






思路:找到用户评论内容的位置,分析各个xhr里的不同,解析html,提取一页数据,通过循环判断拿到整条微博评论内容的数据,存储数据。
分析:网页源代码未找到评论相关的内容,打概率是通过异步加载的,把挡位调到Fetch/XHR,一个个打开在预览里查看,在buildComments里开头的能找到,从负载里明显看到几个xhr的不同:
1,第一个的数据只有6行数据,其余都是8行,且第一个没有max_id和flow的数据
2.中间的max_id每个不同,且最后一个xhr的max_id =0

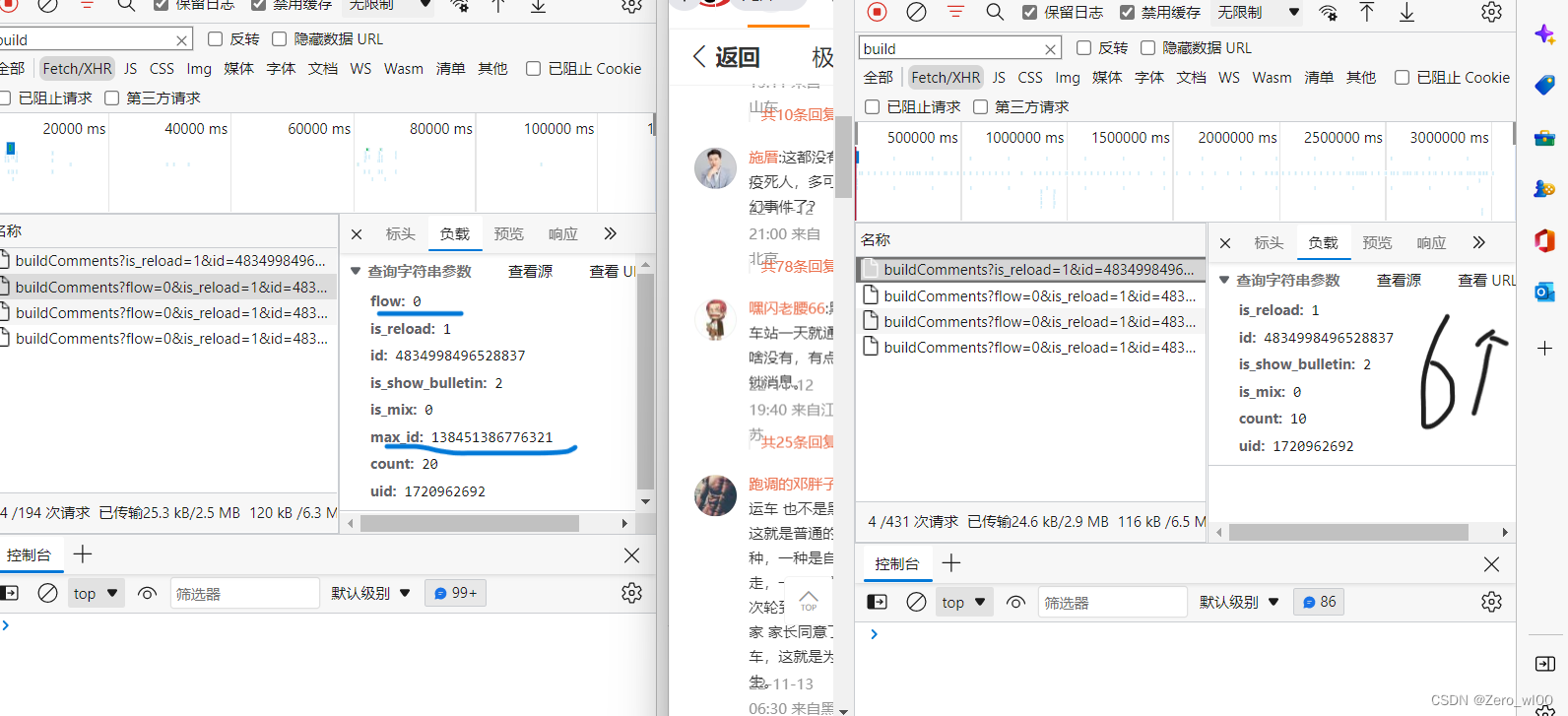
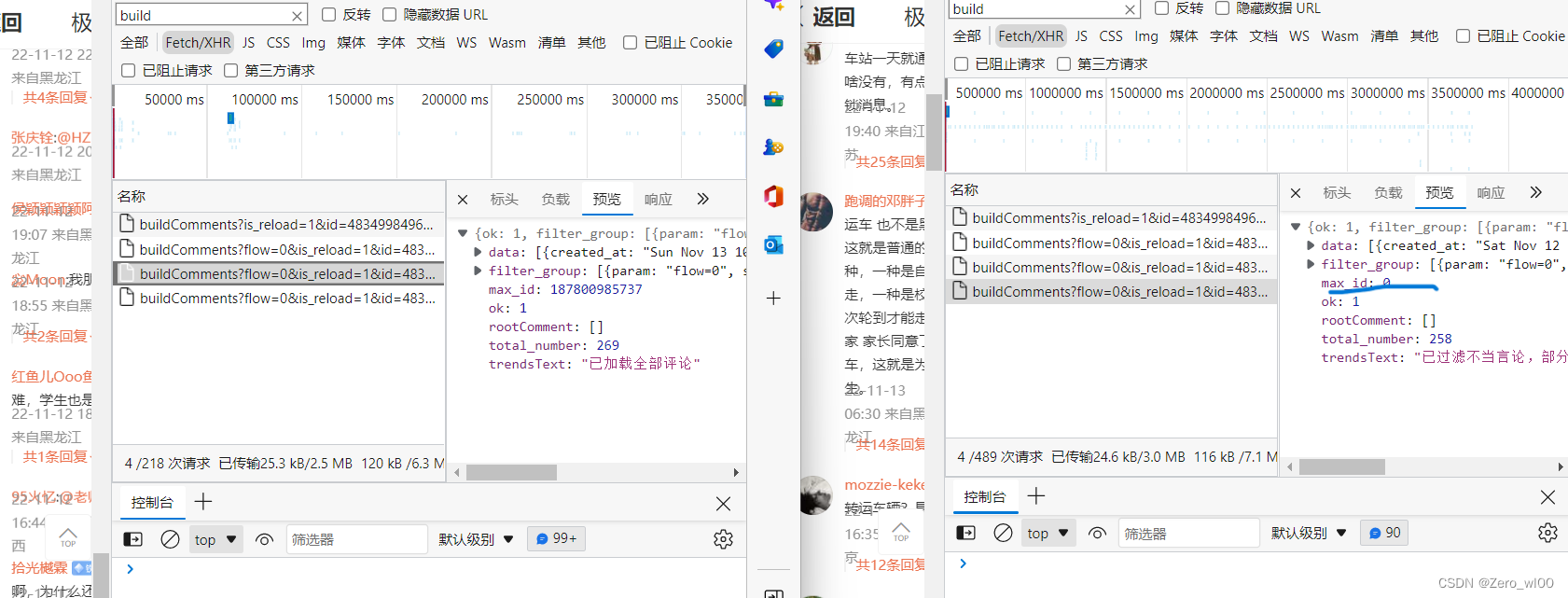
很明显这数据很容易通过json拿到,包括用户 id 日期 评论内容等
上代码:
import requests
import csv #方便存储数据
import time #防止被微博识别爬虫,让速度慢些
f = open("微博评论1.csv",mode ='w',newline='',encoding='utf-8')
csv_writer = csv.DictWriter(f,fieldnames=[
'用户id',
'用户',
'评论日期',
'评论内容'
])
csv_writer.writeheader() #创建表头
#加headers python访问微博时更像是人来操作,防止微博识别爬虫
headers = {
"cookie": "*****",
"referer": "https://weibo.com/1720962692/MeGtbrorP",
"user-agent": "*****",
"x-requested-with": "XMLHttpRequest"
}cooking为了登录 爬取更多数据,ua和cooking涉及隐私不展示了
mid ="" #因为第一页没有max_id ,用来判断,这里不要设置成None
while True: #循环
if mid == "":
n_url = 'https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=4834998496528837&is_show_bulletin=2&is_mix=0&count=10&uid=1720962692'
elif mid ==0: #最后一页的max_id = 0用来结束循环
break
else:
n_url ="https://weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id=4834998496528837&is_show_bulletin=2&is_mix=0&max_id="+str(mid)+"&count=20&uid=1720962692"
resp = requests.get(url=n_url, headers=headers)
datas = resp.json()['data']
print(datas)
mid = resp.json()['max_id']
print(mid)
time.sleep(3)
for data in datas:
dit = {
'用户id': data['user']['id'],
'用户': data['user']['screen_name'],
'评论日期': data['created_at'],
'评论内容': data['text_raw']
}
csv_writer.writerow(dit)
完成展示下结果


















 9103
9103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









