







1、主题模型 LDA
- 文本类
- 社交
- 推荐
1.1 Introduction
-
有大量的文本资料
-
LDA接受的最小单元是document
-
学习出每个文本的主题
-
设定超参数K
-
output:每个文档会有一个概率的分布,主题分布,选择概率最大的簇作为当前文档分类后的主题。 θ \theta θ

-
词主题:在每个主题下,每个单词出现的概率有多大。每个单词在每个主题下出现的概率。 ϕ \phi ϕ
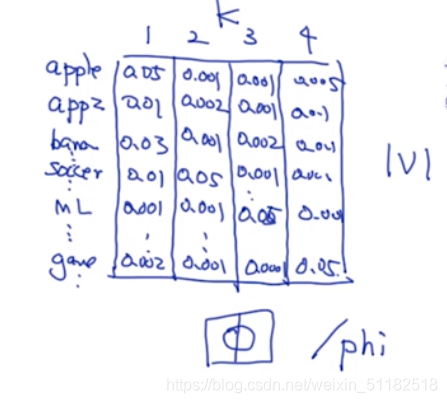
-
Topic 是一个隐变量。
-
对于词主题,把每一个簇中出现概率最大的几个单词拿出来,查看它们的类别,那么簇有很大的概率属于这一个类别。
朴素贝叶斯与LDA的区别
朴素贝叶斯每次只考虑当前的一个topic,只考虑对于当前topic中的词对于topic的影响。
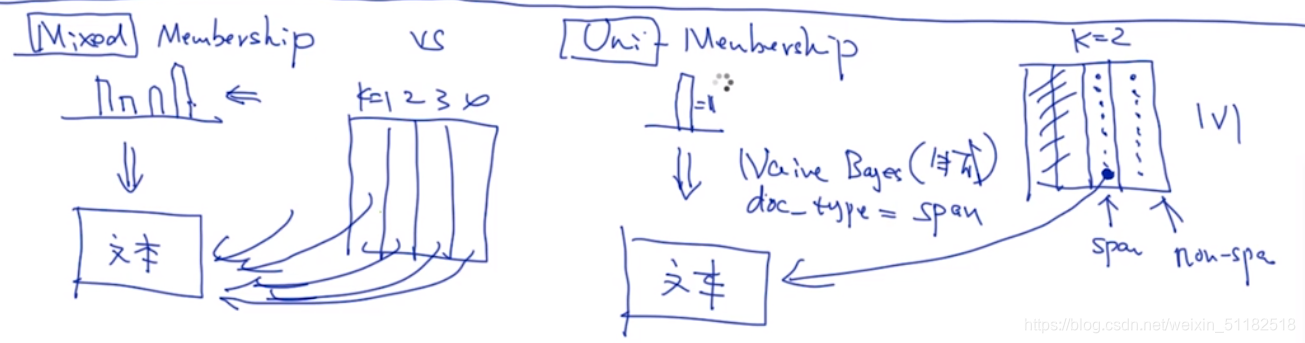
2、不同模型的范畴 Model estimation
贝叶斯模型的定义:
MLE和MAP的都是频率派
通过学习估算出一个最优解
1、MLE
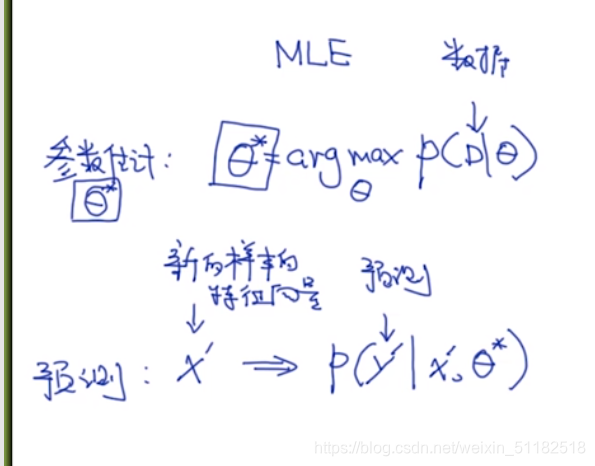
2、MAP:后验概率 既考虑likelihood也考虑先验概率

3、Bayesian
不是估计哪个参数最好,计算所有可能的 θ \theta θ求积分
在训练值已知的情况下,预测出 θ \theta θ的分布。
贝叶斯模型的核心:计算
p ( θ ∣ D ) p(\theta|D) p(θ∣D)的分布概率

3、LDA 预测的过程
计算训练集中所有的模型参数的可能的是很困难的,所以使用蒙特卡洛方法进行近似采样。
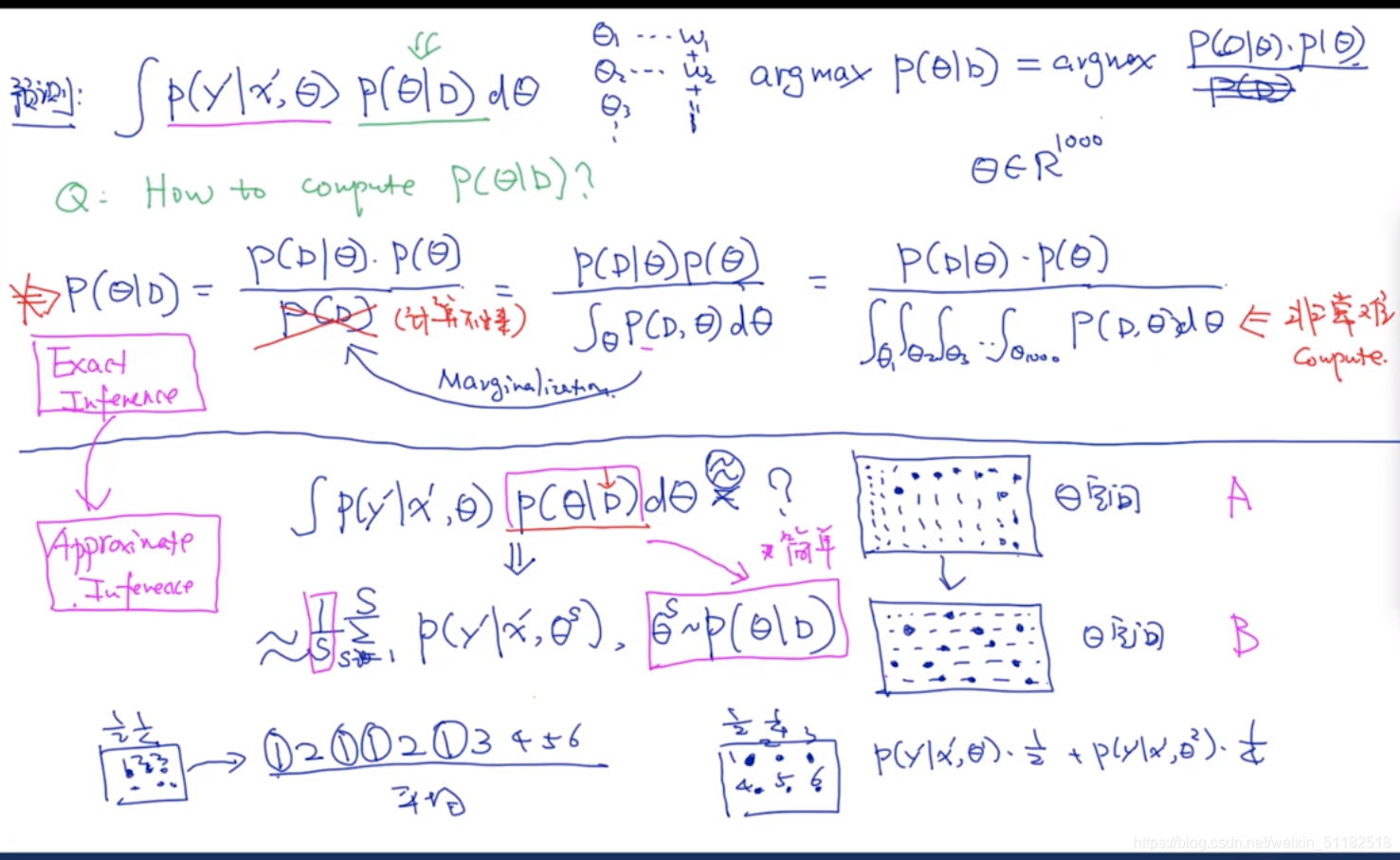
- 先采样
- 再把采样的结果放到预测的里面
4、Monte Carlo Sample
Markov chain Monte Cartlo(增加依赖关系)

5、如何使用LDA
5.1 LDA 的使用
- 加载数据集
- 文本处理(count-based)
- 使用LDA API(n_topics的设定需要调参把)
- 还需要定义 α , β \alpha,\beta α,β
- 画图
5.2 生成文章的process
目标:生成document,写一个文档。
基于参数,会生成文档。
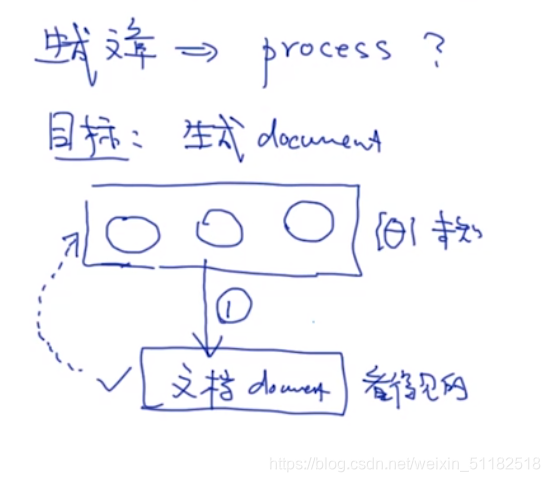
- 第一步:选择主题
case 1:只包含一个主题
case 2:包含多个主题

- 第二步:生成文章
生成list of words,lda不考虑单词的先后顺序
for j=1,2, …,99,100个单词
i)选择一个主题,选择一个合适的单词,比如科技
ii)在科技类别上选择合适的单词,对于科技类概率较大的词分布
针对每一个文档,先采样主题,在根据主体里的词分布,采样单词。
LDA 可以理解为是对文本的聚类,朴素贝叶斯是认定每个文本是属于一个主题,lda是考虑每个文本的主题是考虑了多种主题的概率分布,即每个文本都可能是任意一个主题,只不过成为任意一个主题的概率是不同的。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 739
739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









