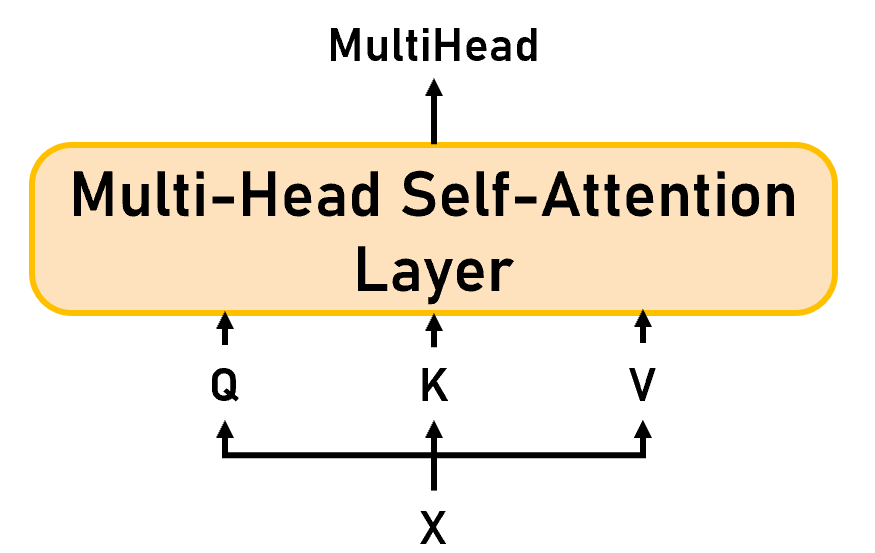
Figure 11: Multi-Head Self-Attention Layer
2 总结(Summary)
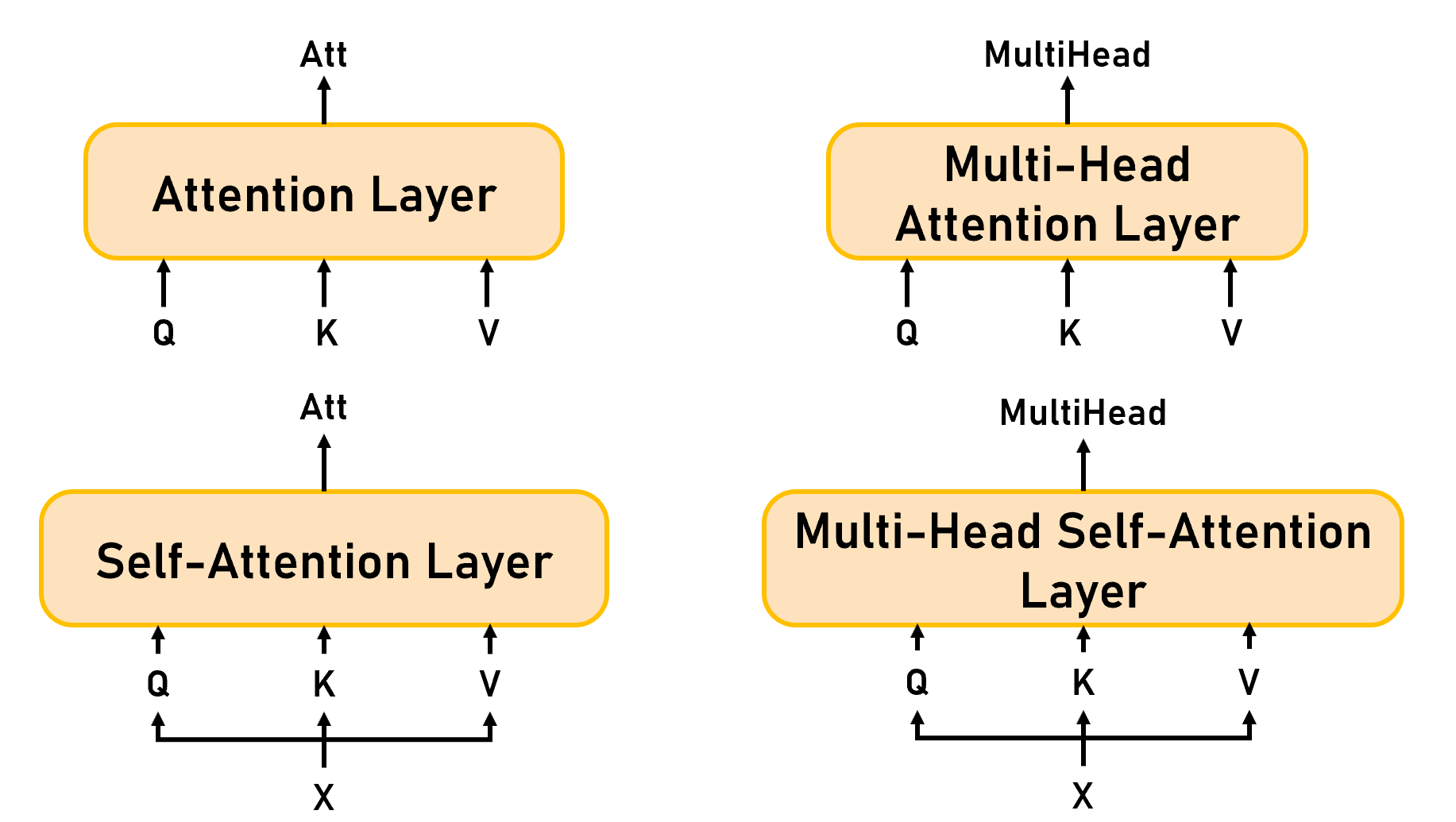
Figure 12: Attention Summary
















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









