








关于数据结构代码题,可以说是让很多同学感到头疼了,书上的代码太繁琐、网上的总结不全面让大家对代码题感到云里雾里,那么这篇文章可能会给大家带来一点启发,因为我自己也是深受代码题的折磨,所以一直想写一篇有关它的总结,希望能够做到全面、简洁,让大家用最快的速度记住代码书写思路、解答出题目、拿到更高的分数。
下面我将先对写代码所需要的基础知识进行总结,然后从两方面展开对代码题的分解,一方面是数据结构定义,另一方面是算法书写,最后通过历年真题验证我们的代码书写思路。
文章目录
前言 基础知识
代码作为一种和计算机交流的语言,要遵守程序语言世界的规范。
(一)把常规代码题解决需要几步
第一小问:设计思想:主要介绍逻辑,告诉老师你用了什么,比如快速排序,重要的是让老师知道用的方法是什么。
第二小问:描述算法
- 写出相应的数据结构:如果说写代码题是建房子,那么相应的数据结构就是建房子用的砖瓦,例如顺序表、链表、树、图等;
- 写出算法代码:利用定义的数据结构,可以根据题目中给出的任务写出相应的C语言代码。一般来说只需要写出以题目中给出的变量作为参数的函数即可,而不需要写出
int main()主函数。
总的来说,代码部分的大体结构如下:
//实际敲代码时要写上,做题可以不写
#include <bits/stdc++.h>
using namespace std;
//常量定义
#define 常量名 常量值
//结构体定义
typedef 实际数据类型 ElemType; //类型重命名
typedef struct 结构体名{
ElemType 结构体属性名;
... ...
}结构体重命名;
//主要函数
返回值类型 函数名(参数类型1 参数1,参数类型2 参数2,... ...){
//变量定义
变量类型 变量名 = 变量值;
//函数主体
函数主体代码;
//返回部分
return 返回值;
}
//main函数,实际敲代码需要有,一般来说做题不需要写
int main(){
函数代码;
}
注意:注释要详实,用来介绍变量、过程的作用,提示老师。对于快速排序和折半查找(注意是否查找成功)可以直接默写,过程函数不需要改动,注意调用的参数即可。
第三小问:求时间和空间复杂度:直接写复杂度,不用过程,要检验是否符合自己所写的代码。
(二)需要知道的C语言表达
1.定义变量
1)普通变量
规范表达:
ElemType 变量名 = 赋值内容
ElemType可以是常见数据类型int、string等,也可以是结构体比如LNode,还可以是指针LNode*、LinkList,变量名可以是单个数据,也可以是数组。
2)数组
关于数组的定义,可以这样表达:
ElemType 变量名[Maxsize]
3)常量
如果要定义常量,使用如下语句:
#define 常量名 值
4)指针
· 一般表达
*——取值(指针),&——取地址(引用),二者互为反操作。
关于指针的表达,我总结出这样一句话来概括:指针等于地址,指针指向对象
指针等于地址,指针指向对象:p是一个指针,指针等于地址;*p是一个对象,指针指向对象
LNode * p,出现其中一个时就是它本身,出现其中两个时缺谁就代表谁,出现三个时表示指针
p是指针,*代表指向,LNode是对象,所以说是指针指向对象;
出现其中一个就是它本身,比如单写一个p,就是指针p,单写一个LNode,就是结点;
出现两个时,比如写*p,就是指缺的那个LNode,也即代表指向的结点;
再如写LNode *,就是指缺的那个p,也即代表指向结点的指针;
三个都出现时,比如LNode * p,就代表p指针本身。
· 链表指针
关于LNode*、LinkList这两者的区别如下:
LNode* p的含义:p是一个指针,它指向LNode类型的变量,它是一个LNode型变量的地址;
LinkList L的含义:L是一个指针,它指向表头LNode类型的变量,它是表头LNode类型变量的地址。
可以说LNode * == LinkList,两者本质是一样的,只不过强调内容不同,LNode* 强调指针指向普通链表结点,LinkList强调指针指向表头结点。
· 指针赋值
再说一下指针的赋值,简单来说就是令两指针的指向相同:
LNode *s = L 表示:s指针指向L指针指向的内容,也即s与L同指向,而不是s指向L,s不是指针的指针。
其他数据类型的赋值是 “值 = 值”,而指针的赋值是 “地址 = 地址”,也即令两指针的指向相同。
· 成员选择
我们有时能看到这样的两种表达:p.a和p->a,它们直接有什么区别呢?先来看一个例子:
typedef struct DATA // 定义一个结构体类型:DATA
{
char key[10]; // 结构体成员:key
char name[20]; // 结构体成员:name
int age; // 结构体成员:age
}DATA;
DATA data; // 声明一个结构体变量
DATA *pdata; // 声明一个指向结构体的指针
// 访问数据操作如下:
data.age = 24; // 结构体变量通过点运算符( . )访问
pdata->age = 24; // 指向结构体的指针通过箭头运算符( -> )访问
总结:
->:成员选择(指针),表示对象指针->成员名,一般用在结构体指针的后面,p->a代表结构体指针p指向的结构体所具的a属性;
. :成员选择(对象),表示对象.成员名,一般用在结构体后面(".“这个运算符可以理解为中文里"的”),p.a代表结构体p的a属性。
例如:
L->data代表指针指向的对象的数据;
L->next代表指针指向的对象的下一个指针;
5)结构体
结构体的定义方式如下:
struct 结构体名{
结构体属性
}
不过这种定义方式存在一些麻烦的问题,就是在使用的时候必须要用这样的定义:
struct 结构体名 结构体对象
需要多写一个struct,很繁琐,所以可以使用这样一种重命名方式:
typedef struct 结构体名{
结构体属性
}结构体别名;
这样每次在使用的时候就可以这样用:
结构体别名 结构体对象
简洁了很多~
2.定义函数
函数无疑是整段代码的主体,最重要的解题逻辑都包含在函数中,如何书写一个函数呢?请看下文。
规范表达:
返回值类型 函数名(参数类型 参数名, 参数类型 参数名... ...){
变量定义;
代码主体;
返回部分;
}
根据函数的表达,在书写一个函数前要确定这样几件事情:
- 返回值类型:如void、int、string、LNode、LinkList等;
- 定义一个能表述函数作用的函数名;
- 确定需要输入进函数的参数;
- 书写函数内部逻辑,包含定义变量、代码主体、返回部分。
在书写代码时,可以在函数外声明变量,这样可以更加简洁,假如题目只要求写出相应函数,则可以现在函数外声明变量,再书写函数,如下:
int i;
int f(){
i = 1;
return i;
}
注意函数的嵌套,可以简化函数逻辑,在作答题目时可以先声明全局变量,然后设置多个函数,进行函数嵌套书写。
3.动态分配语句
在需要用到动态分配的时候,比如要对LinkList L(链表表头指针)进行动态分配,就用到下面的代码:
LinkList L= (LNode*)malloc(sizeof(LNode))
很多同学会觉得这个代码很难记,其实它的逻辑很简单:L是指向表头结点指针,指向LNode类型的数据,所以它的类型为LNode*,malloc函数的含义是开拓一片新的空间,空间大小为initsize(这里为1)个单位,每个单位大小为sizeof(LNode),用以存储链表结点,并使一个指针指向这片空间,然后强制进行类型转换,使得这个指针的类型转换为LNode*,最后使L指针与指向这片空间的指针同指向,这样就做到了使L指向了一个新开辟的链表结点。
(三)复杂度计算
1.时间复杂度:时间开销与问题规模n之间的关系
我总结了一个时间复杂度计算规则:层层(循环、递归)复杂度相加。
什么意思呢?比如有2层循环,第一层循环共执行n次基本语句,每个基本语句执行1次,也就是n个“1”次相加,为n;第二层循环执行log2n次第一次循环,每个第一次循环执行n次,总的也就是log2n个“n”次相加为nlog2n,故时间复杂度为O(nlogn)。

时间复杂度大小排序如下:

2.空间复杂度:空间开销与问题规模n之间的关系
只算与n有关的额外空间开销,与n无关就是O(1),有以下两种情况需要考虑:
(不考虑题目中已经给出的数据所占的空间,比如题目中给出了一个数组这个数组是不计入空间复杂度的)
(1)定义的数组、链表
定义的数组中元素个数以及链表中节点个数都要计入空间复杂度中,单个定义的变量不需要考虑,因为是O(1)。
(2)递归层数
是在递归栈中最多出现多少个过程函数,层数和总次数比较见上面时间复杂度的递归次数计算。
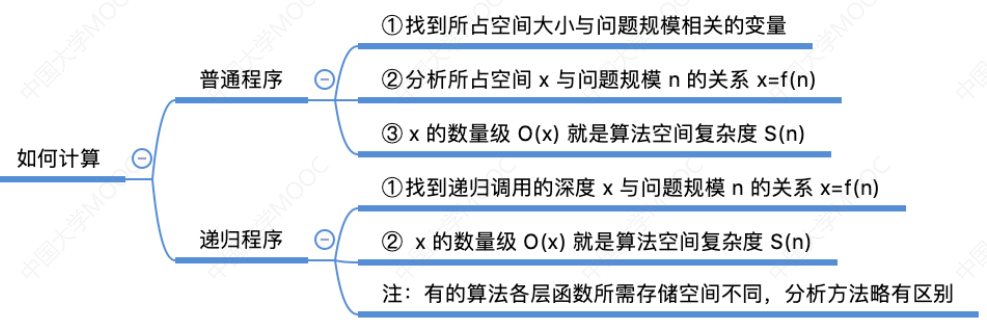
3.题目关于复杂度的要求
共有五种情况:
1)时间上尽可能高效:表示只要求时间复杂度,对空间复杂度不做要求
2)时间和空间两方面都尽可能高效:时间和空间复杂度都要求尽量小,时间复杂度小优先。
3)尽可能高效:要求同(2)。
4)空间复杂度为O(1)且时间上尽可能高效的算法:要求算法的空间复杂度是O(1),时间复杂度尽可能小。
5)没有描述:只要能做出来就行,不要求复杂度是多少,常见于树中。
一、数据结构定义
在书写函数之前,首先要定义数据结构,也就是定义所需要用到的结构体,在数据结构定义中,顺序结构基于数组进行定义,链式结构基于指针进行定义。有一个小妙招,就是在定义一个数据结构之前,先根据其概念将其表示成图,然后根据图定义结构体,这样可以更形象化,不会感觉很乱。
有以下基本数据结构的结构体定义:
(一)线性表(List)
1.顺序表(SqList/SeqList)
概念:用顺序存储方式存储(物理结构)的线性表(逻辑结构)。
图示:

结构体定义:
1)静态分配方式(SqList)
顺序结构基于数组,根据图示想想,在结构体里都要定义什么?首先要定义一个存放数据的数组,然后还得再定义一个当前数组长度,除此之外,还要设置一个常量MaxSize用以表示数组的最大长度,就OK了,那我们来根据结构体的定义方式来试着定义下:
#define MaxSize 50 //定义常量MaxSize为50
typedef struct SqList{
ElemType data[MaxSize]; //用数组存储顺序表
int length; //顺序表长度
}SqList;
2)动态分配方式(SeqList)
一维数组可以是静态分配的,也可以是动态分配的。对数组进行静态分配时,因为数组的大小和空间事先已经固定,所以一旦空间占满,再加入新数据就会产生溢出,进而导致程序崩溃。
而在动态分配时,存储数组的空间是在程序执行过程中通过动态存储分配语句分配的,一旦数据空间占满,就另外开辟一块更大的存储空间,将原表中的元素全部拷贝到新空间,从而达到扩充数组存储空间的目的,而不需要为线性表一次性地划分所有空间。
动态分配方式定义顺序表:
#define InitSize 50 //定义常量InitSize为50
typedef struct SeqList{
ElemType *data; //用数组存储顺序表,定义指向存储空间的指针
int length; //顺序表长度
int capacity; //动态数组的最大容量
}SeqList;
2.链表(LinkList/DLinkList/CLinkList/SLinkList)
用链式存储方式存储(物理结构)的线性表(逻辑结构),用指针一个个链接结点。
1)单链表(LinkList)
顾名思义,单链表就是两个结点之间只有单个指针链接的链表。
图示:

结构体定义:
根据图示,我们想一想要在结构体中定义什么?首先要定义一个数据域,然后再定义一个指针域(指向下一个结点的指针),如下:
typedef struct LNode{
ElemType data; //数据域:保存结点内的数据
struct LNode *next; // 指针域:保存指向下一个结点的指针
int length; //保存链表长度,这个可有可无
}LNode,*LinkList;
对于链表,课本上有各种操作的代码,比如头插法、尾插法、删除结点、加入结点等等,但其实只需要掌握好指针等于地址,指针指向结点这一关系,就不用记住那么多代码。
2)双链表(DLinkList)
顾名思义,双链表就是两个结点之间有双向指针链接的链表。
图示:

结构体定义:
根据图示,我们想一想都要在结构体中定义什么?首先要定义一个数据域,然后再定义两个指针域(指向前后结点的指针),如下:
typedef struct DNode{
ElemType data; //定义数据域
struct LNode *prior,*next; //指向下一个结点的指针
}DNode,*DLinkList
3)循环链表(CLinkList)
顾名思义,循环链表就是首尾有指针链接的链表。
图示:

4)静态链表(SLinkList)
静态链表是用数组来描述线性表的链式存储结构,结点也有数据域data和指针域next,与前面所讲的链表中的指针不同的是,这里的指针是结点在数组中的相对地址(数组下标),又称游标。和顺序表一样,静态链表也要预先分配一块连续的内存空间。
图示:
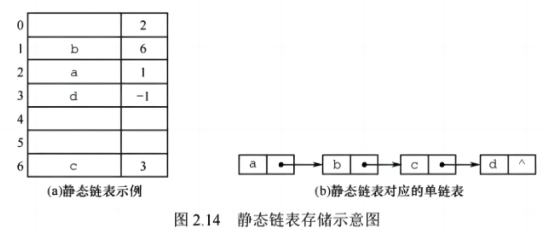
结构体定义:
根据图示,我们想一想都要在结构体中定义什么?首先要定义一个数据域,然后再定义一个指针域(用数组下标表示),如下:
#define MaxSize 50 //静态链表的最大长度
typedef struct{ //静态链表结构类型的定义
ElemType data; //存储数据元素
int next; //下一个元素的数组下标
}SLinkList[MaxSize];
(二)栈和队列(Stack、Queue)
1.栈(Stack)
1)顺序栈(SqStack)
采用顺序结构存储的栈称为顺序栈,顺序结构用数组存储。
图示:
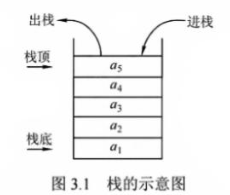
结构体定义:
根据图示,我们来想一想都要在结构体中定义什么呢?首先要定义一个存储数据的数组,并设置其MaxSize,然后再定义一个栈顶指针(用数组下标表示),如下:
#define MaxSize 50 //顺序栈最大长度
typedef struct SqQueue{ //静态链表结构类型的定义
ElemType data[MaxSize]; //存储数据元素的数组
int top; //栈顶元素下标
}SqQueue;
2)链栈(LinkStack)
采用链式结构存储的栈称为顺序栈,链式结构借助指针存储,和链表非常相似。
图示:

结构体定义:
根据图示,我们来想一想都要在结构体中定义什么呢?首先要定义一个数据域,然后再定义一个指针域(指向下一个结点),如下:
typedef struct LSNode{ //链栈定义
ElemType data; //存储数据元素
struct LNode *next; //下一个元素的指针
}LSNode,*LinkStack;
2.队列(Queue)
和栈完全一致,只不过把存储栈顶指针变成了队首指针、队尾指针。
1)顺序队(SqQueue)
采用顺序结构存储的队列称为顺序队列,顺序结构用数组存储。
图示:
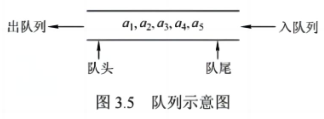
结构体定义:
根据图示,我们来想一想都要在结构体中定义什么呢?首先要定义一个存储数据的数组,并设置其MaxSize,然后再定义队尾指针和队首指针(用数组下标表示),如下:
#define MaxSize 50 //顺序队列最大长度
typedef struct SqQueue{ //顺序队列类型的定义
ElemType data[MaxSize]; //存储数据元素的数组
int head,rear; //栈顶元素下标
}SqQueue;
2)链队(LinkQueue)
采用链式结构存储的队列称为顺序队列,链式结构借助指针存储,和链表非常相似。
图示:
结构体定义:
根据图示,我们来想一想都要在结构体中定义什么呢?首先要定义一个数据域,然后再定义一个指针域(指向下一个结点),如下:
typedef struct LQNode{ //链队定义
ElemType data; //存储数据元素
struct LNode *next; //下一个元素的指针
}LQNode,*LinkQueue;
(三)串
1)顺序串(SString)
定义:采用顺序存储方式的串。
结构体定义:
#define MAXLEN 255 //预定义最大串长为255
typedef struct SString{
char ch[MAXLEN]; //每个分量存储一个字符
int length; //串的实际长度
}SString;
2)堆分配串(HString)
定义:采用堆分配存储方式的串。
结构体定义:
typedef struct HString{
char *ch; //按串长分配存储区,ch指向串的基地址
int length; //串的长度
}HString;
3)链串(String)
定义:采用链式存储方式的串。
结构体定义:
//每个结点一个字符
typedef struct StringNode{
char ch;
struct StringNode *next;
}StringNode,*String;
//每个结点n个字符
typedef struct StringNode{
char ch[n];
struct StringNode *next;
}StringNode,*String;
(四)树和二叉树(Tree、BiTree)
1.树(Tree)
1)孩子表示法(CTree)
定义:孩子表示法是将每个结点的孩子结点都用单链表链接起来形成一个线性结构。
图示:
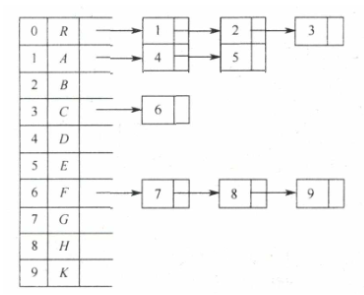
结构体定义:
根据图示,可知需要定义三种结构体:结点、孩子结点、树。
结点中需要定义数据域、指针域(指向第一个孩子结点)
孩子结点中需要定义数据域(存放孩子结点在数组中的位置)
树中需要定义结点数组、结点数和根的位置
#define MAX_TREE_SIZE 100 //树中最多结点数
typedef struct CTNode{
int child; //孩子结点在数组中的位置
struct CTNode *next; //下一个孩子
}CTNode;
typedef struct CTBox{
ElemType data; //结点中储存的数据元素
struct CTNode *firstChild; //第一个孩子
}CTBox;
typedef struct CTree{
CTBox nodes[MAX_TREE_SIZE];
int n,r; //结点数和根的位置
}CTree;
2)双亲表示法(PTree)
定义:这种存储结构采用一组连续空间来存储每个结点 , 同时在每个结点中增设一个伪指针 , 指示其双亲结点在数组中的位置。
图示:
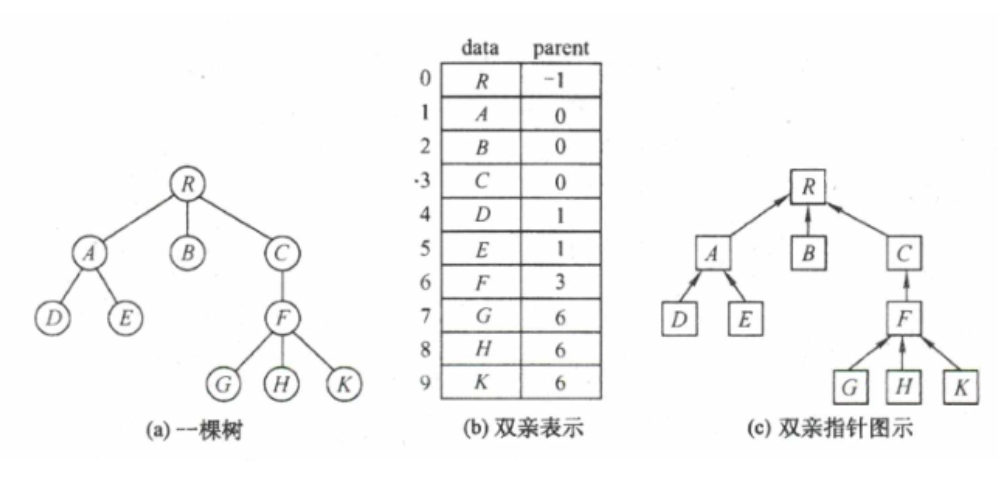
结构体定义:
根据图示,可知需要定义两种结构体:树和结点
结点中需要定义数据域和指针域(数组下标表示)
树种需要定义结点数组、结点总数
#define MAX_TREE_SIZE 100 //树中最多结点数
typedef struct PTNode{ //树的结点定义
ElemType data; //数据元素
int parent; //双亲位置域
}PTNode;
typedef struct PTree{ //树的类型定义
PTNode nodes[MAX_TREE_SIZE]; //双亲表示
int n; //结点数
}PTree;
3)孩子兄弟表示法(CSTree)
定义:孩子兄弟表示法又称二叉树表示法 , 即以二叉链表作为树的存储结构,左孩子右兄弟。
图示:
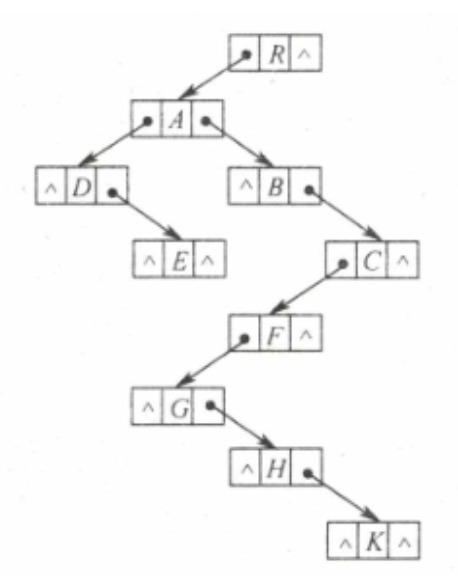
结构体定义:
根据图示,可知只需要定义一个链树:
链树包含以下两个内容:结点内容、左孩子右孩子指针
typedef struct CSNode{
ElemType data;
struct CSNode *lchild,*rchild;
}CSNode,*CSTree
2.二叉树(BiTree)
1)顺序二叉树(SqBiTree)
与动态分配方式定义顺序表的方式相同,在结构体中先定义一个指向存储空间的指针,再定义空间的大小。
图示:
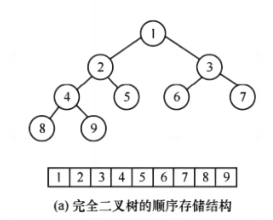
结构体定义:
typedef struct SqBiTree{
ElemType *data;
int length;
}SqBiTree;
2)链式二叉树(LinkBiTree)
和孩子兄弟表示法类似,由于顺序存储的空间利用率较低,因此二叉树一般都采用链式存储结构,用链表结点来存储二叉树中的每个结点。在二叉树中,结点结构通常包括若干数据域和若干指针域,二叉链表至少包含3个域:数据域data、左指针域lchild和右指针域rchild,如图5.5所示。
图示:

结构体定义:
根据图示,可知只需要定义一个链树:
链树包含以下两个内容:结点内容、左孩子右孩子指针
typedef struct BiTNode{
ElemType data; // 数据域
struct BiTNode *lchild, *rchild; // 左 、 右孩子指针
}LinkBiTNode,*LinkBiTree;
3)线索二叉树(ThreadBiTree)
定义:二叉树的线索化是将二叉链表中的空指针改为指向前驱或后继的线索 。 而前驱或后继的信息只有在遍历时才能得到 , 因此线索化的实质就是遍历一次二叉树 。
操作:
InThread(ThreadTree &p,ThreadTree &pre)
PostThread(ThreadTree &p,ThreadTree &pre)
PreThread(ThreadTree &p,ThreadTree &pre)
图示:

结构体定义:
除了要定义两个指针外,还要定义两个线索标志。
typedef struct ThreadNode{
ElemType data; // 数据元素
struct ThreadNode *lchild, *rchild; //左 、 右孩子指针
int Itag, rtag; // 左 、 右线索标志
} ThreadNode , *ThreadTree
遍历二叉树是以一定的规则将二叉树中的结点排列成一个线性序列,从而得到几种遍历序列,使得该序列中的每个结点(第一个和最后一个除外)都有一个直接前驱和直接后继。
关于线索二叉树,考代码题的可能很小,建议在考试之前回到课本看看代码即可,更多可能是考选择题,要牢记线索二叉树的结点结构:若无左子树,令lchild指向其前驱结点:若无右子树,令rchild指向其后继结点。还需增加两个标志域,以标识指针域指向左(右)孩子或前驱(后继)。
总结为一句话就是:左边连左孩子或前驱,右边连右孩子或后继。

(五)图(Graph)
在大题种最常用、常考的是邻接矩阵法和邻接表法。
1)邻接矩阵法(MGraph)
图的邻接矩阵(Adjacency Matrix) 存储方式是用二维数组来表示图。
图示(无向图):
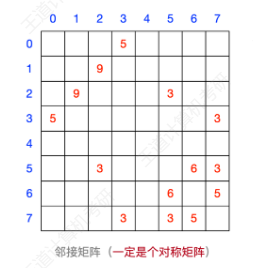
结构体定义:
定义一个二维数组存储结点之间的边相连情况,定义一个一维数组存储结点编号。
#define MaxVertexNum 100 //顶点数目的最大值
typedef char VertexType; //顶点的数据类型
typedef int EdgeType; //带权图中边上权值的数据类型
typedef struct MGraph{
VertexType Vex[MaxVertexNum]; //顶点表
EdgeType Edge[MaxVertexNum][MaxVertexNum]; //邻接矩阵,边表
int vexnum,arcnum; //图当前的顶点数与边数
}MGraph;
2)邻接表法(ALGraph)
定义:图的邻接表法结合了顺序存储和链式存储方法,大大减少了这种不必要的浪费。
图示:
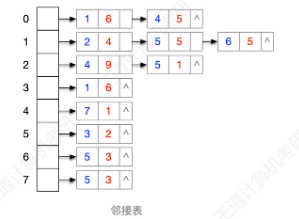
结构体定义:
类似孩子表示法,需要定义三个结构体,结点、边结点、图。
#define MaxSize 100 //顶点数目的最大值
typedef struct ArcNode{ //边结点
int node; //指向的结点位置
int weight; //权值
struct ArcNode *next; //下一条边的指针
}ArcNode;
typedef struct VNode{ //结点
ElemType data; //数据域
ArcNode *first; //指向第一条边的指针
}VNode;
typedef struct ALGraph{ //图
VNode vnode[MaxSize];
int vetexnum,arcnum; //图的顶点数与边数
}ALGraph;
3)邻接多重表法(AMLGraph)
定义:邻接多重表是无向图的另一种链式存储结构。
图示:

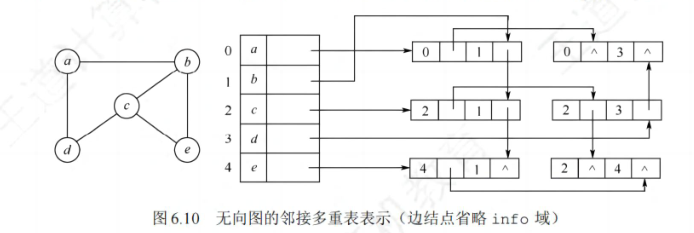
4)十字链表法(OLGraph)
定义:十字链表是有向图的一种链式存储结构。
图示:

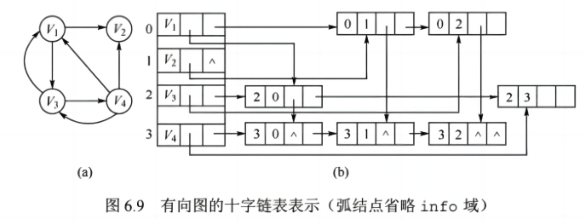
二、算法书写
虽然书上有很多算法代码,但是其实在考试时用到的大多是以下几类,我大致进行了总结,希望以最简洁、最通俗的方式展示给大家,后续如果有遗漏也会不断补充~
(零)提示
大家要记住一句话:顺序表基于数组,链表基于指针。
另外,考试中可直接使用基本操作,建议简要说明接口,如:
//初始化栈
void Initstack(SqStack &S)
//判断栈是否为空
bool StackEmpty(SqStack S)
//新元素入栈
bool Push(SgStack &S,char x)
//栈顶元素出栈,用x返回
bool Pop(SqStack &S,char &x)
不过如果题目想考察的就是基本操作那么就不能这样做了,自己判断一下。
对于数据结构代码题,我总结的经验就是:一,抓住真题,把每一道真题的各种解法做透;二,接受次优,时空复杂度最优的解往往要付出大量的思考时间和书写时间,在考试上来说是得不偿失的,在想不出最优或者最优解很难写的时候,选择次优解才是更好的选择,在平时训练时当然要弄懂最优解,但是在考试的时候就不要那么精益求精啦,毕竟次优解也就扣个两三分;三,融会贯通,接下来讲的方法都只是解题的砖瓦,而解题就像搭房子,要把砖瓦堆叠起来,而不是仅仅用一块砖一块瓦。下面就来看常考的算法:
说明:由于不同题目要求返回值不同,以下部分函数代码不对返回值进行规定,只书写基本代码逻辑;所有涉及到自定义数据类型的都用ElemType类型。
(一)顺序表类
相较于链表,顺序表考频较低,不过基于顺序表的很多常用算法(后面会讲),如折半查找、快速排序、计数排序都会用到顺序表。如果一个题目基于数组且没有用到查找、排序等算法,那它就可以归为顺序表类题目。
顺序表类题目通常会用到以下几种解题思路:遍历、逆置法、双指针法。我们逐一来讲解。
1.暴力解法
顺序表的暴力解法主要分为两种:枚举法、针对无序数组的排序。
枚举法:枚举法是最容易想到的方法,把所有可能的情况都考虑到,然后从中选出符合题目要求的情况,通常使用for循环遍历。
针对无序数组的排序:对于一个无序的数组可以先通过排序把他变成有序再理,排序使用快速排序。考试中直接默写快速排序,然后注意调用快速排序时的参数即可,快速排序代码见后序。
2.遍历
遍历是最常用的办法,只有遍历,才能对顺序表数组中的元素进行判断,看其是否符合要求。
书写遍历代码,首先想个函数名,比如Traverse,那么要输入什么呢?顺序表保存在数组中,所以输入一个数组,再输入数组长度,在函数体书写中,加入判断逻辑,看数组元素是否符合要求。
Traverse(ElemType *A,int n){
for(int i=0;i<n;i++){
if(A[i]符合条件){
执行代码
}
}
}
遍历数组是最基本的操作,只要是涉及到数组的题目都会涉及到,需深入理解。
3.逆置法
有的题目要求对顺序表进行逆置,或者局部对换,如将(a1,a2,a3,……an-1,an)转换为(an-1,an,……a1,a2,a3)这种时候就要用到两次逆置法。逆置法的输入是一个数组,还有逆置的起始下标和结束下标。
Reverse(ElemType *A,int l,int r){
ElemType temp;
while(l < r){
temp = A[l];
A[l++] = A[r];
A[r--] = temp;
}
}
虽然只在2010年真题出现过一次,不过这种顺序表逆置思想是很重要的,思路其实也很简单,注重理解,灵活运用。
4.指针法
常用双指针法来同时锁定两个数据的位置并对其进行操作,在顺序表中,指针并不是真正意义上的指针,而是数组下标,利用“指针”去扫描数组,以达到简化运算的效果,就好像人在做事的时候,如果一只手不够用,就可以用两只手一起完成。
指针法是一种思想,因此没有固定格式,一般来说需要用到for循环,利用数组下标设置“指针”,实现对数组的遍历。
例题可见我的另一篇文章:【刷题实录】双指针法之原地移除元素(C++)
指针法常用在链表,不过如果能在顺序表上运用伪指针,也可以很大程度上简便下来,在2011年真题、2020年真题都出现过,因此要加以重视。
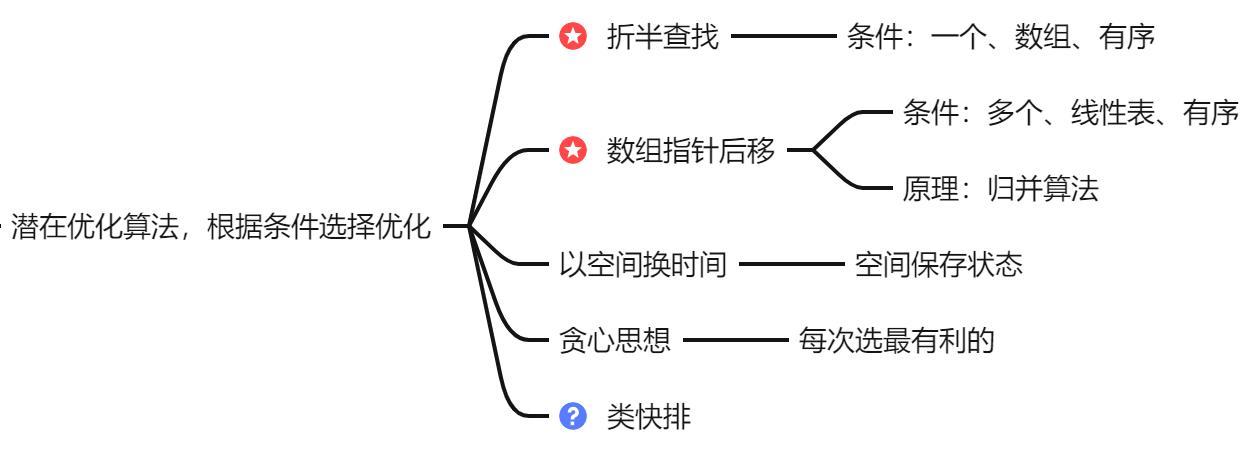
顺序表类题目潜在优化思路:
(二)链表类
顺序表基于数组,链表基于指针,做题时头脑中要有带头结点的单链表图,如下:

相信我,根本不需要记住那么多东西,在理解的基础上,记忆一张带头结点的单链表图、一个指针(熟悉这个表达:LNode* p=L->next),足以解决所有链表问题。
1.暴力解法
顺序表的暴力解法主要分为两种:枚举法、针对无序数组的排序。
枚举法:直接处理,链表的一些题目可以先采用最直接易想的方法,比如要改变链表元素顺序的话,可以将需要重排的元素一个一个拆下来重新插入。这些方法一般看起来比较憨,但是容易想到。
转化为无序数组然后排序:将链表用数组保存,再处理,可以使用数组保存链表中的结点地址或者直接保存数据,然后再按照数组的做题方法操作即可。注意:①如果题目中求的是处理之后的链表;②如果题目要求空间复杂度为O(1);这两种情况都不能使用数组保存链表的结点。
2.几种基本操作
如果不知道插入、删除等操作该怎么写,特别是步骤应该按什么顺序,怕断链,其实有一种很简单的做法:只要把所有涉及到的结点都事先用指针保存下来就不可能断链。可以实现自己约定好当前删除结点就用指针p指向,前一个结点就用pre指向,后一个就用post指向。代码的顺序可以改变(注意,下面的代码在操作之前就已经用对应的指针如pre、p、post指向对应结点了,在写之前请确认)。
这些操作都是最最基本的操作,虽然不会单独出题,但是只要是链表题目,经常会涉及到,因此要牢固掌握。

(1)取出/删除p指向的结点

Get/Delete(LNode* pre, LNode* p, LNode* post){
pre->next = post;
p->next = NULL; //取出p
//free(p); //删除p
}
(2)将p结点插入到pre结点后面

Insert(LNode* pre, LNode* p, LNode* post){
pre->next = p;
p->next = post;
}
(3)头插法插入p

Insert(LinkList L, LNode* p, LNode* post){
p->next = post;
L->next = p;
}
3.遍历
与顺序表的遍历类似,对于链表的遍历需要输入链表头指针,依次对链表中结点的数据域进行判断。对于线性表(数组+链表)的遍历,如果表中元素个数确定就用for循环,否则用while循环。在遍历过程中访问指针p每次都需要后移即p=p->next,不要忘记。
Find(LinkList L){
//已知元素个数n:
LNode* p=L->next;
for (int i=0; i<n; i++){
visit(p); //访问p结点
p=p->next;
}
//不知道元素个数:
LNode* p=L->next;
while (p!=null){
visit(p); //访问p结点
p=p->next;
}
}
遍历是链表的基本操作,在2009年真题、2015年真题都有涉及,要深刻理解。
4.逆置法
链表问题经常用到逆置,这涉及到头插和尾插的转换。
Inverse(Linklist L){
Linklist q; //头插法建立的新链表
q = (LNode*)malloc(sizeof(LNode)); //开辟头结点空间
q->next = NULL;
LNode* p = L->next; //在旧链表上摘结点
while(p!=NULL){
L->next = p->next;
p->next = q->next;
q->next = p;
p = L->next;
}
}
链表逆置是一道经典的链表题,2019年真题有涉及到,需要在理解的基础上掌握。
5.指针法
常用双指针法来同时锁定两个数据的位置并对其进行操作。指针法是一种思想,因此没有固定格式,一般来说就是要初始化多个指针辅助解题,来通过一个例题来感受一下。
题目:已知两个长度分别为m和n带头节点的升序链表L1和L2,若将它们合并为一个长度为m + n的升序链表,头节点为L3。请设计一个时间和空间上尽可能高效的算法,返回新的头节点L1。要求:
(1)给出算法的基本设计思想。
(2)根据设计思想,采用C或C++语言描述算法,关键之处给出注释。
(3)说明你所设计算法的时间复杂度和空间复杂度。
Merge(LNode *L1, *L2){ //数组A、B长度分别为n、m
LNode *p=L1->next, *q=L2->next; //p、q指向L1、L2第一个元素
LNode *r=L1; //新链表头节点为L1,r指向末尾
LNode *pn, *qn; //用来暂存p->next和q->next
while (p!=null && q!=null) //直到有一个链表遍历完
if (p->data<q->data){ //将小的那个数存入新链
pn=p->next; //pn为p下一个元素
r->next=p; //p插入到r后面
p->next=null; //这是新链最后一个元素
r=p; //尾指针r指向最后一个元素
p=pn; //p指向p下一个元素
}
else{
qn=q->next; //qn为q下一个元素
r->next=q; //q插入到r后面
q->next=null; //这是新链最后一个元素
r=q; //尾指针r指向最后一个元素
q=qn; //q指向q下一个元素
}
if (p!=null)
r->next=p; //将剩余部分连到r后面
if (q!=null)
r->next=q; //将剩余部分连到r后面
/*L1是合并后的升序链表,注意此时r已经不是指向尾元素的指针了*/
}
指针法解决链表问题十分常见,例如2009年真题。
(三)树类
树类问题中的前序、中序、后序遍历均采用递归算法,分为链树和顺序树,层序遍历采用迭代算法。可能考察前中后序遍历代码(掌握递归实现即可)、层序遍历代码,求二叉树高度宽度、WPL等,判定一棵二叉树是否为二叉排序树、是否平衡、是否为完全二叉树。总结如下图:

书写树的算法时,要考虑这样几个点:
- 是否有需要向下传递的信息?如深度,如果有,使用函数参数传递;
- 是否有需要向上返回的信息?如高度,如果有,使用函数返回值传递;
- 是否有全局使用的信息?如数组,如果有,定义全局变量;
- 遇到空结点则直接返回,考虑遇到叶结点是否需要特殊的处理?
1.链树
链树的遍历比较简单,直接采用指针进行遍历即可,无非就是一个把“visit”放在哪个位置的问题。
二叉链树的定义:
typedef struct BiTNode (
ElemType data; // 数据域
struct BiTNode *lchild, *rchild; // 左 、 右孩子指针
}BiTNode,*BiTree;
(1)判空
bool isEmpty(BiTree Node){
if(Node->lchild == NULL && Node->rchild == NULL) return true;
return false;
}
(2)前序遍历
PreOrder(BiTNode* Node){
if(isEmpty(Node)) return;
visit(Node);
PreOrder(Node->lchild);
PreOrder(Node->rchild);
}
(3)中序遍历
InOrder(BiTNode* Node){
if(isEmpty(Node)) return;
InOrder(Node->lchild);
visit(Node);
InOrder(Node->rchild);
}
(4)后序遍历
PostOrder(BiTNode* Node){
if(isEmpty(Node)) return;
PostOrder(Node->lchild);
PostOrder(Node->rchild);
visit(Node);
}
2.顺序树
顺序树的遍历稍微麻烦一点,涉及到寻找父节点、左右孩子的问题。
二叉顺序树的定义:
typedef struct BiTree{
ElemType *data;
bool isEmpty; //左右孩子是否为空
}BiTree;
(1)判空
bool Empty(BiTree Node[],int index){
return Node[index].isEmpty;
}
(2)获取左孩子
int getLchild(BiTree Node[],int index){
lchild = index * 2;(下标从1开始)/(index+1) * 2 - 1;(下标从0开始)
return lchild;
}
(3)获取右孩子
int getRchild(BiTree Node[],int index){
rchild = index * 2 + 1;(下标从1开始)/(index+1) * 2 + 1 - 1;(下标从0开始)
return rchild;
}
(4)获取父结点
int getParent(BiTree Node[],int index){
parent = index/2;(下标从1开始)/(index+1)/2 - 1;(下标从0开始)
return parent;
}
(2)前序遍历
PreOrder(BiTree Node[],int index){
if(isEmpty(Node,index)) return;
visit(Node[index]);
PreOrder(Node,getLchild(Node,index));
PreOrder(Node,getRchild(Node,index));
}
(3)中序遍历
InOrder(BiTree Node[],int index){
if(isEmpty(Node,index)) return;
InOrder(Node,getLchild(Node,index));
visit(Node[index]);
InOrder(Node,getRchild(Node,index));
}
(4)后序遍历
PostOrder(BiTree Node[],int index){
if(isEmpty(Node,index)) return;
PostOrder(Node,getLchild(Node,index));
PostOrder(Node,getRchild(Node,index));
visit(Node[index]);
}
3.层序遍历
顺序树的遍历更加麻烦一点,需要借助队列进行操作。这里对二叉链树进行层序遍历。
LeverOrder(BiTNode* Node){
Queue que; //定义队列
BiTNode* cur; //指向当前结点
EnQueue(que, Node); //根节点入队
while(que != NULL){ //在队列不为空的时候
DeQueue(que, cur); //出队
visit(cur); //访问
if(cur->lchild != NULL) EnQueue(que, cur->lchild); //左孩子入队
if(cur->rchild != NULL) EnQueue(que, cur->rchild); //右孩子入队
}
}
2014年真题、2017年真题、2022年真题均考察了树,且是循序渐进的,一开始考察定义,后来考察算法,要引起重视。
(四)图类
图的算法题目前难度不高,可能考察图的表示法代码、深度优先遍历和广度优先遍历,总结如下:

1.深度优先遍历
深度优先:先往深走,层层返回。
对采用邻接表法存储的图进行深度优先遍历:
//深度优先,一条路走到黑
int visit[MAX]={O}; //标记是否访问过结点的数组
ArcNode* p; //辅助指针
void DFS(ALGraph *G, int v){ //输入邻接表法存储的图G、要访问的结点序号v
visit[v]=1; //标记v号结点已访问
printf("%d",v); //输出v号
p=G->vnode[v].first; //令指针指向v号结点指向的第一个结点
while(p!=NULL){ //在p非空的时候
if(visit[p->node]==0) //如果p指向的结点尚未被访问过
DFS(G,p->node); //对p指向的结点继续进行深度优先遍历
p=p->next; //p指向下一个结点
}
}
2.广度优先遍历
广度优先:先往广走,层层下寻。
对采用邻接表法存储的图进行广度优先遍历:
//广度优先,雨露均沾
int visit[MAX]={O};//标记是否访问过结点的数组
ArcNode* p; //辅助指针
SqQueue qu; //辅助队列
int w; //用于接收出队结点
void BFS(ALGraph *G, int v){//输入邻接表法存储的图G、要访问的结点序号v
visit[v]=1; //标记v号结点已访问
printf("%d",v); //输出v号
enQueue(qu,v); //v号结点入队
while (!QueueEmpty(qu)){ //队列不空时
deQueue(qu,w); //pop队首元素
p=G->vnode[w].first; //指向w的第一个邻接点
while(p!=NULL){ //查找w的所有邻接点
if(visit[p->node]==0){ //如果p指向的结点尚未被访问过
visit[p->node]=1; //标记结点已访问
printf("%d",p->node); 输出结点号
enQueue(qu,p->node); //结点入队
}
p=p->next; //p指向下一个结点
}
}
}
2021年真题、2023年真题、2024年真题均考到了图,目前考的都是图的表示法,合理怀疑接下来的几年有关图的代码题将成为一个重点,并且可能越来越深入,毕竟目前尚未考察过深度优先遍历和广度优先遍历,以后可能逐步考到这两个难点,应当予以重视,考前要重点关注深度、广度优先遍历,特别是深度优先遍历。
(五)查找类
1.折半查找(二分查找)
二分查找基于有序顺序表,输入顺序数组和目标值,不断与中间值作比较,直至找到目标值。
int BinarySearch(SeqList L,ElemType key){
int low = 0, high = L.length - 1, mid;
while(low <= high){
mid = (low + high) / 2;
if(L.data[mid] == key) return mid; //查找成功
else if(L.data[mid] > key) high = mid - 1;
else low = mid + 1;
}
return -1;
}
折半查找在2011年真题、2020年真题均有涉及,常作为最优解出现,因此难度较大,可以在理解的基础上尽量答出,答不出折半查找采用次优解就可以,因为写出最优解的难度和耗时较大。
(六)排序类
关于排序算法的详细内容,可以看我之前写的一篇文章,不过常考代码的主要是这三种:
1.快速排序
快排分为两部分:划分、快排主体。
int Partition(SeqList &L,int l,int r){ //划分函数,返回最终位置作为划分点
int p = L.data[l]; //将最左面的值赋给p,作为划分点值
while(l < r){
while(l < r && L.data[r] >= p) r--; //从右向左遍历,找到一个比划分点小的值
L.data[l] = L.data[r];
while(l < r && L.data[l] <= p) l++; //从左向右遍历,找到一个比划分点大的值
L.data[r] = L.data[l];
}
L.data[l] = p; //起始元素的最终定位
return l; //返回划分点位置
}
void QuickSort(SeqList &L,int l,int r){ //递归实现
int mid; //划分点位置
if(l < r){ //一趟快排
mid = Partition(L,l,r); //一次划分
QuickSort(L,l,mid-1); //左边再进行一次快排
QuickSort(L,mid+1,r); //左边再进行一次快排
}
}
快速排序算是一种暴力解,只要涉及到排序或者利用排序可以解决的问题则都可以用快排,在2011年真题、2013年真题、2016年真题、2018年真题均有涉及,因此是必会的,保证能够熟练默写,才能在考场上节省更多时间。
注意:涉及到递归的算法一定注意函数内部是写while还是写if!!!
2.计数排序
void CountSort(ElemType *A,ElemType *B,int n,int k){
int i,c[k];
for(i=0;i<k;i++){
c[i]=0; //初始化计数数组
}
for(i=0;i<n;i++){ //遍历输入数组,统计每个元素出现的次数
C[A[i]]++; //c[A[i]]保存的是等于A[i]的元素个数
}
for(i=1;i<k;i++){
c[i]=C[i]+C[i-1]; //C[x]保存的是小于或等于x的元素个数
}
for(i=n-1;i>=0;i--){ //从后往前遍历输入数组
B[C[A[i]-1]]=A[i]; //将元素A[i]放在输出数组 B[]的正确位置上
C[A[i]]=C[A[i]]-1;
}
}
计数排序本质上是以空间换时间,假如结点值data范围在一定区间内,比如|data|<=n,则可以考虑使用计数排序,计数排序思想在2013年真题、2015年真题、2018年真题均有出现,常常作为次优解,因此要熟悉这种方法。
3.归并
在考试中主要会用到归并操作,用于将多个各自有序的数组合并为一个有序数组,或者对一个无序数组进行归并排序。
//两个有序数组的归并操作
void Merge(int A[], int m, int B[], int n, int C[], int l){
int i=j=k=0;
while(i<m && j<n){
if(A[i] <= B[j]) C[k++]=A[i++];
else C[k++]=B[j++];
}
while(i<m) C[k++]=A[i++];
while(j<n) C[k++]=B[j++];
}
//一个数组的归并排序
#define N 100
void Merge(int A[],int l,int mid,int r){
int i,j,k; //辅助指针
static int B[N]; //加static的目的是无论递归调用多少次,都只有一个B
for(k = l; k <= r; k++){
B[k] = A[k]; //赋值给B
}
for(i = l,j = mid + 1,k = i; i < mid && j <= r; k++){
if(B[i] <= B[j]) A[k] = B[i++];
else A[k] = B[j++];
} //归并
//剩下的元素复制入A
while(i <= mid) A[k++] = B[i++];
while(j <= r) A[k++] = B[j++];
}
void MergeSort(int A[],int l,int r){ //递归完成
if(l < r){
int mid = (l + r)/2;
MergeSort(A,l,mid); //先排序左边
MergeSort(A,mid + 1,r); //再排序右边
Merge(A,l,mid,r); //归并两边
}
}
归并排序的原理就是双指针,在2011年真题有涉及,虽然考的不多,但是还是应该在理解的基础上掌握。
后语 历年真题
说明:
- 每道题目几乎都有暴力解,暴力解可视为最差解,得分最低,最好选择最优解或者次优解;
- 题目中有”要求时间尽量高效“,表示可以牺牲空间换时间;
- 下面的代码中有的是C语言有的是C++,有的可编译运行(带主函数的),有的不可直接编译运行,辛苦大家注意区分,主要理解解题思想即可;
- 在考试的时候一般来说只需要将题目中所给变量作为参数输入进函数即可,不需要写出主函数,不过在我的解答中,有时为了在编译器中运行,便把题目中给的变量条件在主函数中声明了,并在主函数中调用了解题所需函数,大家注意在实际做题中不必写的这么完整,写出解题所需函数即可;
- 如果代码逻辑中涉及计算位置差值、计算中位数、计算数组下标(如计算左右孩子或者父结点的数组下标)等,可以自己设计一个例子进行辅助计算,不需要记公式,很容易混;
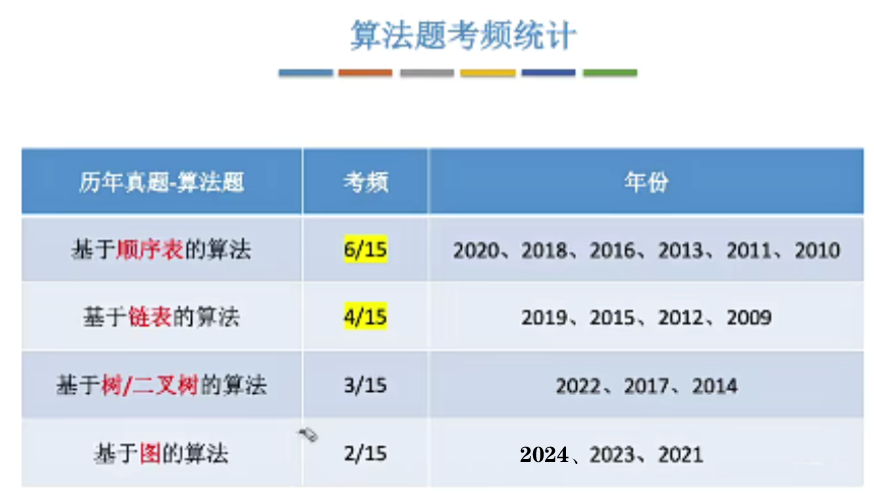
考频统计:
(一)2009(链表)

解题思路:
首先可以判断这是一个链表类题目,链表的结构体已经给出定义,所以我们不需要再进行定义了。
题目要求查找链表中倒数第k个位置上的结点,由于不知道链表长度,从而也就不知道倒数第k个位置上的结点,所以我们首先能够想到的一种解题思路就是遍历两次链表,第一次确定链表长度n,第二次找第(n-k+1)个结点,并输入结点的数据域值。这种方法为次优解(不过其时空复杂度与最优解是相同的,所以也可以视为最优解)。
还有一种思路就是使用指针法,一指针在前,另一指针在后,下标差值为k-1,这样只通过一次遍历即可确认倒数第k个结点,并输出其data域的值。这种方法为最优解。
代码:
最优解:指针法:
算法思想:使用指针法,一指针在前,另一指针在后,下标差值为k-1,这样只通过一次遍历即可确认倒数第k个结点,并输出其data域的值。
int Seek(LinkList list,int k){
LNode *p,*q; //定义双指针
p = q = list; //指向头结点
for(int i = 0; i < k; i++){
p = p->link;
if(p == NULL) return 0;
}
while(p){
p = p->link;
q = q->link;
}
printf("%d",q->data);
return 1;
}
时间复杂度:O(n),遍历一次链表;
空间复杂度:O(1),使用两个指针,没有使用与n有关的额外空间;
次优解:两次遍历:
算法思想:遍历两次链表,第一次确定链表长度n,第二次找第(n-k+1)个结点,并输入结点的数据域值。
int Seek(LinkList list,int k){
LNode *p; //定义遍历指针
int count = 0; //用于计数
//第一次遍历
p = list->link; //指向第一个结点
while(p){
count++; //计数+1
p = p->link;
}
//判断
if(count - k < 0) return 0;
//第二次遍历,输出结点
p = list; //指向头结点
for(int i = 0;i < count - k + 1;i++){
p = p->link;
}
printf("%d",p->data);
return 1;
}
时间复杂度:O(n),遍历一次链表;
空间复杂度:O(1),没有使用与n有关的额外空间;
(二)2010(顺序表)

解题思路:
首先可以判断这是一个顺序表类题目,循环左移可以拆解为三个逆置来解决:先对整体逆置,再对左右两个部分逆置即可完成循环左移。
代码:
最优解:逆置法:
算法思想:先对整体逆置,再对左右两个部分逆置即可完成循环左移。
//逆置函数
void Reverse(int *arr, int l, int r){
int temp; //设置中间变量
while(l < r){
temp = arr[l];
arr[l++] = arr[r];
arr[r--] = temp;
}
}
//左移函数
void leftMove(int *R, int n, int p){
Reverse(R, 0, n-1); //整体逆置
Reverse(R, 0, n-p-1); //将前n-p个元素逆置
Reverse(R, n-p, n-1); //将后p个元素逆置
}
时间复杂度:O(n),相当于遍历了两次数组;
空间复杂度:O(1),未使用与n相关的额外空间;
次优解:辅助数组:
算法思想:创建大小为p的辅助数组S,将R中前p个整数依次暂存在S中,同时将R中后n-p个整数左移,然后将S中暂存的p个数依次放回到R中的后续单元。
时间复杂度:O(n),相当于遍历了两次数组;
空间复杂度:O(p),使用了p个额外空间;
(三)2011(顺序表)

解题思路:
首先可以判断这是一个顺序表类题目,目的是在两个等长有序数组中找出中位数,有两种暴力解法:将两个数组合并入一个新数组进行快速排序然后找出中位数、将两个数组归并入一个新数组然后找出中位数(本质是双指针),这两种方法的时间复杂度都是O(nlogn),可以有更高效的方法,即次优解:指针移动直接找出中位数,考虑到本题的实质是查找,而且是分组有序的数组,所以可以采用折半查找的方法,这样时间复杂度又得到降低,为O(logn)。
代码:
最优解:折半查找:
算法思想:对A、B数组进行折半查找,设L1、R1为数组A的左右查找边界,L2、R2为B的左右查找边界。数组A[L1,R1]和B[L2,R2]的中位数,设为a和b,求序列A、B的中位数过程如下:
①若a<b则舍弃序列A中较小的一半A[L1,mid-1],同时舍弃序列B中较大的一半B[mid+1,R1]。
②若a>=b则舍弃序列A中较大的一半A[mid+1,R1],同时舍弃序列B中较小的一半B[L1,mid-1]。
重复过程①、②,且需要保证数组A、B中的元素个数相同,如果不同则从长的数组中舍弃一个(因为我们取mid时都是向下取整,所以这里舍弃最小的那个值),直到两个序列中均只含一个元素时为止,较小者即为所求的中位数。
void ans(int A[], B[], n){
int mid1, mid2, L1=L2=0, R1=R2=n-1;
while (L1<=R1){ //如果L>=R则退出循环
mid1=(L1+R1)/2;
mid2=(L2+R2)/2; //取中间数,向下取整
if (A[mid1]<B[mid2]){
L1=mid1;
R2=mid2; //更新查找范围
if (R1-L1!=R2-L2)
L1++; //保证R1-L1=R2-L2
}
else{
R1=mid1;
L2=mid2; //更新查找范围
if (R1-L1!=R2-L2)
L2++; //保证R1-L1=R2-L2
}
}
cout<<min(A[L1],B[L2]); //输出A[L1]和B[L2]较小值
}
时间复杂度:O(logn)
空间复杂度:O(1)
次优解:指针法:
算法思想:指针移动直接找出中位数
#include <bits/stdc++.h>
using namespace std;
int main()
{
vector<int> A = {11,13,15,17,19};
vector<int> B = {2,4,6,8,20};
int i,j = 0;
for(int n = 0; n < (A.size()+B.size()+1)/2 - 1; n++){
if(A[i] >= B[j]) j++;
else i++;
}
int mid = min(A[i], B[j]);
cout<<mid<<endl;
return 0;
}
时间复杂度:O(n)
空间复杂度:O(1)
暴力解:归并排序:
算法思想:将两个数组归并入一个新数组然后找出中位数(本质是双指针)
#include <bits/stdc++.h>
using namespace std;
vector<int> merge(vector<int> A, vector<int> B){
vector<int> C;
int i,j = 0;
while(i < A.size() && j < B.size()){
if(A[i] <= B[j]) C.push_back(A[i++]);
else C.push_back(B[j++]);
}
while(i < A.size()){
C.push_back(A[i++]);
}
while(j < B.size()){
C.push_back(B[j++]);
}
return C;
}
int main()
{
vector<int> A = {11,13,15,17,19};
vector<int> B = {2,4,6,8,20};
vector<int> C = merge(A, B);
int mid = C[(C.size()+1)/2-1];
cout<<mid<<endl;
return 0;
}
时间复杂度:O(n)(因为只遍历一次两个数组)
空间复杂度:O(n)(因为新建了数组C)
暴力解:快速排序:
算法思想:将两个数组合并入一个新数组进行快速排序然后找出中位数。
#include <bits/stdc++.h>
using namespace std;
int partion(vector<int>& C, int l, int r){
int temp = C[l];
while(l < r){
while(l < r && C[r] >= temp) r--;
C[l] = C[r];
while(l < r && C[l] <= temp) l++;
C[r] = C[l];
}
C[l] = temp;
return l;
}
void quickSort(vector<int>& C, int l, int r){
int mid;
if(l < r){
mid = partion(C, l, r);
quickSort(C, l ,mid-1);
quickSort(C, mid+1, r);
}
}
vector<int> merge(vector<int> A, vector<int> B){
vector<int> C;
for(int i = 0; i < A.size(); i++){
C.push_back(A[i]);
}
for(int i = 0; i < B.size(); i++){
C.push_back(B[i]);
}
return C;
}
int main()
{
vector<int> A = {11,13,15,17,19};
vector<int> B = {2,4,6,8,20};
vector<int> C = merge(A, B);
//对C进行快速排序
quickSort(C, 0, C.size()-1);
int mid = C[(C.size()+1)/2-1];
cout<<mid<<endl;
return 0;
}
时间复杂度:O(nlogn)
空间复杂度:O(n)
(四)2012(链表)
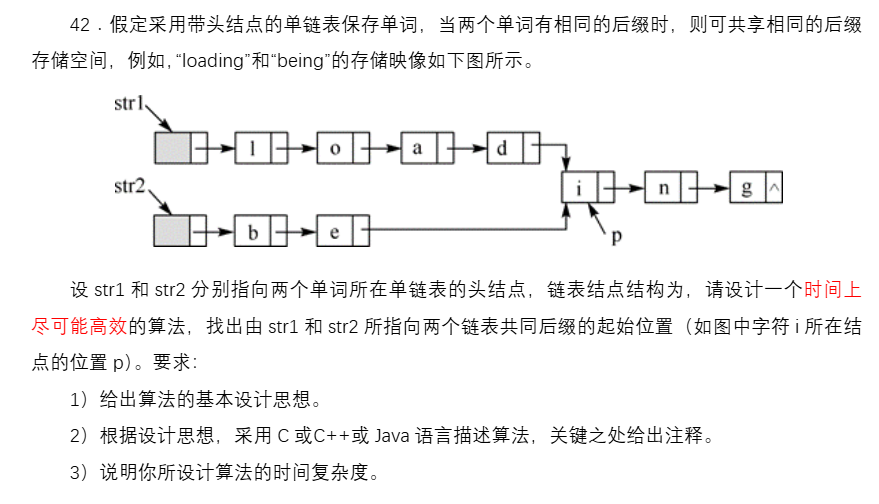
解题思路:可以采用两种暴力解:第一种是枚举法,枚举str1和str2共同后缀起始位置,依次遍历,第二种是将链表转为数组,这样就可以倒着查找共同后缀的起始位置;最优解是双指针法,每个链表设置一个指针,先求出两个链的长度,然后长的链指针往后移动x次(x是长度差的绝对值),使得两链剩余未访问结点数相同,然后两链表的指针同步往后移动比较,直到指向的是同一个结点。
代码:
最优解:双指针法:
算法思想:每个链表设置一个指针,先求出两个链的长度,然后长的链指针往后移动x次(x是长度差的绝对值),使得两链剩余未访问结点数相同,然后两链表的指针同步往后移动比较,直到指向的是同一个结点。
void ans(LinkList str1, LinkList str2){ //两个链表
//计算链表长度
LNode* p = str1->next; //用于计算str1的长度
LNode* q = str2->next; //用于计算str2的长度
int n1,n2 = 0;
while(p != NULL){
n1++;
p = p->next;
}
while(q != NULL){
n2++;
q = q->next;
}
//同步两个指针
if(n1 >= n2){
for(int i = 0; i < (n1-n2); i++){
str1 = str1->next;
}
}
else{
for(int i = 0; i < (n2-n1); i++){
str2 = str2->next;
}
}
//开始同步遍历,输出共同后缀起始
while(str1 != str2){
str1 = str1->next;
str2 = str2->next;
}
if(str1 != NULL){
cout<<str1;
return;
}
else{
cout<<NULL;
return;
}
}
时间复杂度:O(n)
空间复杂度:O(1)
暴力解:枚举str1和str2共同后缀起始位置:
算法思想:枚举str1和str2共同后缀起始位置,依次遍历
void ans(Node* str1, str2){
Node* p=str1->next; //str1的后缀起始位置
Node* q; //之后循环中会赋初值
while (p!=null){
q=str2->next; //每次进入内层循环前要给q赋初值
while (q!=null){
if (p==q){
cout<<p; //后缀完全匹配
return;
}
q=q->next;
}
p=p->next;
}
cout<<null; //无相同后缀,可不写
}
时间复杂度:O(n2)(因为要遍历n个O(n)次)
空间复杂度:O(1)
暴力解:链表转数组,数组保存结点地址:
算法思想:设str1和str2的长度较大的值是n,设置两个新数组S1和S2分别保存str1和str2链中的每个结点的地址(这里用为了方便,从S1[1]和S2[1]开始存,S1[0]和S2[0]作为哨兵,设置不相同)
void ans(Node* str1, str2){
Node* S1[n+1];
Node* S2[n+1]; //保存str1和str2各结点地址
Node* p=str1->next; //str1的后缀起始位置
Node* q=str2->next; //str2的后缀起始位置
Len1=Len2=0;
while (p!=null){
S1[++Len1]=p;
p=p->next;
}
while (q!=null){
S2[++Len2]=q;
q=q->next;
}
if (S1[Len1]!=S2[Len2]){
cout<<null; //无相同后缀,可不写
return;
}
S1[0]=-1;
S2[0]=-2; //S1[0]和S2[0]作为哨兵判断链是否访问完
for (int i=1; i<min(Len1, Len2); i++)
if (S1[Len1-i]!=S2[Len2-i]){
cout<<S1[Len1-i+1]; //输出起始地址
return;
}
}
时间复杂度:O(n)
空间复杂度:O(n)
(五)2013(顺序表)

解题思路:
代码:
最优解:技巧:
算法思想:变量j保存可能的主元素,初始时j=A[0],t=1,从A[1]开始扫描一次数组A,如果j==A[i]则t++,否则t–,如果t<0则更新j=A[i]且t变成1。之后在扫描一次数组A,判断j是否是主元素(m统计该元素出现的个数),如果是则输出j,否则输出-1。
void ans(int A[], n){
int j=A[0], m, t=1; //取A[0]作为可能主元素
for (int i=1; i<n; i++)
if (A[i]==j) t++;
else{
t--;
if (t<0){
j=A[i];
t=1;
}
}
m=0;
for (int i=0; i<n; i++)
if (A[i]==j)
m++;
if (m>n/2) cout<<j; //j是主元素,输出j
else cout<<-1; //j不是主元素,输出-1
}
时间复杂度:O(n)
空间复杂度:O(1)
次优解:以空间换时间:
算法思想:设置一个数组nums[0~n-1]统计每个数字出现的次数,比如nums[i]=1表示数字i出现了1次,遍历一次A数组统计所有数字出现的次数,处理完后扫描一次nums数组找到是否有主元素,如果有则输出主元素,否则返回0。
#include <bits/stdc++.h>
using namespace std;
int main(){
vector<int> A = {1,4,5,5,5,5,7};
int n = 10; //所有数组元素都属于[0, 10)
vector<int> nums(n, 0);
for(int j = 0; j < A.size() ;j++){
nums[A[j]]++;
}
for(int i = 0; i < n; i++){
if(nums[i] > A.size()/2) cout<<i<<endl;
}
return 0;
}
时间复杂度:O(n)
空间复杂度:O(n)
暴力解:快速排序:
算法思想:先快速排序得到升序序列,权值相同的元素都会相邻,主元素如果存在则一定是A[(n-1)/2]扫描一趟数组判断A[(n-1)/2]是否是主元素。
void Qsort(int A[], L, R){ //a数组保存数据,L和R是边界
if (L>=R) return; //当前区间元素个数<=1则退出
int key, i=L, j=R; //i和j是左右两个数组下标移动
把A[L~R]中随机一个元素和A[L]交换 //快排优化,使得基准值的选取随机
key=A[L]; //key作为枢值参与比较
while (i<j){
while (i<j && A[j]>key)
j--;
while (i<j && A[i]<=key)
i++;
if (i<j)
swap(A[i], A[j]); //交换A[i]和A[j]
}
swap(A[L], A[i]);
Qsort(A, L, i-1); //递归处理左区间
Qsort(A, i+1, R); //递归处理右区间
}
void ans(int A[], n){
Qsort(A, 0, n-1);
int t=A[(n-1)/2];
int sum=0;
for (int i=0; i<n; i++)
if (A[i]==t)
sum++;
if (sum>n/2)
cout<<t; //找到主元素
else cout<<-1; //未找到主元素
return;
}
时间复杂度:O(nlogn)
空间复杂度:O(logn)
暴力解:多重循环法:
算法思想:双重循环枚举判断每个元素是否是主元素
void ans(int A[], n){
int m; //m统计当前枚举元素出现次数
for (int i=0; i<n; i++){
m=0; //每次选择元素的时候m要清零
for (int j=0; j<n; j++)
if (A[i]==A[j])
m++;
if (m>n/2){
cout<<A[i]; //找到了主元素
return;
}
}
cout<<-1; //未找到主元素
return;
}
时间复杂度:O(n2)
空间复杂度:O(1)
(六)2014(树)

解题思路:对于此类题目,要注意三个变量的设置:(1)全局变量,特点是全局共享,此题中全局变量为WPL;(2)参数传递,特点是从上至下层层传递,此题中参数为深度;(3)返回值,特点是从下向上返回给父函数,此题中没有,常见返回值如高度。
代码:
最优解:二叉树遍历:
算法思想:先序遍历二叉树,设置全局变量WPL,每次访问到叶子结点时,将他的权值与深度相乘,再累加到WPL中。
int WPL = 0; //全局变量设置,WPL
void preOrder(BTree T, int d){ //二叉树T,深度d
if (p==null) //p是空结点
return;
if (p->left==null && p->right==null) //p是叶结点
WPL+=d*p->weight;
preorder(p->left, d+1); //递归调用左孩子
preorder(p->right, d+1); //递归调用右孩子
}
void ans(BTNode* T){
preorder(T, 0); //根结点深度为0
}
时间复杂度:O(logn)
空间复杂度:O(1)
二叉树结点定义见前文。
(七)2015(链表)
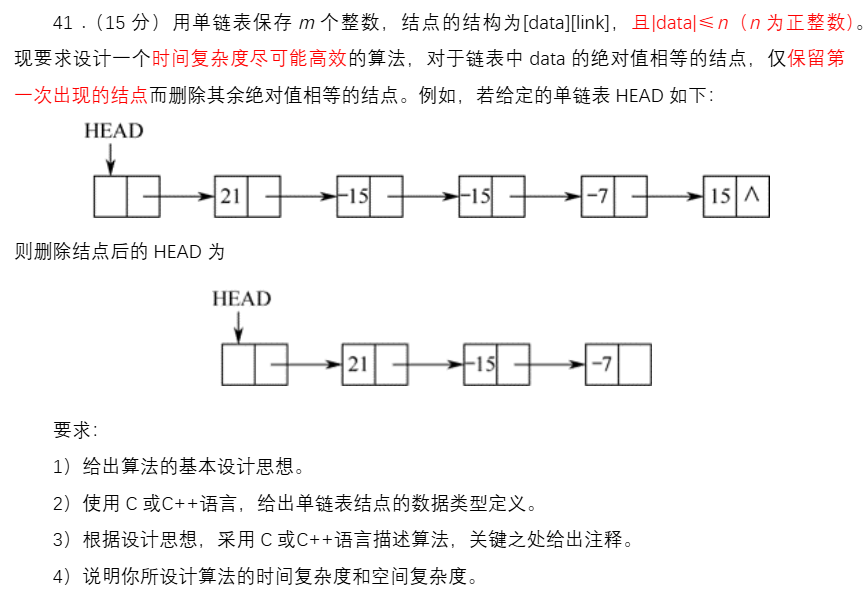
解题思路:
代码:
最优解:空间换时间:
算法思想:data的绝对值≤n,那可以用数组count[0~n]来保存对于每一个绝对值是否出现过,比如count[1]>0表示该绝对值已经出现过了,之后再出现就可以删除当前访问的结点。遍历一次链表,更新count数组以及删除后面重复出现的结点。
void ans(Node* HEAD){
Node* p=HEAD->link; //当前访问结点p
Node* pre=HEAD; //p的前一个结点pre
bool count[n+1]; //可以加上数组初始化
while (p!=null){
if (count[abs(p->data)]==false)
count[abs(p->data)]=true; //p的权值第一次出现
else{ //p的权值前面已经出现过
pre->link=p->link;
free(p);
p=pre;
}
pre=p; //更新pre
p=pre->link; //更新p
}
}
时间复杂度:O(m)
空间复杂度:O(n)
暴力解:枚举,每一个结点都和其他结点比较:
算法思想:两层循环枚举所有结点的两两比较,外层遍历链表中的结点p,内层遍历p之后的结点将和p绝对值相等的结点删除(只保留第一个出现的p)。
void ans(Node* HEAD){
Node* p=HEAD->link; //外层遍历结点p
Node* q, r; //q是r前一个结点
while (p!=null){
q=p; //q从p开始
while (q->link!=null){
r=q->link //r表示待比较结点
if (abs(r->data)==abs(p->data)){
q->link=r->link;
free(r);
}
else q=q->link; //不相同时才修改q
}
p=p->link;
}
}
时间复杂度:O(n2)
空间复杂度:O(1)
(八)2016(顺序表)

解题思路:虽然这个题看上去很繁琐,但其本质起始就是求中位数。可以采用暴力解——快速排序,或者最优解——类快排思想,是对快排的一个优化。
代码:
最优解:类快排思想找中位数枢值:
算法思想:对数组A[0~n-1]进行类似快速排序的做法,在处理左右区间时只处理可能包含中位数的区间,即如果区间的范围是[l, r],则只有l<=n/2-1<=r才会处理该区间。对快排的递归调用稍作修改即可。
void Qsort(int A[], L, R){ //a数组保存数据,L和R是边界
if (L>=R) return; //当前区间元素个数<=1则退出
int key, i=L, j=R; //i和j是左右两个数组下标移动
把A[L~R]中随机一个元素和A[L]交换 //快排优化,使得基准值的选取随机
key=A[L]; //key作为枢值参与比较
while (i<j){
while (i<j && A[j]>key)
j--;
while (i<j && A[i]<=key)
i++;
if (i<j)
swap(A[i], A[j]); //交换A[i]和A[j]
}
swap(A[L], A[i]);
if (n/2-1>=L && n/2-1<=i-1) //n/2-1在左区间范围中
Qsort(A, L, i-1); //递归处理左区间
if (n/2-1>=i+1 && n/2-1<=R) //n/2-1在右区间范围中
Qsort(A, i+1, R); //递归处理右区间
}
void ans(int A[], n){
Qsort(A, 0, n-1);
输出S1:A[0~n/2-1]
输出S2:A[n/2~n-1]
}
时间复杂度:O(n)
空间复杂度:O(logn)
暴力解:快速排序:
算法思想:对数组A[0,n-1]进行快速排序得到升序,然后划分集合,如果是元素数为偶数,中位数划分给S1,如果元素数为奇数,中位数划分给S2。
#include <bits/stdc++.h>
using namespace std;
int partion(vector<int>& C, int l, int r){
int temp = C[l];
while(l < r){
while(l < r && C[r] >= temp) r--;
C[l] = C[r];
while(l < r && C[l] <= temp) l++;
C[r] = C[l];
}
C[l] = temp;
return l;
}
void quickSort(vector<int>& C, int l, int r){
int mid;
if(l < r){
mid = partion(C, l, r);
quickSort(C, l ,mid-1);
quickSort(C, mid+1, r);
}
}
int main(){
vector<int> A = {1,4,5,2,3,6,7};
quickSort(A, 0, A.size()-1);
int n = A.size();
int mid;
if(n%2 == 0) par= (n+1)/2; //如果是偶数则把中位数划分给S1;
if(n%2 == 1) par= (n+1)/2-1; //如果是奇数则把中位数划分给S2;
cout<<"S1:"<<"";
for(int i =0; i < par; i++){
cout<<A[i]<<" ";
}
cout<<endl;
cout<<"S2:"<<"";
for(int i = par; i < n; i++){
cout<<A[i]<<" ";
}
cout<<endl;
return 0;
}
时间复杂度:O(nlogn)
空间复杂度:O(logn)
(九)2017(树)
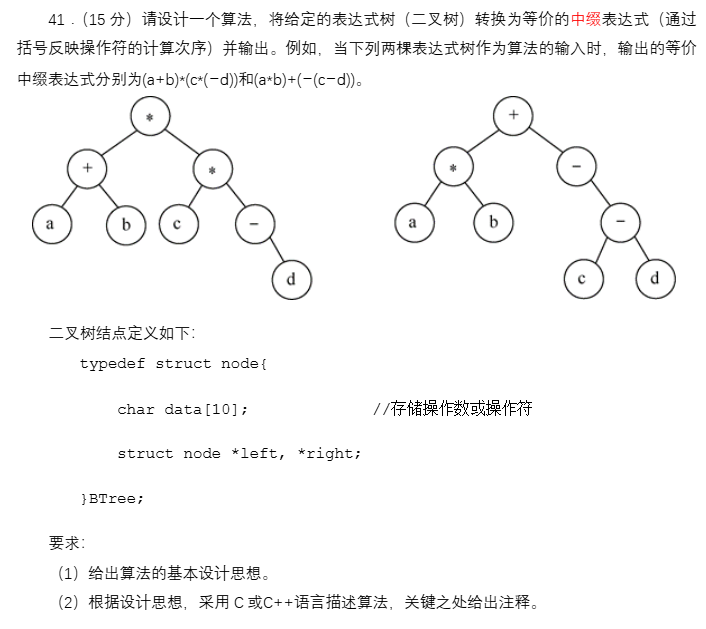
解题思路:中序遍历二叉树,对于当前访问的非空结点p,则先输出”(“,然后递归调用左子树,输出p的权值,递归调用右子树,输出”)”,如果p是根或者叶结点则不需要输出”(”或”)”。
代码:
最优解:中序遍历,递归:
算法思想:中序遍历二叉树,对于当前访问的非空结点p,则先输出”(“,然后递归调用左子树,输出p的权值,递归调用右子树,输出”)”,如果p是根或者叶结点则不需要输出”(”或”)”。
void inorder(BTree* p){ //当前结点p
if (p==null) //p是空结点
return;
if (p->left!=null || p->right!=null)
cout<<”(”;
inorder(p->left); //递归调用左子树
输出p->data //输出操作数(符)
inorder(p->right); //递归调用右子树
if (p->left!=null || p->right!=null)
cout<<”)”;
}
void ans(BTNode* T){
inorder(T->left); //调用根左子树
输出T->data //输出根操作数(符)
inorder(T->right); //调用根右子树
}
(十)2018(顺序表)

解题思路:本题有三种解法,首先是两种暴力解,第一种是多重循环枚举,第二种是快速排序,然后是最优解,即拿空间换时间,
代码:
最优解:以空间换时间:
算法思想:含n个整数的数组,未出现的最小正整数最大为n+1,因此可以设置一个数组,数组下标包含[1, n+1],遍历一遍给定数组进行计数,然后遍历所设数组,寻找最小正整数即可。
#include <bits/stdc++.h>
using namespace std;
int main(){
vector<int> A = {1,4,5,5,5,5,7};
int n = A.size();
//初始化一个新数组
vector<int> count(n+2, 0);
//遍历数组进行计数
for(int i = 0; i < n; i++){
count[A[i]]++;
}
//寻找未出现的最小正整数
for(int i = 1; i < n+2; i++){
if(count[i] == 0){
cout<<i<<endl;
return 0;
}
}
}
时间复杂度:O(n)
空间复杂度:O(n)
暴力解:快速排序:
算法思想:
void Qsort(int A[], L, R){ //a数组保存数据,L和R是边界
if (L>=R) return; //当前区间元素个数<=1则退出
int key, i=L, j=R; //i和j是左右两个数组下标移动
把A[L~R]中随机一个元素和A[L]交换 //快排优化,使得基准值的选取随机
key=A[L]; //key作为枢值参与比较
while (i<j){
while (i<j && A[j]>key)
j--;
while (i<j && A[i]<=key)
i++;
if (i<j)
swap(A[i], A[j]); //交换A[i]和A[j]
}
swap(A[L], A[i]);
Qsort(A, L, i-1); //递归处理左区间
Qsort(A, i+1, R); //递归处理右区间
}
void ans(int A[], n){ //算法代码
Qsort(A, 0, n-1);
int t=1; //假设初始最小未出现正整数t=1
for (int i=0; i<n; i++){
if (A[j]>t){
cout<<t; //此时t是最小未出现正整数,输出t
return;
}
if (A[j]==t)
t++; //t已出现,最小未出现正整数是t+1
}
cout<<t; //输出最小未出现正整数
return;
}
时间复杂度:O(nlogn)
空间复杂度:O(logn)
暴力解:多重循环枚举:
算法思想:
void ans(int A[], n){
bool flag; //flag表示是否出现
for (int i=1; i<n+1; i++){
flag=false; //假设未出现
for (int j=0; j<n; j++)
if (i==A[j]){
flag=true; //此时i出现了,flag变成true
break; //此时i已经出现,跳出内层循环
}
if (flag==false){ //若i未出现过则输出i
cout<<i;
return;
}
}
}
时间复杂度:O(n2)
空间复杂度:O(1)
(十一)2019(链表)

解题思路:这道题有两种解法,暴力解:将后一半链表取下来每个结点从头插入,最优解:将后半段逆置(头插法),再重新插入。
代码:
最优解:链表逆置:
算法思想:
void ans(Node* L, int n){
int t=(n+1)/2; //即n/2向上取整
Node* pre=L, p, q, qq; //q为指向后半段链的指针
for (int i=0; i<t; i++)
pre=pre->next; //pre指向a⌈n/2⌉
q=pre->next; //q指向a⌈n/2⌉+1
pre->next=null; //a⌈n/2⌉的下一个结点为空
Node* L1=malloc(Node); //给后半段链设置头节点,L1指向头节点
L1.next=null; //链L1初始没有其他结点
Node* q1;
while (q!=null){ //逆置,q是待处理结点
q1=q->next; //q1指向结点p的下一个结点
q->next=L1->next; //q的下一个结点变成L->next
L1->next=q; //L的下一个结点是q,q完成头插
q=q1; //更新q,准备处理下一个结点
}
len=n-t; //后一半链长度
pre=L->next;
q=L1->next;
for (int i=len; i>0; i--){ //一个一个重新插入
p=pre->next; //pre是插入位置
pre->next=q; //插入q
qq=q->next; //qq暂存q的下一个结点
q->next=p; //q下一个结点是插入位置后的点
q=qq; //q指向qq所指结点
pre=p; //下一个插入位置
}
}
时间复杂度:O(n)
空间复杂度:O(1)
暴力解:将后一半链表取下来每个结点从头插入:
算法思想:
void ans(Node* L, int n){
int t=(n+1)/2; //即n/2向上取整
Node* pre=L, p, q, qq; //q为指向后半段链的指针
for (int i=0; i<t; i++)
pre=pre->next; //pre指向a⌈n/2⌉
q=pre->next; //q指向a⌈n/2⌉+1
pre->next=null; //a⌈n/2⌉的下一个结点为空
len=n-t; //后一半链长度
for (int i=len; i>0; i--){ //一个一个重新插入
pre=L;
for (int j=0; j<i; j++) //找到插入位置
pre=pre->next;
p=pre->next; //pre是插入位置
pre->next=q; //插入q
qq=q->next; //qq暂存q的下一个结点
q->next=p; //q下一个结点是插入位置后的点
q=qq; //q指向qq所指结点
}
}
时间复杂度:O(n2)
空间复杂度:O(1)
(十二)2020(顺序表)

解题思路:本题最先想到的方法就是暴力解三重循环,然后我们可以想到的优化方法就是固定其中一个数组,然后循环另外两个,可以提高一点效率,贪心算法比较难想。
代码:
最优解:贪心算法:
算法思想:数组A、B、C的长度分别为n、m、l,对数组A、B、C分别设置变量i、j、k存储数组下标不断后移,初始i=j=k=0,可以证明如果是往后移动,只有当移动A[i]、B[j]、C[k]最小的那个时,D=2L3才有可能减小,所以每次都只后移动所指元素值最小的对应数组下标变量,一直重复进行,并更新D的最小值D_min,直到所指元素值最小的对应数组无法在后移,最后输出最小值D_min。
int DD(int a, b, c){
return abs(a-b)+abs(b-c)+abs(c-a);
}
void ans(int A[], n, B[], m, C[], l){ //n、m、l为三个数组长度
int D_min=Maxint, D; //Dmax赋值为最大整数
/*D是本轮a、b确定的情况下最小的距离,D_min是所有情况最小距离*/
int i=j=k=0; //数组C的下标初始为0
while(i<n && j<m && k<l){
D_min=min(DD(A[i], B[j], C[k]), D_min); //更新D_min
if (A[i]<B[j] && A[i]<C[k])
i++;
else
if (B[j]<C[k])
j++;
else k++;
}
cout<<D_min; //输出最小D值
}
时间复杂度:O(n)
空间复杂度:O(1)
较优解:二重循环:
算法思想:两重循环扫描ab,而c数组指针后移,数组A、B、C的长度分别为n、m、l,两重循环枚举a、b,对数组C设置变量k存储数组下标不断后移,初始k=0,只要移动后的D更小,就选择往后移动,然后对于每一组abc求出对应的距离D,并从中选出最小的距离。
int DD(int a, b, c){
return abs(a-b)+abs(b-c)+abs(c-a);
}
void ans(int A[], n, B[], m, C[], l){ //n、m、l为三个数组长度
int D_min=Max_int, D; //Dmax赋值为最大整数
/*D是本轮a、b确定的情况下最小的距离,D_min是所有情况最小距离*/
int k=0; //数组C的下标初始为0
for (int i=0; i<n; i++)
for (int j=0; j<m; j++){ //两重循环枚举a、b
D=DD(A[i], B[j], C[k]); //枚举a、b得到的初始D
while (k<l-1 && DD(A[i], B[j], C[k+1])<D)
D=DD(A[i], B[j], C[++k]); //更新下标k和距离D
if (D<D_min) D_min=D; //更新D_min值
}
cout<<D_min; //输出最小D值
}
时间复杂度:O(n2)
空间复杂度:O(1)
暴力解:三重循环:
算法思想:三重循环将abc都扫描一次,数组A、B、C的长度分别为n、m、l,三重循环枚举abc,对于每一组abc求出对应的距离D,并从中选出最小的距离。
void ans(int A[], n, B[], m, C[], l){ //n、m、l为三个数组长度
int D_min=Max_int, D; //Dmax赋值为最大整数
for (int i=0; i<n; i++)
for (int j=0; j<m; j++)
for (int k=0; k<l; k++){ //三重循环枚举abc
D=abs(A[i]-B[j])+abs(B[j]-C[k])+abs(C[k]-A[i]);
if (D<D_min) D_min=D; //更新最小D值
}
cout<<D_min; //输出最小D值
}
时间复杂度:O(n3)
空间复杂度:O(1)
(十三)2021(图)


解题思路:根据题意可知,只要利用邻接矩阵求出度为奇数的顶点个数,若个数为0或2(不大于2的偶数,0也是偶数),则返回1,反之返回0即可。遍历邻接矩阵A,在无向图中,第i行(或列)非零元素之和为顶点i的度,并记录度为0或2的顶点个数answers。遍历结束后,若answers为0或2,则返回1,反之返回0。
代码:
最优解:邻接矩阵表示法的图的遍历:
int isExistEL(MGraph G){
int answers = 0;
int degree;
//遍历邻接矩阵,并记录相关信息
for(int i=0;i<G.numvertices;i++){
degree=0;//degree用于记录第i行非零元素和
for(int j=0;j<G.numvertices;j++){
if(G.Edge[i][j]!=0) {
degree += 1;//无向图只需算i行非零元素和即可
}
}
if(degree % 2 == 1)//if语句块在外循环内,内循环外
answers++;
}
if(answers==0 || answers==2)
return 1;
else
return 0;
}
时间复杂度:O(n2)
空间复杂度:O(1)
(十四)2022(树)
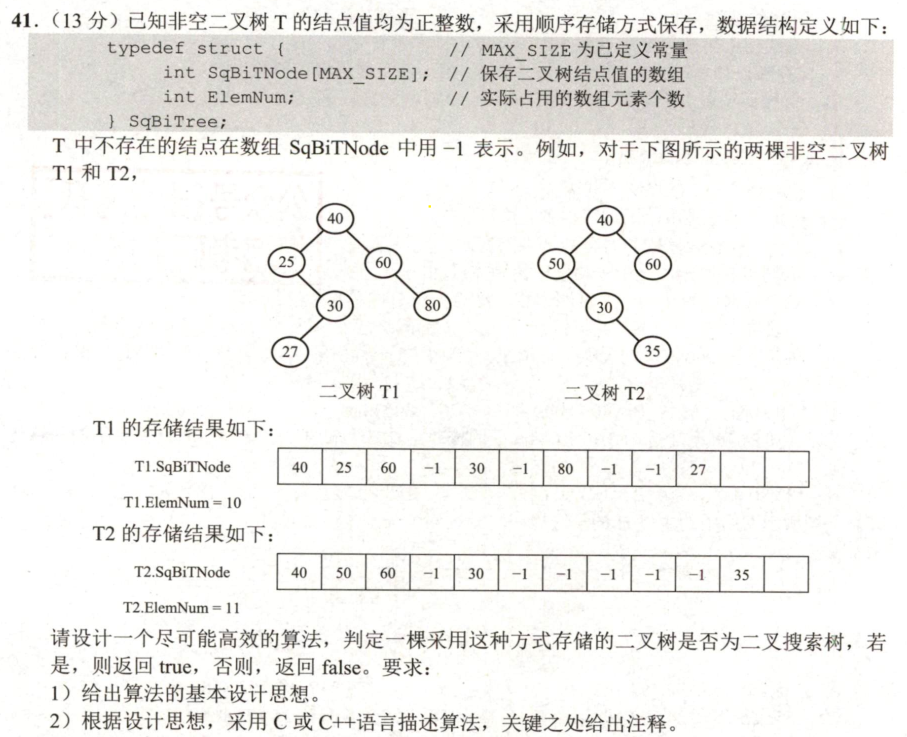
解题思路:由二叉搜索树的性质:某个结点的值大于左子树的所有结点值,但小于右子树所有结点值。因此可以对二叉搜索树进行中序遍历,得到一个升序序列。本题可以用中序递归遍历形式实现该算法。
代码:
最优解:顺序存储树的遍历:
算法思想:
void InOrder(SqBiTree T,int *num,int &length,int i){
if(T.SqBiTNode[i] == -1) return; //空树也满足二叉搜索树
InOrder(T,num,length,2*(i+1)-1);
num[length++] = T.SqBiTNode[i];
InOrder(T,num,length,2*(i+1));
}
bool Jugedment(SqBiTree T){
int num[10000],length = 0;
InOrder(T,num,length,0);
for(int i = 0; i < length - 1;i++){
//若下一个结点的值不大于当前结点,则一定不是二叉搜索树,直接返回false
if(num[i] > num[i+1])
return false;
}
return true;
}
(十五)2023(图)

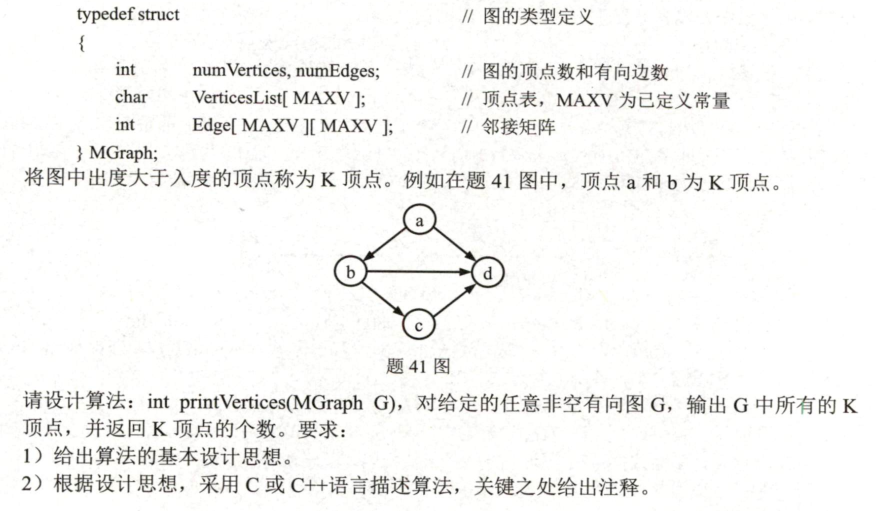
解题思路:
(a)初始化计数器cnt为0,用于记录K顶点的个数
(b)遍历图中的每个顶点V:
1.初始化inDegree和outDegree为0,分别表示顶点v的入度和出度。
2.遍历图中的每个顶点u:如果边(u,v)存在,即G.Edge[u][v]为1,则将outDegree增加1。如果边(v,u)存在,即G.Edge[v][u]为1,则将inDegree增加1。
3.如果outDegree大于inDegree,则顶点v是一个K顶点。输出顶点v,将cnt增加1。
©返回cnt作为K顶点的个数。
代码:
最优解:邻接矩阵表示法的图的遍历:
算法思想:
int printVertices(MGragh G) {
int cnt = 0; //记录K顶点个数
//遍历每个顶点
for (int i = 0; i < G.numVertices; i++) {
int inDegree = 0; //入度
int outDegree = 0; //出度
//计算出入度
for (int j = 0; j < G.numVertices; j++) {
if (G.Edge[i][j] = 1)//出度增加1
outDegree++;
if (G.Edge[j][i] = 1)//入度增加1
inDegree++;
if (outDegree > inDegree) {
//如果出度大于入度,则是K顶点
printf("%c", G.VertexList[i])//输出顶点i
cnt++;//计数器增加1
}
}
return cnt; //返回K顶点个数
}
}
写在后面
这个专栏主要是我在学习408真题的过程中总结的一些笔记,因为我学的也很一般,如果有错误和不足之处,还望大家在评论区指出。希望能给大家的学习带来一点帮助,共同进步!!!
参考资料
[1]王道408教材(2025版)
[2]王道课程资料

















 1704
1704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









