







文章目录
1.常用基本函数
1.1 替换函数
pandas 中的替换函数可以归纳为三类:映射替换、逻辑替换、数值替换。
1.1.1 映射替换
- 映射替换包含
replace、方法str.replace、cat.codes
- 使用
replace方法进行值的替换:
# 创建一个示例 DataFrame
data = {'Category': ['A', 'B', 'A', 'C', 'B']}
df = pd.DataFrame(data)
# 使用 replace 方法将 'A' 替换为 'X','B' 替换为 'Y','C' 替换为 'Z'
df['Category'] = df['Category'].replace({'A': 'X', 'B': 'Y', 'C': 'Z'})
print(df)

- 使用
str.replace方法进行字符串替换:
# 创建一个示例 DataFrame
data = {'Text': ['Hello, World!', 'Goodbye, World!']}
df = pd.DataFrame(data)
# 使用 str.replace 方法将 'World' 替换为 'Universe'
df['Text'] = df['Text'].str.replace('World', 'Universe')
print(df)

- 使用
cat.codes方法进行分类列的编码:
# 创建一个示例 DataFrame
data = {'Category': ['A', 'B', 'A', 'C', 'B']}
df = pd.DataFrame(data)
# 使用 cat.codes 方法将分类列编码为整数
df['Category_Code'] = df['Category'].astype('category').cat.codes
print(df)

replace 方法用于替换指定的值,str.replace 方法用于替换字符串中的特定子串,而 cat.codes 方法用于对分类列进行编码为整数。
1.1.2 逻辑替换
逻辑替换包括了 where 和 mask,这两个函数是完全对称的:where 函数在传入条件为 False 的对应行进行替换,而 mask 在传入条件为 True 的对应行进行替换,当不指定替换值时,替换为缺失值。
对于 Pandas 中的逻辑替换,where 和 mask 函数是完全对称的,它们用于根据条件来替换数据,但替换的方向是相反的,同时,它们还可以用于在不指定替换值时将数据替换为缺失值。
where函数:where函数会在传入条件为False的对应行进行替换。- 当不指定替换值时,默认将满足条件为
False的元素替换为缺失值(NaN)。
data = {'A': [1, 2, 3, 4, 5]}
df = pd.DataFrame(data)
# 将满足条件 A > 3 的元素替换为缺失值
df['A'] = df['A'].where(df['A'] <= 3)
print(df)

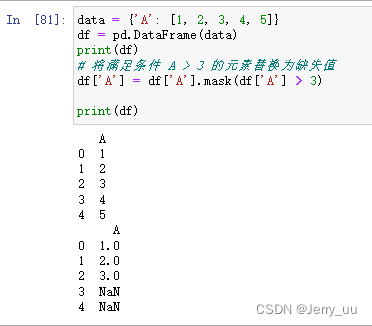
mask函数:mask函数会在传入条件为True的对应行进行替换。- 当不指定替换值时,默认将满足条件为
True的元素替换为缺失值(NaN)。
data = {'A': [1, 2, 3, 4, 5]}
df = pd.DataFrame(data)
print(df)
# 将满足条件 A > 3 的元素替换为缺失值
df['A'] = df['A'].mask(df['A'] > 3)
print(df)
data = {'A': [1, 2, 3, 4, 5]}
df = pd.DataFrame(data)
print(df)
# 将满足条件 A > 3 的元素替换为'ww'
df['A'] = df['A'].mask(df['A'] > 3,'ww')
print(df)

where 和 mask 在传入条件的方向上是完全对称的,如果不指定替换值,默认会将满足条件的元素替换为缺失值。
1.1.3 数值替换
- 数值替换包含了
round,abs,clip方法,它们分别表示取整、取绝对值和截断
在 Pandas 中,你可以使用round、abs和clip方法来进行数值替换和操作。这些方法用于处理数值数据的不同方面。
round方法:round方法用于将数值数据四舍五入到指定的小数位数。- 可以指定小数位数作为参数,如果不指定,则默认为0,即取整数。
- 该方法适用于 Series 和 DataFrame。
示例:
data = {'Value': [3.14159, 2.71828, 1.61803]}
df = pd.DataFrame(data)
# 将数值数据取整到两位小数
df['Value'] = df['Value'].round(2)
print(df)
abs方法:abs方法用于获取数值数据的绝对值。- 该方法适用于 Series 和 DataFrame。
示例:
data = {'Value': [-3, 2, -1]}
df = pd.DataFrame(data)
# 获取数值数据的绝对值
df['Value'] = df['Value'].abs()
print(df)
clip方法:clip方法用于将数值数据限制在指定的范围内。- 可以指定下限和上限作为参数,如果数值小于下限,则替换为下限;如果数值大于上限,则替换为上限。
- 该方法适用于 Series 和 DataFrame。
示例:
data = {'Value': [5, 10, 15]}
df = pd.DataFrame(data)
# 将数值数据限制在范围 [0, 10] 内
df['Value'] = df['Value'].clip(lower=0, upper=10)
print(df)
round 用于四舍五入,abs 用于获取绝对值,clip 用于将数值限制在指定范围内。
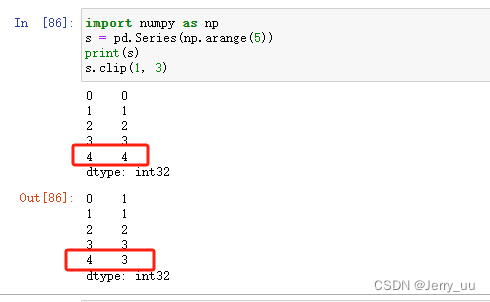
在 clip 中,超过边界的只能截断为边界值,如果要把超出边界的替换为自定义的值,应当如何做?
s = pd.Series(np.arange(5))
s.clip(1, 3)
small, big = -999, 999
s.where(s<=3, big).where(s>=1, small)

1.2 排序函数
排序共有两种方式,其一为值排序,其二为索引排序,对应的函数是 sort_values 和 sort_index 。
sort_values方法:sort_values方法用于按照指定列的值对 DataFrame 进行排序。- 可以指定一个或多个列,以及排序的顺序(升序或降序)。
- 该方法返回一个新的 DataFrame,不会修改原始 DataFrame。
示例:
- 单个列
import pandas as pd
data = {'A': [3, 1, 2], 'B': [6, 5, 4]}
df = pd.DataFrame(data)
# 按照 'A' 列的值升序排序
sorted_df = df.sort_values(by='A', ascending=True)
print(sorted_df)

- 多个列
对A排完序后根据A的结果对B排序,多列排序列和列之间并不是独立的,需要参考顺序
import pandas as pd
data = {'A': [3, 1, 2, 2], 'B': [6, 5, 4, 7], 'C': [9, 8, 7, 6]}
df = pd.DataFrame(data)
# 按照 'A' 列升序排序,然后按照 'B' 列降序排序
sorted_df = df.sort_values(by=['A', 'B'], ascending=[True, False])
print(sorted_df)

其中第一列id会因为对A,B排序的原因打乱,想从新排序id使用reset_index(drop=True)
import pandas as pd
data = {'A': [3, 1, 2, 2], 'B': [6, 5, 4, 7], 'C': [9, 8, 7, 6]}
df = pd.DataFrame(data)
# 按照 'A' 列升序排序,然后按照 'B' 列降序排序
sorted_df = df.sort_values(by=['A', 'B'], ascending=[True, False])
# 重新设置索引,保持原始顺序
sorted_df = sorted_df.reset_index(drop=True)
print(sorted_df)
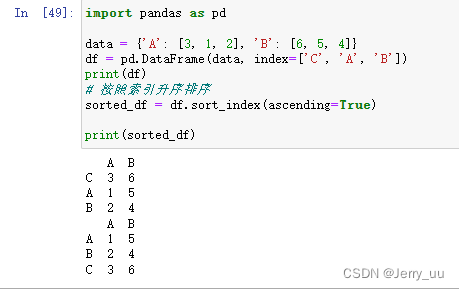
sort_index方法:sort_index方法用于按照索引对 DataFrame 进行排序。- 可以指定排序的顺序(升序或降序)。
- 该方法返回一个新的 DataFrame,不会修改原始 DataFrame。
示例:
import pandas as pd
data = {'A': [3, 1, 2], 'B': [6, 5, 4]}
df = pd.DataFrame(data, index=['C', 'A', 'B'])
# 按照索引升序排序
sorted_df = df.sort_index(ascending=True)
print(sorted_df)
这两种排序方法允许你按照不同的标准对 DataFrame 进行排序。sort_values 用于按照列的值排序,而 sort_index 用于按照索引排序。你可以根据需要选择其中一种方法来排序你的数据。
2. 窗口对象
pandas 中有 3 类窗口,分别是滑动窗口 rolling 、扩张窗口 expanding 以及指数加权窗口 ewm 。
2.1滑窗对象
要使用滑窗函数,就必须先要对一个序列使用 .rolling 得到滑窗对象,其最重要的参数为窗口大小 window
s = pd.Series([1,2,3,4,5])
roller = s.rolling(window = 3)
roller

在 Pandas 中,.rolling() 方法用于创建一个 “滚动窗口” 对象。这个对象可以用于计算滚动或移动的统计信息。当对 Pandas 的 Series 或 DataFrame 使用 .rolling() 方法时,实际上在指定一个特定的窗口大小,以便在这个窗口内进行各种计算。
s=pd.Series([1,2,3,4,5])创建了一个包含数字 1 到 5 的 Pandas Series。roller=s.rolling(window=3)创建了一个滚动窗口对象,窗口大小为
3。这意味着在进行任何计算时(如求和、平均等),都会在这个窗口内进行。窗口会从 Series 的开始处逐渐向后滚动,每次移动一位。
这里的窗口大小为 3意味着在任何时刻,计算都会基于当前位置和之前两个元素(共三个元素)。例如:
- 第一个窗口包括元素 [1, 2, 3]。
- 第二个窗口包括元素 [2, 3, 4]。
- 第三个窗口包括元素 [3, 4, 5]。
请注意,对于 Series 的前两个元素(1 和 2),由于无法形成完整的三个元素窗口,所以在默认情况下,对这些位置的任何滚动计算都会返回 NaN(不是数字)。这种行为可以通过设置 .rolling() 方法的参数来调整。
2.1.1类滑动窗口函数
shift, diff, pct_change 是一组类滑窗函数,它们的公共参数为 periods=n ,默认为 1,分别表示取向前第 n个元素的值、与向前第 n 个元素做差(与 Numpy 中不同,后者表示n阶差分)、与向前第 n 个元素相比计算增长率。这里的n 可以为负,表示反方向的类似操作。
在 Pandas 中,使用 s.rolling(3).apply(lambda x: list(x)[0]) 的操作是对 s 这个 Series 应用一个大小为3的滚动窗口,并在每个窗口上执行一个自定义的函数。
这里是对每个窗口执行的函数的详细说明:
lambda x: list(x)[0]: 这是一个匿名函数,它将窗口中的元素转换为列表,并返回这个列表的第一个元素。
当你对 Series s 应用 .rolling(3),它会创建一个滚动窗口,每个窗口包含当前元素和它前面的两个元素(共三个)。然后,apply() 方法将这个 lambda 函数应用于每个窗口。由于 lambda 函数返回每个窗口的第一个元素,所以这个操作的结果将是每个窗口的第一个元素的序列。
对于 Series s = pd.Series([1, 2, 3, 4, 5]),这个操作的结果将是:
对于第一个和第二个窗口,没有足够的元素来形成完整的三个元素窗口,所以这些位置的结果可能是 NaN(取决于 apply 方法的具体实现)。
- 对于第三个窗口 [
1, 2, 3],结果是 1。 - 对于第四个窗口 [
2, 3, 4],结果是 2。 - 对于第五个窗口 [
3, 4,5],结果是 3。
因此,最终的结果可能类似于一个新的 Series,包含值 [NaN, NaN, 1, 2, 3]。
这些方法是 Pandas 中用于处理时间序列数据或计算数据差异和变化的常见方法。
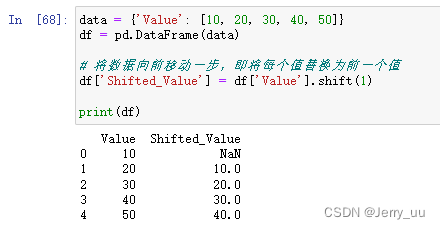
shift方法:shift方法用于将数据向前或向后移动指定数量的时间步(行)。- 可以指定移动的时间步数作为参数,默认为1。
- 该方法适用于 Series 和 DataFrame。
示例:
data = {'Value': [10, 20, 30, 40, 50]}
df = pd.DataFrame(data)
# 将数据向前移动一步,即将每个值替换为前一个值
df['Shifted_Value'] = df['Value'].shift(1)
print(df)
diff方法:diff方法用于计算相邻数据之间的差异。- 可以指定计算的时间步数作为参数,默认为1。
- 该方法适用于 Series 和 DataFrame。
示例:
data = {'Value': [10, 20, 30, 40, 50]}
df = pd.DataFrame(data)
# 计算相邻数据之间的差异
df['Diff'] = df['Value'].diff()
print(df)
pct_change方法:pct_change方法用于计算相邻数据之间的百分比变化。- 可以指定计算的时间步数作为参数,默认为1。
- 该方法适用于 Series 和 DataFrame。
示例:
data = {'Value': [10, 20, 30, 40, 50]}
df = pd.DataFrame(data)
# 计算相邻数据之间的百分比变化
df['Pct_Change'] = df['Value'].pct_change() * 100
print(df)
用滑动窗口重写类滑动窗口函数
- shift
data = {'Value': [10, 20, 30, 40, 50]}
df = pd.DataFrame(data)
df['Value'].rolling(3).apply(lambda x:list(x)[0])

- diff
data = {'Value': [10, 20, 30, 40, 50]}
df = pd.DataFrame(data)
df.rolling(2).apply(lambda x:list(x)[-1]-list(x)[0])

- pct_change
data = {'Value': [10, 20, 30, 40, 50]}
df = pd.DataFrame(data)
def my_pct(x):
L = list(x)
return L[-1]/L[0]-1
df.rolling(2).apply(my_pct)

3.练习
3.1 Ex1:口袋妖怪数据集
现有一份口袋妖怪的数据集,下面进行一些背
https://github.com/datawhalechina/joyful-pandas
感觉DataFrame很像数据库的表,然后对这个DF对象的操作也很像sql
现有一份口袋妖怪的数据集,下面进行一些背景说明:
• # 代表全国图鉴编号,不同行存在相同数字则表示为该妖怪的不同状态
• 妖怪具有单属性和双属性两种,对于单属性的妖怪,Type 2 为缺失值
• Total, HP, Attack, Defense, Sp. Atk, Sp. Def, Speed 分别代表种族值、体力、物攻、防御、特攻、特
防、速度,其中种族值为后 6 项之和

- 对 HP, Attack, Defense, Sp. Atk, Sp. Def, Speed 进行加总,验证是否为 Total 值。
- 对于 # 重复的妖怪只保留第一条记录,解决以下问题:
( a ) 求前三多数量对应的种类
求这张表前三的属性,用py的切片
dp_dup['Type 1'].value_counts().index[:3]
( b ) 求第一属性和第二属性的组合种类
attr_dup = dp_dup.drop_duplicates(['Type 1', 'Type 2'])
( c ) 求尚未出现过的属性组合
L_full = [i+' '+j if i!=j else i for i in df['Type 1'].unique() for j in df['Type 1'].unique()]
L_part = [i+' '+j if not isinstance(j, float) else i for i, j in zip(attr_dup['Type 1'], attr_dup['Type 2'])]
res = set(L_full).difference(set(L_part))
-
L_full列表的生成:df['Type 1'].unique()用于获取 DataFramedf中 ‘Type 1’ 列的唯一值,即不同的属性类型。for i in df['Type 1'].unique()循环遍历这些不同的属性类型,将其表示为i。for j in df['Type 1'].unique()在嵌套循环中再次遍历相同的属性类型,将其表示为j。i+' '+j if i!=j else i用于创建属性组合,如果i和j不相同,就将它们拼接成一个字符串,表示属性组合;否则,只使用i表示属性。- 这个嵌套循环会生成包含所有可能属性组合的
L_full列表。
-
L_part列表的生成:attr_dup['Type 1']和attr_dup['Type 2']是从 DataFrameattr_dup中提取的 ‘Type 1’ 和 ‘Type 2’ 列。for i, j in zip(attr_dup['Type 1'], attr_dup['Type 2'])循环遍历这两列,将它们表示为i和j。i+' '+j if not isinstance(j, float) else i用于创建属性组合,如果j不是浮点数(即非空),就将i和j拼接成一个字符串,表示属性组合;否则,只使用i表示属性。- 这个循环会生成包含已有数据属性组合的
L_part列表。
-
set(L_full)和set(L_part)将列表转换为集合,以去除重复项。 -
res = set(L_full).difference(set(L_part))使用集合操作difference找到在L_full中存在但在L_part中不存在的属性组合,将其存储在res中。 -
len(res)计算res集合的长度,即未在已有数据中出现的属性组合的数量。
3 . 按照下述要求,构造 Series :
( a ) 取出物攻,超过 120 的替换为 high ,不足 50 的替换为 low ,否则设为 mi
df['Attack']
.mask(df['Attack']>120, 'high')
.mask(df['Attack']<50, 'low')
.mask((50<=df['Attack'])&(df['Attack']<=120), 'mid').head()
( b ) 取出第一属性,分别用 replace 和 apply 替换所有字母为大写
df['Type 1'].replace({i:str.upper(i) for i in df['Type 1'].unique()}).head()
df['Type 1'].apply(lambda x:str.upper(x)).head()
( c ) 求每个妖怪六项能力的离差,即所有能力中偏离中位数最大的值,添加到 df 并从大到小排序
df['Deviation'] = df[['HP', 'Attack', 'Defense', 'Sp. Atk','Sp. Def','Speed']]
.apply(lambda x:np.max((x-x.median()).abs()),axis=1)
df.sort_values('Deviation', ascending=False).head()
【参考】
1.https://github.com/datawhalechina/joyful-pandas/tree/master















 294
294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









