







Base
Title: 《Attention Is All You Need》 2023
paper:arxiv
Github: None
Abstract
This paper proposed a new simple network architecture, the Transformer based solely on attention mechanisms.
Model Architecture
模型包括 encoder-decoder structure,encode 是将输入序列映射成连续的表示序列:
,decoder 模块将
作为输入,一次产生一个元素的output sequence:
,每一个step,model 都是 auto-regressive[10],生成下一个symbols时候,先前的symbols都作为额外的输入。
整个transformer模型的架构如Figure 1 所示 encoder and decoder 中都使用stacked self-attention and point-wise, and fully connected layers。
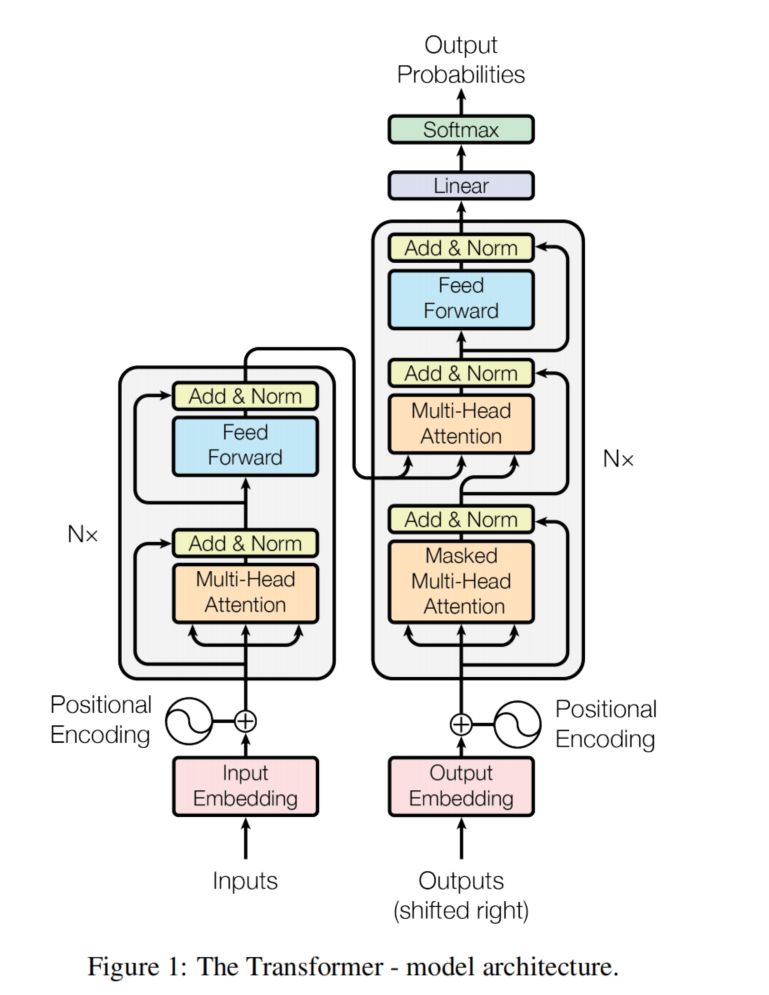
备注:
[10] 《 Generating sequences with recurrent neural networks》https://arxiv.org/abs/1308.0850
Encoder and Decoder Stacks
Encoder:
Encoder 堆叠了6个相同的layer, each layer has two sub-layers, the first is a multi-head self-attention mechanism, and the second is a simple, position-wise fully connected feed-forward network,每一个sub-layer 都使用了 residual connection,之后使用了 layer normalization,因此,sub-layer最后的输出是:, outputs of dimension:
。
Decoder:
Decoder 也是堆叠了6个相同的layer, decoder 相比于encoder的结构,增加了 third sub-layer,实现对encoder实现multi-head attention, 修改了self-attention sub-layer 防止attention 关注当前位置之后的位置的元素, output embeddings 将会被加入一个position offset,保证predictions only depend on position less than 。
Attention:
Attention 可以看作是将query 和一组 key-value pairs 映射为一个output, query, keys, values, and output are all vectors.output 是value的weight sum, 每一个value的weight 是由query 和对应的key 通过function 计算出来的。
Attention
Scaled Dot-Product Attention
Attention 叫做:"Scaled Dot-Product Attention“,input 是query(dimension:) and keys(dimension:
),values(dimension:
),计算query 和all keys 之间的dot products,结果除以
,之后使用softmax函数得到weight.公式如下:
其中: 是query,key,value组成的矩阵;
最常使用的attention function是: additive attention and dot-product attention,本文使用的是dot-product attention,dot-product attention 速度更快,更加节省空间。如果value的值较小,additive attention and dot-product attention 性能是相差不大的,如果
值较大,前者的性能是优于后者的,因为较大的
值,会让点积的增长幅度变大,将softmax压缩到极小的梯度,为了减少这个影响,本文使用缩放点积(
).
Multi-Head Attention
本文不是使用single attention 将query,keys,value进行一次点积,而是将queries, keys and values使用h次不同的线性投影投影到dimension是有好处的。投影的过程是并行的,输出的value的维度是
,之后这些value concatenate and onec again projected.
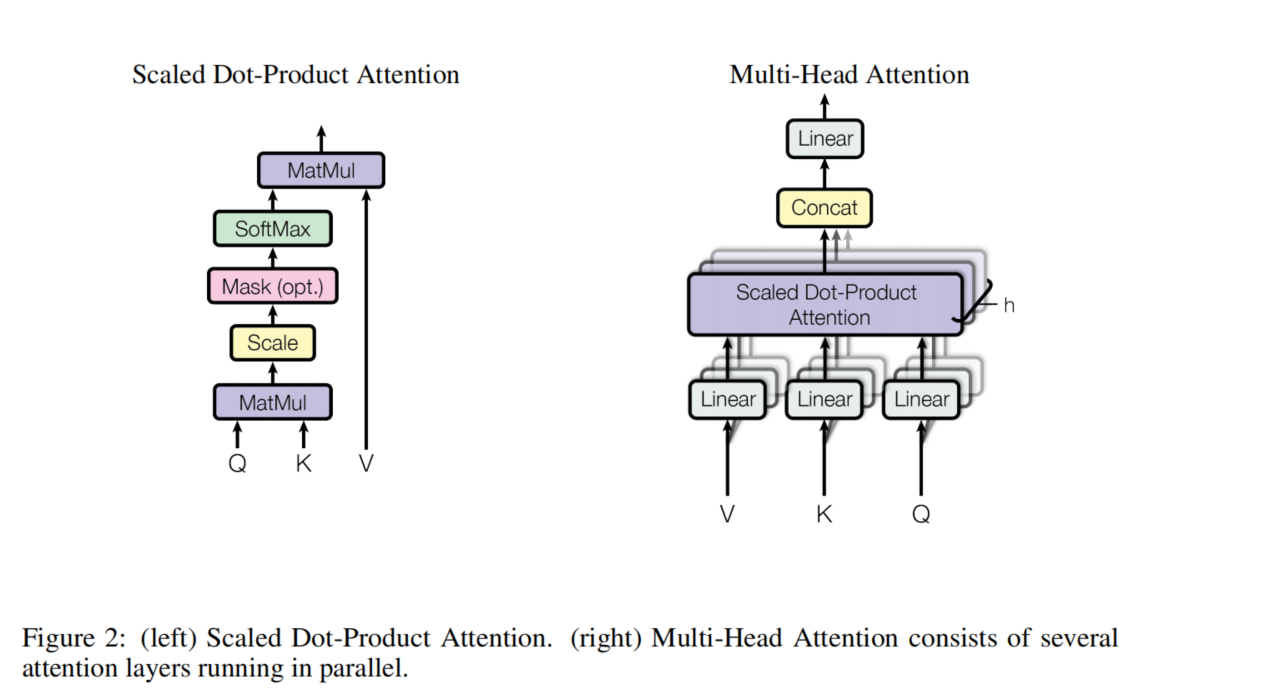
Multi-head attention 可以关注不同subspace 的不同位置的不同的表示, single attention head:
Where

Applications of Attention in our Model
-
the queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder.This allows every position in the decoder to attend over all positions in the input sequence.
-
The encoder contains self-attention layers. In a self-attention layer all of the keys, values and queries come from the same place,the output of the previous layer in the encoder. Each position in the encoder can attend to all positions in the previous layer of the encoder.
-
解码器中的self-attention层允许解码器中的每个位置关注解码器中直到并包括该位置的所有位置。 我们需要防止解码器中的左向信息流以保留auto-regressive属性。 通过屏蔽(设置为−∞)softmax 输入中与非法连接相对应的所有值来实现缩放点积注意力的内部。
Position-wise Feed-Forward Networks
A fully connected feed-forward network consists of two linear transformations with a ReLU activation in between.

Embeddings and Softmax
This paper uses learned embeddings to convert the input tokens and output tokens to vectors of dimension . Also, we use the usual learned linear transformation and softmax function to convert the decoder output to predicted next-token probabilities. we share the same weight matrix between the two embedding layers and the pre-softmax linear transformation, similar to [30]. In the embedding layers, we multiply those weights by
.
Positional Encoding

source code
挖坑...















 1350
1350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









