







for self use
目的:建立有一个隐藏层的神经网络来对样本进行分类。
分析:首先查看数据,确定样本的维度(特征数、样本数),可以直接用shape获知,还可以画出数据散点图,初步判断其特征。然后确定构建的神经网络的结构,并初始化参数。接下来就可以进行前向传播、代价函数、反向传播、梯度下降来优化模型。得到模型后,就可以用它进行测试集的测试了。
Code
data checking
import numpy as np
import matplotlib.pyplot as plt
import sklearn
import sklearn.datasets
import sklearn.linear_model
from testCases import *
from planar_utils import plot_decision_boundary, sigmoid, load_planar_dataset, load_extra_datasets
# 在线显示图片
%matplotlib inline插入代码片
np.random.seed(1)
# 散点图
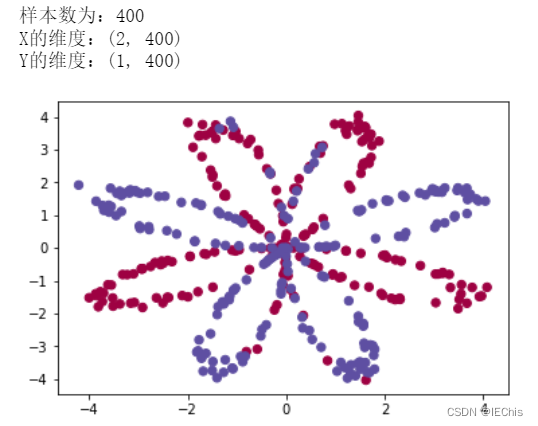
X ,Y = load_planar_dataset()
plt.scatter(X[0,:],X[1,:],c=np.squeeze(Y),s=40,cmap=plt.cm.Spectral)
m = Y.shape[1]
print("样本数为:" + str(m))
print("X的维度:" + str(X.shape))
print("Y的维度:" + str(Y.shape))
set layer size & initialize params
def layer_size(X,Y):
n_x = X.shape[0]
n_h = 4
n_y = Y.shape[0]
return (n_x,n_h,n_y)
def ini_params(n_x,n_h,n_y):
np.random.seed(2)
W1 = np.random.randn(n_h,n_x)*0.01
b1 = np.zeros(shape=(n_h,1))
W2 = np.random.randn(n_y,n_h)*0.01
b2 = np.zeros(shape=(n_y,1))
#使用断言确保数据格式是正确的
assert(W1.shape == ( n_h , n_x ))
assert(b1.shape == ( n_h , 1 ))
assert(W2.shape == ( n_y , n_h ))
assert(b2.shape == ( n_y , 1 ))
params = {
'W1':W1,
'b1':b1,
'W2':W2,
'b2':b2
}
return params
forward propagation
def forppg(X,params):
W1 = params['W1']
b1 = params['b1']
W2 = params['W2']
b2 = params['b2']
Z1 = np.dot(W1,X) + b1
A1 = np.tanh(Z1)
Z2 = np.dot(W2,A1) + b2
A2 = sigmoid(Z2)
assert(A2.shape == (1,X.shape[1]))
cache = {
'Z1':Z1,
'A1':A1,
'Z2':Z2,
'A2':A2
}
return (A2,cache)
cost function
def compute_cost(A2,Y,params):
m = Y.shape[1]
W1 = params['W1']
W2 = params['W2']
logprobs = np.multiply(np.log(A2),Y)+np.multiply((1-Y),np.log(1-A2))
cost = -1/m * np.sum(logprobs)
#squeeze:去掉为1的维度->cost为向量,保证不冗余(维度错误)
cost = float(np.squeeze(cost))
assert(isinstance(cost,float))
return cost
backward propagation
def backppg(params,cache,X,Y):
m = X.shape[1]
W1 = params['W1']
W2 = params['W2']
A1 = cache['A1']
A2 = cache['A2']
dZ2 = A2 - Y
dW2 = (1/m) * np.dot(dZ2,A1.T)
db2 = (1/m) * np.sum(dZ2,axis=1,keepdims=True)
dZ1 = np.multiply(np.dot(W2.T,dZ2),1-np.power(A1,2))
dW1 = (1/m) * np.dot(dZ1,X.T)
db1 = (1/m) * np.sum(dZ1,axis=1,keepdims=True)
grads = {
'dW1':dW1,
'db1':db1,
'dW2':dW2,
'db2':db2
}
return grads
gradient decsent
def update_params(params,grads,alpha=1.2):
W1 = params['W1']
b1 = params['b1']
W2 = params['W2']
b2 = params['b2']
dW1 = grads['dW1']
db1 = grads['db1']
dW2 = grads['dW2']
db2 = grads['db2']
W1 = W1 - alpha * dW1
b1 = b1 - alpha * db1
W2 = W2 - alpha * dW2
b2 = b2 - alpha * db2
params = {
'W1':W1,
'b1':b1,
'W2':W2,
'b2':b2
}
return params
model
def model(X,Y,n_h,num_iters,print_cost=False):
np.random.seed(3)
n_x = layer_size(X,Y)[0]
n_y = layer_size(X,Y)[2]
params = ini_params(n_x,n_h,n_y)
W1 = params['W1']
b1 = params['b1']
W2 = params['W2']
b2 = params['b2']
for i in range(num_iters):
A2,cache = forppg(X,params)
cost = compute_cost(A2,Y,params)
grads = backppg(params,cache,X,Y)
params = update_params(params,grads,alpha=0.5)
if print_cost:
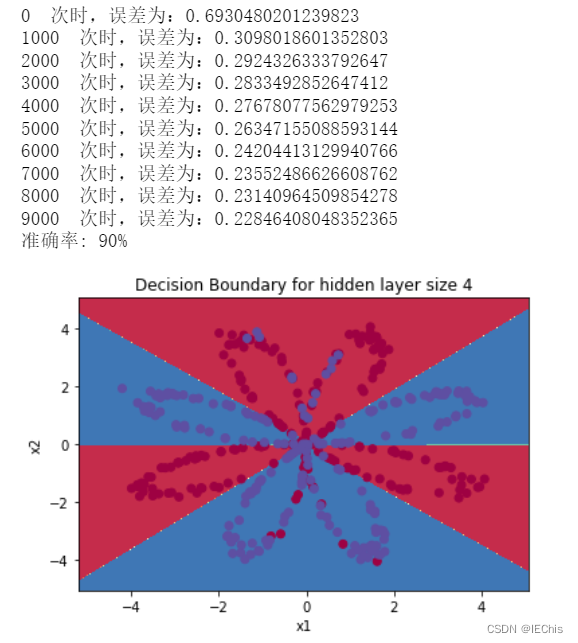
if i%1000 == 0:
print(i," 次时,误差为:" + str(cost))
return params
predict
def predict(params,X):
A2,cache = forppg(X,params)
prediction = np.round(A2)
return prediction
params = model(X,Y,n_h=4,num_iters=10000,print_cost=True)
plot_decision_boundary(lambda x: predict(params,x.T),X,Y)
plt.title("Decision Boundary for hidden layer size " + str(4))
predictions = predict(params,X)
print ('准确率: %d' % float((np.dot(Y, predictions.T) + np.dot(1 - Y, 1 - predictions.T)) / float(Y.size) * 100) + '%')















 6273
6273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









