







欲练阅读源码之功,需读此宝典,全篇共五式,读罢必功力大增。此宝典历经千年风霜,如今才得以重见天日,在此赠与各位看官… …(扯)
学习深度学习,必备技能就是读懂开源深度学习项目代码,然而对于深度学习来说,代码结构是没有一个统一标准的。
一方面,代码结构取决于开发者自身的编程观念和水平,另一方面,不同规模的项目,本身需要的结构也是很不一样的。深度学习项目代码,小到几百行的测试demo,大到成千万行的开源项目,读起来方法肯定各有不同。 因此,想要读懂一个深度学习项目的代码,并非一件易事。
那么,本文就带大家一起学习,如何快速看懂一个深度学习项目代码,至少是能够大致了解项目是如何搭建和运行的,这对于我们弄懂项目有很大帮助。
文章目录
第一式——开门大吉:高效获取源码
找源码是一门技术,有的项目或者论文直接给出了Github地址,这无疑是最好的,不过有的论文并没有给出源码,有可能是未开源项目,也有可能是需要咱们自己找。接下来,就为大家分享一下获取源码的方法。
(一)找到Github地址
1.源码网站
这里分享两个寻找论文源码的网站:
(1)https://paperswithcode.com/
网站左上角输入名字,便会出来结果,然后点击code部分即可。
(2)https://www.catalyzex.com/paper/arxiv:1701.04099
和第一个网站类似的操作。
2.其他方法
如果是经典文章,那可以在源码网上进行搜索,如果是比较新的文章,可以采用如下三种方法:
(1)在google搜索该论文的名称或者第一作者的姓名,找到该作者的个人学术主页。在他的主页上看看他是否公开了论文的代码。
(2) 在google搜索该论文中算法的名字+code或者是某种语言,如python等。这是因为阅读这篇论文的科研人员不少,有的人读完会写代码并公布出来。
(3)邮件联系第一作者。
(二)Github下载源码
1.方法一:使用 “Download ZIP” 按钮
(1)打开你想要下载代码的 GitHub 项目页面。
(2)点击项目主页右上方的绿色按钮,上面标有 “Code”。

(3)选择 “Download ZIP”。
(4)下载将以 ZIP 文件的形式开始。一旦下载完成,你可以解压该 ZIP 文件,并在本地使用代码。
2.方法二:使用 Git 克隆项目(推荐)
使用Git的详细方法,可以参考一篇博客:http://t.csdnimg.cn/ZhEOb ,下面做简要介绍:
(1)首先,确保本地已经安装了 Git。如果你没有安装 Git,请从 https://git-scm.com/downloads 进行下载并安装。
(2)打开命令行终端或者 Git Bash 终端(如果你使用的是 Windows)。
(3)移动到你想要将代码下载到的文件夹中,使用以下命令:
cd /path/to/your/desired/directory
上述路径选择,cd 后面是你想要保存下载文件的具体路径,当然,还有一种方法是直接在你要存储的文件夹右键然后选择Open Git bash here。
(4)在 GitHub 项目页面中,点击 “Code” 按钮,并复制项目的 URL。

(5)回到终端,输入以下命令来克隆代码库:
git clone https://github.com/czasg/pywss.git
运行效果如下图:

然后Git 将会将代码库中的内容下载到你刚才指定的文件夹中。

一般网速比较好的时候是选择方法一,如果方法一下载存在困难,则方法二是最佳选择!
3.方法三:使用 GitHub Desktop
(1)如果你喜欢使用图形界面的软件,你可以安装 GitHub Desktop。
(2)打开 GitHub Desktop,登录你的 GitHub 账户。
(3)点击 “File” > “Clone Repository”,然后选择你要下载的项目,并选择一个本地文件夹来保存项目的代码。
第二式——通览全局:了解项目结构
(一)擒贼先擒王:关键之处
我们在阅读一些典型论文或者项目的代码时,常常摸不到头脑,因为项目结构看起来非常的复杂,代码结构组织的方式各不相同,但是,总的来说,一个深度学习项目代码所囊括的无非就是这几个方面:
1. 数据集读取、预处理与加载
2. 模型与网络层定义
3. 模型训练、测试与保存
这些是项目中最重要之处,除此之外,还会有配置、检查点、优化、日志之类的内容。
(二)一例胜千言:一个例子
一个常用的项目结构如下:
--project_name/ :项目名
----data/:数据集
--------__init__.py
----datasets/:数据相关操作,如加载数据
--------__init__.py
--------data_loader.py:加载数据
----layers/:网络模型层
--------__init__.py
--------layer1.py:第1层
--------layer2.py:第2层
----models/:backbone模型
--------__init__.py
--------a_model.py:a模型
--------b_model.py:b模型
----exp/:包含定义、训练、验证、测试和预测方法
--------__init__.py
--------exp_main.py:包含定义、训练、验证、测试和预测方法
----configs/:配置文件
--------__init__.py
--------config.py:方便超参数搜索等
----utils/:用到的功能函数,可以是日志、评价指标计算等等
--------__init__.py
--------utils.py:功能函数
--------metrics.py:评价指标计算
----logs/:日志文件
--------__init__.py
----scripts/:脚本文件
--------__init__.py
----checkpoints/:保存的模型权重
--------__init__.py
--------checkpoints.pt:保存的模型权重文件
----model_hub/:预训练模型权重
--------__init__.py
--------basic_model.pt:预训练好的模型权重文件
----main.py:主程序
----requirements.txt:需要的python依赖
----environment.yml:环境信息
----readme.md:项目说明
要点说明:
__init__.py:一个目录如果包含了__init__.py文件,那么它就变成了一个包。该文件可以为空,也可以定义包的属性和方法,但它必须存在。datasets:数据相关操作,比如用Dataset封装数据集,再用Dataloader实现数据并加载。layers:layers文件夹放的是模型所需要的层,不同model可能需要同样的网络层,为了保证模型代码的简洁性,单独列一个文件夹定义。models:一般而言,核心的代码都是以model命名,或者就是以它这个模型的名字命名。可以有多个模型,一个模型一个.py文件。exp:包含定义、训练、验证、测试、保存和预测方法,这些也可以放到main中,但是为了main的简洁性,单独设置一个文件夹进行定义。关于模型保存,Pytorch可以通过torch.save()函数将训练的模型保存为.pth/.pt/.pkl文件,Keras中训练的模型可以保存为.h5文件configs:包含了一些预定义的配置文件,用于训练和测试深度学习模型。这些配置文件包含了模型架构、损失函数、优化器、训练和测试的超参数等,通过修改这些配置文件,可以方便地调整模型的参数和超参数,如将需要配置的参数均放在这个文件中,比如batchsize,transform,epochs,lr等超参数,以满足不同的需求和任务。utils:通常是存放深度学习中常用的工具函数或类的文件夹,这些工具函数或类可以被多个深度模型共用,提高代码的复用性与可维护性,通常包括数据预处理函数、模型评估函数、损失函数等。scripts:脚本文件集合,脚本文件是函数命令的集合。针对不同的任务,可以运行不同的脚本文件。checkpoints:断点保存,保存模型权重,防止程序突然终止丢失权重文件。model_hub:预训练好的模型权重, 是一个通过大量数据上进行训练并被保存下来的网络。可以将其通俗的理解为前人为了解决类似问题所创造出来的一个模型,有了前人的模型,当我们遇到新的问题时,便不再需要从零开始训练新模型,而可以直接用这个模型入手,进行简单的学习便可解决该新问题。main.py:主程序,解析命令行传递超参数,执行exp中的训练、验证、测试、预测方法。requirements.txt:需要的python依赖,可以在terminal中输入pip install -r requirements.txt命令快速在所使用环境中安装依赖。environment.yml:用于定义和创建 Conda 环境的配置文件。它通常包含了项目所需的所有依赖项及其版本信息。可以使用该文件快速配置conda环境,具体使用方法可见:如何使用environment.yml文件配置conda环境readme.md:一种说明文件,通常随着一个软件而发布,里面记载有软件的描述或注意事项。一般来说,开源项目的readme里作者都会写明如何使用代码和进行部署,这可以帮助我们实现这个项目。
不同项目之间的代码架构不同,所以这个结构只是一个样例供大家参考,还是要根据具体项目分析其架构。
不过了解了一个深度学习项目代码所囊括的几个方面,就能以不变应万变,正所谓孙悟空遇上如来佛祖——纵有七十二般变化,也难逃手掌心。
第三式——虎口掏心:找到入口文件
从现在开始,我们的讲解全部基于一个具体的项目:基于Informer预测股票价格,这个项目的源码我放在文章的最后,大家有需要的请自取~
打开项目以后,从运行入口开始阅读,一般来说,项目入口都是在第一层目录中的,带有main或者run字眼的,找到入口,我们就开始分析入口文件具体的内容。
(一)呼朋唤友:引入模块
在本项目中,入口文件是main_informer.py,打开该文件,首先看到的是各种import。
#导入命令行选项、参数和子命令解析器模块,供接下来的参数定义
import argparse
#导入toch模块,深度学习项目必用模块
import torch
#导入informer模块,提供接下来的训练、测试、预测方法
from exp.exp_informer import Exp_Informer
(二)添砖加瓦:参数设置
在训练卷积神经网络时需要预定义很多参数,例如batch_size, backbone,dataset,dataset_root等等,这些参数多而且特别零散;如果我们最初不把这些参数定义,到时候修改是一件特别麻烦的事情,需要逐个修改;所以这个时候用到了python的add_argument()很好的规避了这些问题。接下来,对argparse使用步骤进行讲解:
1.创建一个解析器——创建 ArgumentParser() 对象
使用 argparse 的第一步是创建一个 ArgumentParser 对象,大多数对 ArgumentParser 构造方法的调用都会使用 description= 关键字参数。这个参数简要描述这个程序做什么以及怎么做。
parser = argparse.ArgumentParser(description='test')
2.添加参数——调用 add_argument() 方法添加参数
给一个 ArgumentParser 添加程序参数信息是通过调用 add_argument() 方法完成的。通常,这些调用指定 ArgumentParser 如何获取命令行字符串并将其转换为对象。这些信息在 parse_args() 调用时被存储和使用。
parser.add_argument('--sparse', action='store_true', default=False, help='GAT with sparse version or not.')
parser.add_argument('--seed', type=int, default=72, help='Random seed.')
parser.add_argument('--epochs', type=int, default=10000, help='Number of epochs to train.')
该方法的参数定义如下:
ArgumentParser.add_argument(name or flags...[, action][, nargs][, const][, default][, type][, choices][, required][, help][, metavar][, dest])
name or flags :选项字符串的名字或者列表,例如 foo 或者 -f, --foo。
action :命令行遇到参数时的动作,默认值是 store。如果action=‘store_true’,只要运行时该变量有传参就将该变量设为True。
store_const:表示赋值为const。
append:将遇到的值存储成列表,也就是如果参数重复则会保存多个值。
append_const:将参数规范中定义的一个值保存到一个列表。
count:存储遇到的次数;此外,也可以继承 argparse.Action 自定义参数解析。
nargs:应该读取的命令行参数个数,可以是具体的数字,或者是?号,当不指定值时对于 Positional argument 使用 default,对于 Optional argument 使用 const;或者是 * 号,表示 0 或多个参数;或者是 + 号表示 1 或多个参数。
const:action 和 nargs 所需要的常量值。
default:不指定参数时的默认值。
type:命令行参数应该被转换成的类型。
choices:输入值的范围,如add_argument(“–gb”, choices=[‘A’, ‘B’, ‘C’, 0])。
required:默认False, 若为 True, 表示必须输入该参数。
help:参数作用解释,如add_argument(“a”, help=“params means”)
metavar:在 usage 说明中的参数名称,对于必选参数默认就是参数名称,对于可选参数默认是全大写的参数名称。
dest:解析后的参数名称,默认情况下,对于可选参数选取最长的名称,中划线转换为下划线。
在学习这一块的时候,我有一个问题,就是为什么参数名的定义前要有一个--,不知道大家有没有这样的问题,那么关于add_argument参数名的定义,我们一起来看一下解释:
#add_argument 说明
不带'--'的参数
是位置参数,调用脚本时必须输入值,且参数输入的顺序与程序中定义的顺序一致
'-'的参数
是可选参数,如add_argument("-a"),只能是1个字符,区分大小写,通常用于表示单字符的命令行选项,也称为短选项。短选项通常用于表示简单的开关或标志。例如,“-v” 可以表示启用详细输出。
'--'参数
参数别名,是可选参数,通常用于表示完整的命令行选项,也称为长选项。长选项通常用于提供更具描述性的选项名称和更丰富的配置选项。例如,“–verbose” 可以表示启用详细输出。
其实只要记住一点,带’- -‘的参数可以不提供输入(可选的),并且给值时候必须要声明参数名(相反地,不带’- -'的参数不用提供参数名,但必须但需输入值)。
如果不懂的话,请看下面这两个例子:
例一(不带’- -'):
import argparse
parser = argparse.ArgumentParser(description='test')
parser.add_argument('seed', type=int, default=72, help='Random seed.')
parser.add_argument('epochs', type=int, default=10000, help='Number of epochs to train.')
args = parser.parse_args()
print(args.seed)
print(args.epochs)
执行命令与运行结果
PS C:\Users\86185\PycharmProjects\DeepLearningModel> python 00test.py
usage: 00test.py [-h] seed epochs
00test.py: error: the following arguments are required: seed, epochs
PS C:\Users\86185\PycharmProjects\DeepLearningModel> python 00test.py 1 2
1
2
PS C:\Users\86185\PycharmProjects\DeepLearningModel> python 00test.py 2 1
1
2
PS C:\Users\86185\PycharmProjects\DeepLearningModel> python 00test.py seed 1
usage: 00test.py [-h] seed epochs
00test.py: error: argument seed: invalid int value: 'seed'
可见不带’- -'的参数必须要给出输入,是位置参数,必须按序输入,且不能指定变量名。
例二(带’- -'):
import argparse
parser = argparse.ArgumentParser(description='test')
parser.add_argument('--seed', type=int, default=72, help='Random seed.')
parser.add_argument('--epochs', type=int, default=10000, help='Number of epochs to train.')
args = parser.parse_args()
print(args.seed)
print(args.epochs)
执行命令与运行结果
PS C:\Users\86185\PycharmProjects\DeepLearningModel> python 00test.py
72
10000
PS C:\Users\86185\PycharmProjects\DeepLearningModel> python 00test.py 1 2
usage: 00test.py [-h] [--seed SEED] [--epochs EPOCHS]
00test.py: error: unrecognized arguments: 1 2
PS C:\Users\86185\PycharmProjects\DeepLearningModel> python 00test.py --seed 1
1
10000
PS C:\Users\86185\PycharmProjects\DeepLearningModel> python 00test.py --epochs 2 --seed 1
1
2
可见带’- -'的参数可以不给出输入(会输出default值),是关键词参数,不用按序输入,必须指定变量名进行赋值。
通过这些讲解,相信大家一定对argparse添加参数有了更深的认知 ~
3.解析参数——使用 parse_args() 解析添加的参数
ArgumentParser 通过 parse_args() 方法解析参数。它将检查命令行,把每个参数转换为适当的类型然后调用相应的操作。在脚本中,通常 parse_args() 会被不带参数调用,而 ArgumentParser 将自动从 sys.argv 中确定命令行参数。
args = parser.parse_args()
4.例子
接下来通过一个例子感受下argparse添加参数的整体流程:
import argparse
parser = argparse.ArgumentParser(description='test')
parser.add_argument('--sparse', action='store_true', default=False, help='GAT with sparse version or not.')
parser.add_argument('--seed', type=int, default=72, help='Random seed.')
parser.add_argument('--epochs', type=int, default=10000, help='Number of epochs to train.')
args = parser.parse_args()
print(args.sparse)
print(args.seed)
print(args.epochs)
输出
False
72
10000
(三)高屋建瓴:主程序运行
好啦,过了参数这一关,我们终于来到了主函数 ~
让我们一起看一下这段代码:
Exp = Exp_Informer
for ii in range(args.itr):
# setting record of experiments
setting = '{}_{}_ft{}_sl{}_ll{}_pl{}_dm{}_nh{}_el{}_dl{}_df{}_at{}_fc{}_eb{}_dt{}_mx{}_{}_{}'.format(args.model, args.data, args.features,
args.seq_len, args.label_len, args.pred_len,
args.d_model, args.n_heads, args.e_layers, args.d_layers, args.d_ff, args.attn, args.factor,
args.embed, args.distil, args.mix, args.des, ii)
exp = Exp(args) # set experiments
print('>>>>>>>start training : {}>>>>>>>>>>>>>>>>>>>>>>>>>>'.format(setting))
exp.train(setting)
print('>>>>>>>testing : {}<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<'.format(setting))
exp.test(setting)
if args.do_predict:
print('>>>>>>>predicting : {}<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<'.format(setting))
exp.predict(setting, True)
torch.cuda.empty_cache()
这段代码可以说是非常简洁了,先是使用format函数对参数进行格式化并赋值给setting,对Exp_Informer类进行实例化,然后调用train、test、predict方法进行训练、测试和预测。
写程序的好习惯:最后调用torch.cuda.empty_cache()方法,是因为PyTorch是有缓存区的设置的,意思就是一个Tensor就算被释放了,进程也不会把空闲出来的显存还给GPU,而是等待下一个Tensor来填入这一片被释放的空间。所以我们用nvidia-smi/gpustat看到的显存占用不会减少。用这个方法可以清空缓冲区,在程序中加上会使速度变慢一些,但是有些情况下会有用,例如程序之前test的时候总是爆显存,然后在循环中加上了这句就不爆了。
第四式——庖丁解牛:分层解析代码
在上文中,我们已经阅读入口文件的逻辑,查看了调用到了哪些包,现在我们需要通过IDE的功能跳转到对应类或者函数进行继续阅读,配合代码注释进行分析。
在主程序中,我们能感受到,其实最重要的调用的函数就是train、test、predict,它们都是Exp_Informer类中的方法,那么我们接下来就以Exp_Informer类为突破口,进行“庖丁解牛”!
进入exp_informer.py,可谓是别有一番洞天!首先映入眼帘的就是一大堆import:
from data.data_loader import Dataset_ETT_hour, Dataset_ETT_minute, Dataset_Custom, Dataset_Pred
from exp.exp_basic import Exp_Basic
from models.model import Informer, InformerStack
from utils.tools import EarlyStopping, adjust_learning_rate
from utils.metrics import metric
import numpy as np
import torch
import torch.nn as nn
from torch import optim
from torch.utils.data import DataLoader
import os
import time
import warnings
这其中import的模块,包含数据(data)的、模型(model)的、工具(util)的,可以帮助我们更深一层把握项目,接下来,就让我们一层一层拨开它的心!
(一)第一层:训练、测试、预测,一应俱全
先来看Exp_Informer类中的内容,大致有以下一些方法:初始化类(__init__)、构建模型(_build_model)、获取数据(_get_data)、选择优化器(_select_optimizer)、选择损失函数(_select_criterion)、损失计算(vali)、训练(train)、测试(test)、预测(predict)、一批数据输入(_process_one_batch),一个个来看!先看代码,代码中有我简单写的注释,然后会针对难点进行讲解 ~
1.初始化类(__init__)
class Exp_Informer(Exp_Basic):
#初始化方法,参数有对象本身self、预定义参数args
def __init__(self, args):
#继承自父类的初始化方法,参数是预定义参数args
super(Exp_Informer, self).__init__(args)
再在这里贴一段Exp_Basic类的代码,接下来的讲解中要用到
class Exp_Basic(object):
#初始化方法,参数有对象本身self、预定义参数args
def __init__(self, args):
#参数等于预定义参数args
self.args = args
#装置等于_acquire_device()所返回的装置
self.device = self._acquire_device()
#模型等于_build_model()输出值送入到device后所返回的model
#关于to(device),请见下方
self.model = self._build_model().to(self.device)
def _build_model(self):
#正常来说,Exp_Informer如果重写了_build_model方法,就会调用Exp_Informer中的,而如果调用到了Exp_Basic中的_build_model方法,就会引发错误。
raise NotImplementedError
return None
def _acquire_device(self):
if self.args.use_gpu:
os.environ["CUDA_VISIBLE_DEVICES"] = str(self.args.gpu) if not self.args.use_multi_gpu else self.args.devices
device = torch.device('cuda:{}'.format(self.args.gpu))
print('Use GPU: cuda:{}'.format(self.args.gpu))
else:
device = torch.device('cpu')
print('Use CPU')
return device
- 关于super(子类, self).父类方法(参数),请见我另一篇文章:一文搞懂!super(子类, self).父类方法(参数)的作用及使用方法,接下来我们直接讲它在本方法中的作用。
Exp_Informer类继承自Exp_Basic类,Exp_Informer的初始化方法继承自Exp_Basic的初始化方法,进行对args、device、model的定义。 model.to(device):方法的含义是为模型设置device。
2.构建模型(_build_model)
def _build_model(self):
#定义一个关于model的字典,也就是说,可以有两个model的选项,一个Informer和一个InformerStack
model_dict = {
'informer':Informer,
'informerstack':InformerStack,
}
if self.args.model=='informer' or self.args.model=='informerstack':
#如果预定义的model参数为informer,则encode层数为预定义的encoder layers——e_layers
#否则为stack encoder layers——s_layers
e_layers = self.args.e_layers if self.args.model=='informer' else self.args.s_layers
#定义model,虽然这里看上去很复杂,其无非是根据预定义的model参数来选择是Informer还是InformerStack
#并且给Informer或者InformerStack传入一大堆参数,除了encoder层数,其它参数都是一样的。
model = model_dict[self.args.model](
self.args.enc_in,
self.args.dec_in,
self.args.c_out,
self.args.seq_len,
self.args.label_len,
self.args.pred_len,
self.args.factor,
self.args.d_model,
self.args.n_heads,
e_layers, # self.args.e_layers,
self.args.d_layers,
self.args.d_ff,
self.args.dropout,
self.args.attn,
self.args.embed,
self.args.freq,
self.args.activation,
self.args.output_attention,
self.args.distil,
self.args.mix,
self.device
).float()
#定义多GPU列表,具体见下方讲解
if self.args.use_multi_gpu and self.args.use_gpu:
model = nn.DataParallel(model, device_ids=self.args.device_ids)
return model
nn.DataParallel:pytorch中的GPU操作默认是异步的,当调用一个使用GPU的函数时,这些操作会在特定设备上排队但不一定在稍后执行。这就使得pytorch可以进行并行计算。但是pytorch异步计算的效果对调用者是不可见的。
但平时我们用的更多其实是多GPU的并行计算,例如使用多个GPU训练同一个模型。Pytorch中的多GPU并行计算是数据级并行,相当于开了多个进程,每个进程自己独立运行,然后再整合在一起。
torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0):这个函数主要有三个参数:
module:即模型,此处注意,虽然输入数据被均分到不同gpu上,但每个gpu上都要拷贝一份模型。
device_ids:即参与训练的gpu列表,例如三块卡, device_ids = [0,1,2]。
output_device:指定输出gpu,一般省略。在省略的情况下,默认为第一块卡,即索引为0的卡。此处有一个问题,输入计算是被几块卡均分的,但输出loss的计算是由这一张卡独自承担的,这就造成这张卡所承受的计算量要大于其他参与训练的卡。
3.获取数据(_get_data)
def _get_data(self, flag):
#参数等于预定义参数args
args = self.args
#定义一个data字典,value是不同的数据集
#这些数据集来自data.data_loader
data_dict = {
'ETTh1':Dataset_ETT_hour,
'ETTh2':Dataset_ETT_hour,
'ETTm1':Dataset_ETT_minute,
'ETTm2':Dataset_ETT_minute,
'WTH':Dataset_Custom,
'ECL':Dataset_Custom,
'Solar':Dataset_Custom,
'custom':Dataset_Custom,
}
#选择你的数据!
Data = data_dict[self.args.data]
#如果timeenc为1,将考虑更多可能的周期信息。
timeenc = 0 if args.embed!='timeF' else 1
#针对train、test、pred,分别提供不同的数据参数
if flag == 'test':
shuffle_flag = False; drop_last = True; batch_size = args.batch_size; freq=args.freq
elif flag=='pred':
shuffle_flag = False; drop_last = False; batch_size = 1; freq=args.detail_freq
Data = Dataset_Pred
else:
shuffle_flag = True; drop_last = True; batch_size = args.batch_size; freq=args.freq
#定义数据集,并输入对应参数
data_set = Data(
root_path=args.root_path,
data_path=args.data_path,
flag=flag,
size=[args.seq_len, args.label_len, args.pred_len],
features=args.features,
target=args.target,
inverse=args.inverse,
timeenc=timeenc,
freq=freq,
cols=args.cols
)
print(flag, len(data_set))
#定义数据加载器,并输入对应参数
data_loader = DataLoader(
data_set,
batch_size=batch_size,
shuffle=shuffle_flag,
num_workers=args.num_workers,
drop_last=drop_last)
#返回数据集、数据加载器
return data_set, data_loader
4.选择优化器(_select_optimizer)
def _select_optimizer(self):
model_optim = optim.Adam(self.model.parameters(), lr=self.args.learning_rate)
return model_optim
torch.optim.Adam :是 PyTorch 中用于训练神经网络的优化器之一。它实现了 Adam 算法,这是一种对比梯度下降算法更高效的优化算法。
Adam 算法有三个主要参数:
lr (learning rate): 学习率。表示每次参数更新时步长的大小。默认值为 0.001。
betas (beta1, beta2): 表示 Adam 算法中两个动量参数。默认值为 (0.9, 0.999)。
eps (epsilon): 一个很小的值,用来维持数值稳定性。默认值为 1e-8。
5.选择损失函数(_select_criterion)
def _select_criterion(self):
#定义损失函数为均方误差
criterion = nn.MSELoss()
return criterion
6.验证(vali)
def vali(self, vali_data, vali_loader, criterion):
self.model.eval()
total_loss = []
for i, (batch_x,batch_y,batch_x_mark,batch_y_mark) in enumerate(vali_loader):
pred, true = self._process_one_batch(
vali_data, batch_x, batch_y, batch_x_mark, batch_y_mark)
loss = criterion(pred.detach().cpu(), true.detach().cpu())
total_loss.append(loss)
#求平均
total_loss = np.average(total_loss)
self.model.train()
return total_loss
这里讲一下train和valid函数,抛开多处细节不谈,这两块代码的思路几乎完全一致,模型走一圈之后调用损失函数输出相应的损失值,不同的是train函数反向传播,valid就仅仅更新了损失就结束了。所以这两个函数的区别必须要进行深究。
首先说一下train和valid在整个深度学习的功用:

看到这里大概其对train函数和valid函数有个了解了,对应的就是训练集和验证集的训练过程。
与此同时在valid函数的第一句用上了model.eval(),也就是说在valid函数里面训练的时候会使用batch normalization 但不会drop out。
7.训练(train)
def train(self, setting):
train_data, train_loader = self._get_data(flag = 'train')
vali_data, vali_loader = self._get_data(flag = 'val')
test_data, test_loader = self._get_data(flag = 'test')
path = os.path.join(self.args.checkpoints, setting)
if not os.path.exists(path):
os.makedirs(path)
time_now = time.time()
train_steps = len(train_loader)
early_stopping = EarlyStopping(patience=self.args.patience, verbose=True)
model_optim = self._select_optimizer()
criterion = self._select_criterion()
if self.args.use_amp:
scaler = torch.cuda.amp.GradScaler()
for epoch in range(self.args.train_epochs):
iter_count = 0
train_loss = []
self.model.train()
epoch_time = time.time()
for i, (batch_x,batch_y,batch_x_mark,batch_y_mark) in enumerate(train_loader):
iter_count += 1
model_optim.zero_grad()
pred, true = self._process_one_batch(
train_data, batch_x, batch_y, batch_x_mark, batch_y_mark)
loss = criterion(pred, true)
train_loss.append(loss.item())
if (i+1) % 100==0:
print("\titers: {0}, epoch: {1} | loss: {2:.7f}".format(i + 1, epoch + 1, loss.item()))
speed = (time.time()-time_now)/iter_count
left_time = speed*((self.args.train_epochs - epoch)*train_steps - i)
print('\tspeed: {:.4f}s/iter; left time: {:.4f}s'.format(speed, left_time))
iter_count = 0
time_now = time.time()
if self.args.use_amp:
scaler.scale(loss).backward()
scaler.step(model_optim)
scaler.update()
else:
loss.backward()
model_optim.step()
print("Epoch: {} cost time: {}".format(epoch+1, time.time()-epoch_time))
train_loss = np.average(train_loss)
vali_loss = self.vali(vali_data, vali_loader, criterion)
test_loss = self.vali(test_data, test_loader, criterion)
print("Epoch: {0}, Steps: {1} | Train Loss: {2:.7f} Vali Loss: {3:.7f} Test Loss: {4:.7f}".format(
epoch + 1, train_steps, train_loss, vali_loss, test_loss))
early_stopping(vali_loss, self.model, path)
if early_stopping.early_stop:
print("Early stopping")
break
adjust_learning_rate(model_optim, epoch+1, self.args)
best_model_path = path+'/'+'checkpoint.pth'
self.model.load_state_dict(torch.load(best_model_path))
return self.model
8.测试(test)
def test(self, setting):
test_data, test_loader = self._get_data(flag='test')
self.model.eval()
preds = []
trues = []
for i, (batch_x,batch_y,batch_x_mark,batch_y_mark) in enumerate(test_loader):
pred, true = self._process_one_batch(
test_data, batch_x, batch_y, batch_x_mark, batch_y_mark)
preds.append(pred.detach().cpu().numpy())
trues.append(true.detach().cpu().numpy())
preds = np.array(preds)
trues = np.array(trues)
print('test shape:', preds.shape, trues.shape)
preds = preds.reshape(-1, preds.shape[-2], preds.shape[-1])
trues = trues.reshape(-1, trues.shape[-2], trues.shape[-1])
print('test shape:', preds.shape, trues.shape)
# result save
folder_path = './results/' + setting +'/'
if not os.path.exists(folder_path):
os.makedirs(folder_path)
mae, mse, rmse, mape, mspe = metric(preds, trues)
print('mse:{}, mae:{}'.format(mse, mae))
np.save(folder_path+'metrics.npy', np.array([mae, mse, rmse, mape, mspe]))
np.save(folder_path+'pred.npy', preds)
np.save(folder_path+'true.npy', trues)
return
9.预测(predict)
def predict(self, setting, load=False):
pred_data, pred_loader = self._get_data(flag='pred')
if load:
path = os.path.join(self.args.checkpoints, setting)
best_model_path = path+'/'+'checkpoint.pth'
self.model.load_state_dict(torch.load(best_model_path))
self.model.eval()
preds = []
for i, (batch_x,batch_y,batch_x_mark,batch_y_mark) in enumerate(pred_loader):
pred, true = self._process_one_batch(
pred_data, batch_x, batch_y, batch_x_mark, batch_y_mark)
preds.append(pred.detach().cpu().numpy())
preds = np.array(preds)
preds = preds.reshape(-1, preds.shape[-2], preds.shape[-1])
# result save
folder_path = './results/' + setting +'/'
if not os.path.exists(folder_path):
os.makedirs(folder_path)
np.save(folder_path+'real_prediction.npy', preds)
return
10.一批数据输入(_process_one_batch)
def _process_one_batch(self, dataset_object, batch_x, batch_y, batch_x_mark, batch_y_mark):
batch_x = batch_x.float().to(self.device)
batch_y = batch_y.float()
batch_x_mark = batch_x_mark.float().to(self.device)
batch_y_mark = batch_y_mark.float().to(self.device)
# decoder input
if self.args.padding==0:
dec_inp = torch.zeros([batch_y.shape[0], self.args.pred_len, batch_y.shape[-1]]).float()
elif self.args.padding==1:
dec_inp = torch.ones([batch_y.shape[0], self.args.pred_len, batch_y.shape[-1]]).float()
dec_inp = torch.cat([batch_y[:,:self.args.label_len,:], dec_inp], dim=1).float().to(self.device)
# encoder - decoder
if self.args.use_amp:
with torch.cuda.amp.autocast():
if self.args.output_attention:
outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]
else:
outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)
else:
if self.args.output_attention:
outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]
else:
outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)
if self.args.inverse:
outputs = dataset_object.inverse_transform(outputs)
f_dim = -1 if self.args.features=='MS' else 0
batch_y = batch_y[:,-self.args.pred_len:,f_dim:].to(self.device)
return outputs, batch_y
(一)第二层:数据、模型、工具,多多益善
再来看Exp_Informer类所使用到的内容,包括data包、models包、utils包,一个个来看!
1.数据(data)
2.模型(models)
3.工具(utils)
4.选择优化器(_select_optimizer)
第五式——拨云见日:一键运行代码
现在我们大致已经将项目代码分析的差不多了,接下来研究一下,如何运行代码,这些都是我自己在运行时候的一些经验,可能不全面,可能存在错误,望大家指出!
我们可以在本地执行,利用IDE,比如Pycharm,也可以在服务器执行,比如Colab。
(一)龟速前进:本地Pycharm运行
1.配置环境:巧妇难为无锅之炊
初次打开一个项目,首先就会在Pycharm上方看到黄色行提示package requirement ‘xxx‘ ,‘xxx‘ ,‘xxx‘ is not satisfied,我一开始的时候尝试一个个安装这些缺失的包,后来才发现,原来可以直接利用requirements.txt安装qwq,只要在pycharm的terminal中运行这句代码(如果有conda环境的话,也可以在conda的prompt中输入):
pip install -r requirements.txt -i http://pypi.doubanio.com/simple/ --trusted-host pypi.doubanio.com
这里用了豆瓣的镜像源,如果不用镜像源太慢啦。
2.输入参数:星星一火可以燎原
还记的咱们的主文件里有配置参数这一块吗,其中有几个参数的required参数设置的是True,也就是说,必须要给出这几个参数的输入,否则无法执行函数:

这样的设置是方便我们进行模型和参数的设置,对于这些参数,我们有以下输入或者处理办法。
(1)我们可以在打开文件时删除所有required参数的设置,并且将default参数设置为所需要的模型和参数。
或者我们也可以在执行时输入:
(2)在terminal中输入
格式为python 主程序名.py --参数1 参数1值 --参数2 参数2值 --参数n 参数n值

(3)在Configuration中设置
“Run–>Edit Configuration–>Parameters”


然后再执行程序就好了 ~
(二)一飞冲天:GPU服务器运行(谷歌Colab)
相较于本地CPU执行,GPU简直不知道高到哪里去了,免费好用的GPU当属Google的Colab,Google Colab是一个基于云端的免费Jupyter笔记本环境,可供用户创建、分享、运行Python代码和机器学习模型,配合谷歌云盘(Google Drive)使用,可以保存模型代码、数据等。它使用方便简洁,速度也蛮快的,就是有时间限制,好像是单次最长12小时,不过对于学生党来说,我觉得已然足够!然后就是需要魔法🌈啦,这个大家自行解决,条条大路通罗马。接下来就看看怎么使用这个好东西吧 ~
用到的两个网站:
Colab官网:https://colab.research.google.com/
Google Driver:https://colab.research.google.com/
1.上传谷歌云盘
Google Colab 支持挂载 Google Drive,方便存储文件。因此,我们直接使用 Google Drive 登录,以便更轻松地进行文件存储。如果不挂载云盘,上传到Google Colab 的文件可能会丢失。
首先右键单击,新建一个文件夹:


然后就能看到我们自己建的文件夹,在这些文件夹中,我们可以上传自己的代码:

2.创建Notebook

点击“file–>New Notebook”,新建notebook,给文件改个名。

点击“Runtime–>Change runtime type”,在其中硬件加速器部分选择GPU保存,Colab便会配置一个带有GPU的机器。

3.环境配置
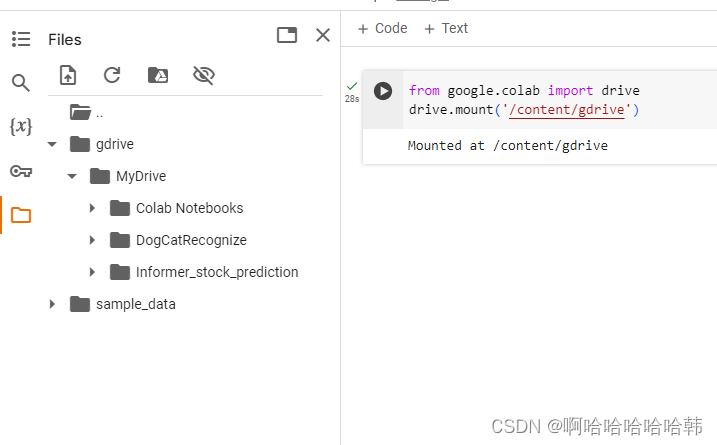
由于我们的数据集以及一些网络模型文件在谷歌云盘上,所以我们还要挂载云盘。在代码块中输入下面代码并点击运行,我们也可以通过直接点击左侧文件标志,然后在点击第三个装载谷歌云盘图标
from google.colab import drive
drive.mount('/content/gdrive')
运行完代码后,就会发现工作文件夹中多了一个drive文件夹:

然后就能看到自己上传的代码啦 ~
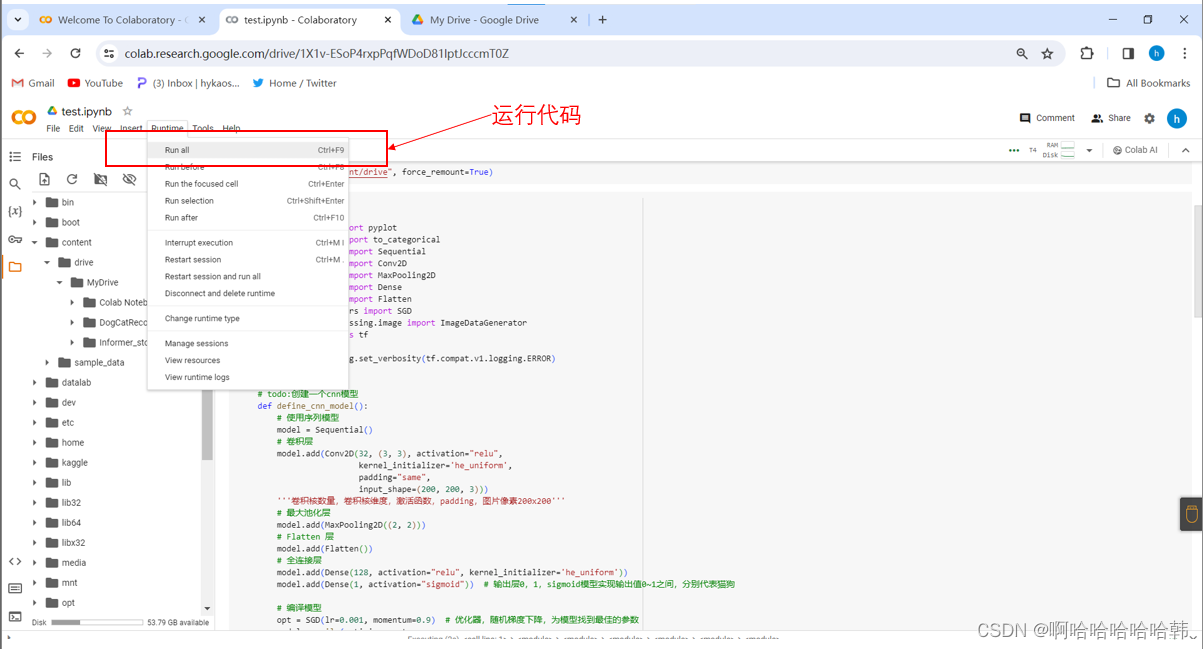
4.运行代码
可以直接在Drive打开Notebook:

运行代码:
(三)剑斩乱麻:遇见Bug怎么办?
一键运行项目,可能会报错,那么这时候该怎么办呢?通常来说,可能会有以下三类Bug:
第一类bug,环境不兼容导致的bug,严格按照作者提供的运行环境,并对照环境的版本信息,对齐本地环境和作者要求的环境。
第二类bug,深度学习框架带来的bug,这部分bug可以在google、csdn上进行搜索,查看解决方案。
第三类bug,项目本身相关的bug,这类bug最好是在github的issue区域进行查找,如果无法解决可以在issue部分详细描述自己的问题,等待项目库作者的解答。
关于Bug部分我后续会不断更新 ~
附录:源码资源
好了,到这里我们的讲解就结束了,下面将上文涉及到的源码资源分享给大家,有需自取 ~
基于Informer预测股票价格项目源码地址:
链接:https://pan.baidu.com/s/1owx53_L-RMEZFjyxtVY0zw 提取码:2002 --来自百度网盘超级会员V4的分享
写在后面
这个专栏主要是我在实现深度学习项目中总结的一些问题,以备未来笔试和面试之需,本篇文章聚焦于如何看懂一个开源深度学习项目的代码,其中参考了很多博主的总结(见下方参考文章),不过由于学习的不深入,也只是走马观花,很多问题总结得也不是很透彻,望读者见谅,如果有错误和不足之处,还望大家在评论区指出。希望能给大家的学习带来一点帮助,共同进步!!!
参考文章:
[1] CSDN文章:如何看懂一个深度学习的项目代码: 链接
[2] CSDN文章:如何查找论文的源码: 链接
[3] CSDN文章:如何在Github上快速下载代码: 链接
[4] CSDN文章:使用python的parser.add_argument()在卷积神经网络中如何预定义参数?: 链接
[5] CSDN文章:python之parser.add_argument()用法——命令行选项、参数和子命令解析器: 链接
[6] CSDN文章:手撕代码:deep image matting (5)train和valid函数: 链接














 343
343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









