






MOCHA:Federated Multi-Task Learning
每日一诗:
《述怀·岂是东方隐》
明·张居正
岂是东方隐,沈冥金马门。方同长卿倦,卧病思梁园。
蹇予柄微尚,适俗多忧烦。侧身谬通籍,抚心愁触藩。
臃肿非世器,缅怀南山原。幽涧有遗藻,白云漏芳荪。
山中人不归,众卉森以繁。永愿谢尘累,闲居养营魂,
百年贵有适,贵贱宁足论。
1.概述:
MOCHA主要是为了解决联邦学习中的系统难题和统计难题而提出的联邦学习框架。
MTL(多任务学习)通过学习每个节点的独立模型,利用任意的凸损失函数为每个节点训练出独立的权重向量。并且考虑节点模型间的相关性来解决联邦环境中的统计难题,并且提升样本容量,但是目前的MTL难以解决系统难题。
在集中环境分布式多任务训练模型CoCoA的基础上进行改进,本文提出联邦多任务学习框架MOCHA,为模型参数W开发有效的分布式优化更新方法。
COCOA的局限性:
在传统的数据中心环境中,分布式训练的任务已有各种沟通效率的框架,包括先进的对偶CoCoA框架。尽管CoCoA框架可以直接扩展在节点上分布式方式更新W,但它无法应对联邦学习环境中的系统挑战。(例如stragglers和容错)
系统挑战:
通信传输瓶颈、存储能力、计算能力、联网能力、电池、stragglers、容错
统计挑战:
数据异构、非独立同分布、不平衡
2.多任务学习:
2.1 理解
经典(非神经网络的)多任务学习,在这种模式中给定t个学习任务{Tt},
每个任务各对应一个数据集Dt,然后根据根据T个任务的训练集学习T个函数{ft}。在这种模式下,每个任务的模型假设(比如都是线性函数)都常常是相同,导致每个任务的模型(权重)不同的原因归根结底在于每个任务的数据集不同(每个任务的损失函数默认相同,也可同可不同)。 此模式优化的目标函数可以写作
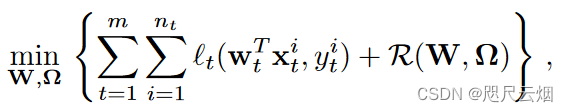
传统的机器学习方法主要基于单任务的学习(Single-task Learning)模式进行学习,对于复杂的学习任务也可将其分解为多个独立的单任务进行学习,然后对学习得到的解决进行组合,得到最终的结果。
多任务学习的关键就在于寻找任务之间的关系,如果任务之间的关系衡量恰当,那么不同任务之间就能相互提供额外的有用信息,利用这些额外信息,可以训练出表现更好、更鲁棒的模型。反之,如果关系衡量不恰当,不仅不会引入额外的信息,反而会给任务本身引来噪声,模型学习效果不升反降。当单个任务的训练数据集不充分的时候,此时多任务学习的效果能够有比较明显的提升,这主要是因为单个任务无法通过自身的训练数据集得到关于数据分布的足够信息。如果有多个任务联合学习,那么这些任务将能从相关联的任务中得到额外的信息,因此学习效果将有显著的提升。目前,多任务学习已经在多个领域得到广泛的应用,比如人脸属性的相关研究、人类疾病的研究、无人驾驶的研究等。
2.2 优势
(1)多任务学习通过挖掘任务之间的关系,能够得到额外的有用信息,大部分情况下都要比单任务学习的效果要好。在有标签样本比较少的情况下,单任务学习模型往往不能够学习得到足够的信息,表现较差,多任务学习能克服当前任务样本较少的缺点,从其他任务里获取有用信息,学习得到效果更好、更鲁棒的机器学习模型。
(2)多任务学习有更好的模型泛化能力,通过同时学习多个相关的任务,得到的共享模型能够直接应用到将来的某个相关联的任务上。相比于单任务学习,上面的优点使得多任务学习在很多情况下都是更好的选择。现实生活中有很多适合多任务学习的场景,
2.3 示例
(1).自然语言处理相关的研究,比如把词性标注、句子句法成分划分、命名实体识别、语义角色标注等任务放在一起研究。
(2).人脸识别中,人脸的属性的研究、人脸识别、人脸年龄预测等任务也可以通过多任务学习进行解决。
(3).图像分类,不同光照下、拍摄角度、拍摄背景下等分类任务的研究,也可以在多任务研究的框架下完成。
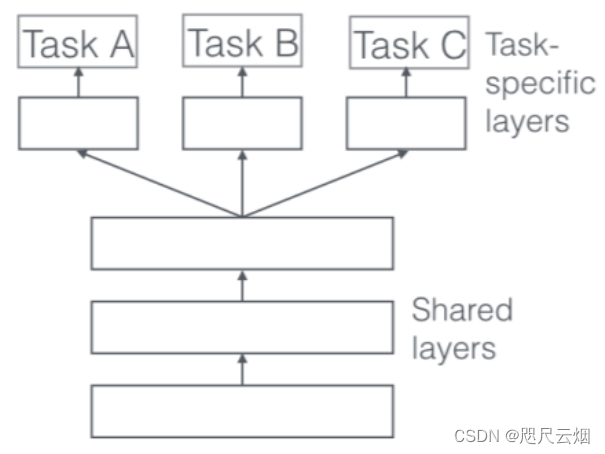
3.联邦多任务学习框架MOCHA::
3.1 多任务-联邦转换
多任务学习通过任意的凸损失函数为每个节点训练出独立的权重向量。(m=nt每个节点看成一个用户)
系数矩阵,每个结点(任务)
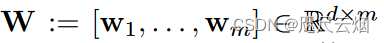
关系矩阵,人物之间的关联。 先验知识/数据挖掘(采用后者)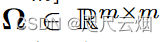
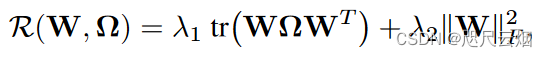
3.2 Observation:
1.W和Ω并非关于min的联合凸, 即便它俩是,同时完成两者的更新也是很困难的。
2.固定Ω,W的更新取决于X,和Ω(中心已知)
3.固定W,优化Ω完全取决于W(与X无关)
基于这些观察,提出了一种交替优化方法来解决问题min函数,在每次迭代中,交替优化更新W或Ω直到达到收敛。
Ω可在服务器中心独立计算,先计算W的更新,就能通过多种方法得到更新后的Ω(附录方法)
固本文主要考虑为模型参数W设计分布式优化更新方法——拓展CoCoA框架,本文提出联邦多任务学习框架MOCHA
3.3 算法流程:

3.3.1 把原min问题转化为其对偶问题:
考虑min的对偶公式使得我们更好地将全局问题分离为分布式子问题,以便跨节点进行联合计算。
全局对偶公式:
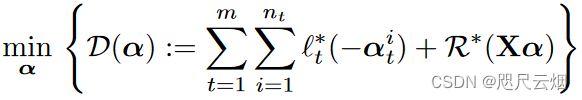
3.3.2 Data-local quadratic subproblems基于本地数据的二次子问题
子问题划分:通过对偶问题min的二次近似由全局对偶导出分布式子问题。
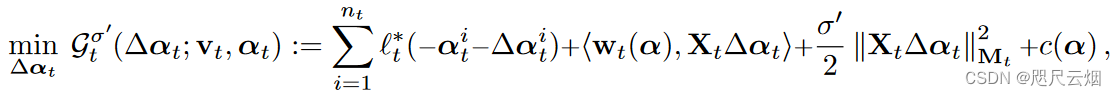
3.3.3 应对系统挑战:
中央节点需要所有客户端提交模型更新参数后才全局更新。
为避免stragglers,本文框架为每个结点提供一定灵活性。 引入θht解决每个结点对应的近似解决子问题。

θht定义为关于上述因素的函数,每个节点都有一个控制器,该控制器可以从当前时钟周期和统计/系统设置导出它的值(0~1)
为0标明所求梯度值为子问题的确切解,为1则表明结点t在h轮迭代中没起作用。解决掉队问题
该值在0-1之间,可根据它的error level 评估该值的大小从而保证了容错性。
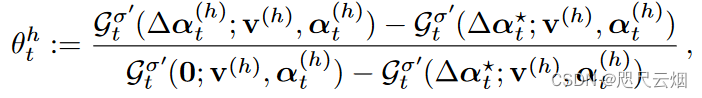
3.3.4 notice
异步更新方案是缓解掉队的另一种方法。
但本文未考虑该方法,因为大多数异步模式限制了框架的容错能力。
4.总结:
本文将多任务学习与联邦学习进行结合,利用多任务学习解决联邦学习中的统计难题;针对联邦学习的系统难题,在COCOA的基础上进行拓展得到联邦多任务学习框架MOCHA,通过引入θht并在每轮次更新开始时由节点根据多种因素确定其值进而解决了系统难题(eg.掉队)。
4.1 notice:
统计问题的解决源自多任务学习的特性——
多任务学习,T个不同但又关联的任务,每个任务有自己的数据集合,通过min函数综合考量任务的关系进而得到泛化的共享模型。
联邦多任务学习中,所有节点执行同一个的任务,每个节点自己的数据集(互相异构),通过与多任务学习类似的步骤求解得到共享模型就是节点执行的single任务的模型。该模型求解是会根据各个结点间的关系为每个节点划分出其对应的子问题。
注: 部分参考
1.(56条消息) 深度学习中的多任务学习介绍_fengbingchun的博客-CSDN博客_深度学习多任务
2.Smith, Virginia, et al. “Federated multi-task learning.” Advances in neural information processing systems 30 (2017).

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









