






该篇首先介绍了openai text embedding官方文档上的模型介绍的内容,然后介绍了下面这篇论文中是如何使用embedding进行分类的,并且进行了代码分析
visualization of Embedded Questions

即该篇论文是使用模型text-similarity-babbage-001模型作为embedding engine,来抓捕文本中的语义相似性,即可对文本题目进行分类。
让我们从openai的"Introducting text and code embedding"的官方文档入手,分析一下这篇论文的源码中的embedding是如何进行题目文本分类的吧
embeddings
首先,openai的text embedding是用来衡量文本之间的语义相似度的,经常用来:
search查找更相关的字符串clustering(按照相似度把文本字符串分组)recommendation(相似的东西可以被推荐)classification(文本字符串可以按照它们最相似的标签来分类)
如何获取一个文本串的embedding?
只需要指定一个模型的id,例如:text-embedding-ada-002,调用openai的/v1/embeddings的API即可。
你讲获得类似如下的embedding:
{
"data": [
{
"embedding": [
-0.006929283495992422,
-0.005336422007530928,
...
-4.547132266452536e-05,
-0.024047505110502243
],
"index": 0,
"object": "embedding"
}
],
"model": "text-embedding-ada-002",
"object": "list",
"usage": {
"prompt_tokens": 5,
"total_tokens": 5
}
}
有哪些embedding model可以用,哪些不推荐用?
-
二代

-
一代(不推荐)
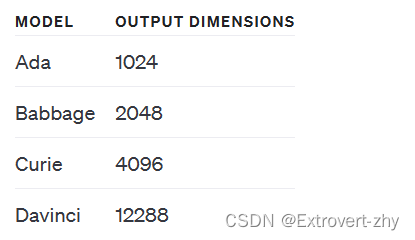
根据输出的编码的向量维度可以分为以下四种:
它们可以用来调试三种任务,分别是:-
Similarity embeddings可以用来捕捉文本片段之间的语义相似度:

-
text search embeddings可以帮助我们衡量哪些文件是跟搜索关键字是相关联的:
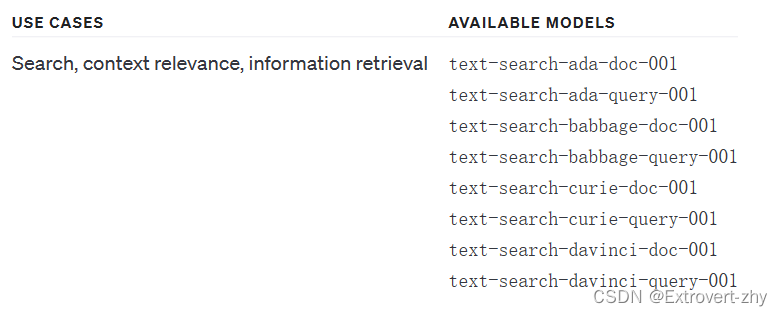
-
code search embeddings和
search embeddings类似,有两种类型,一种是embedding natural language search queries,另一个是embedding code snippets to be retrieved:

-
如何使用embeddings model?
论文中是如何使用embeddings进行分类的?
- 首先,论文把175个数学课程的问题使用
openai的text-similarity-babbage-001嵌入(embed)到一个2048维度的空间中,而这个模型捕获了文本的语义信息,然后,我们使用UMAP(uniform manifold approximation and projection),来把embedding的维度减少到2,从下图中我们可以看出嵌入的问题都按照课程的主题来分组了:
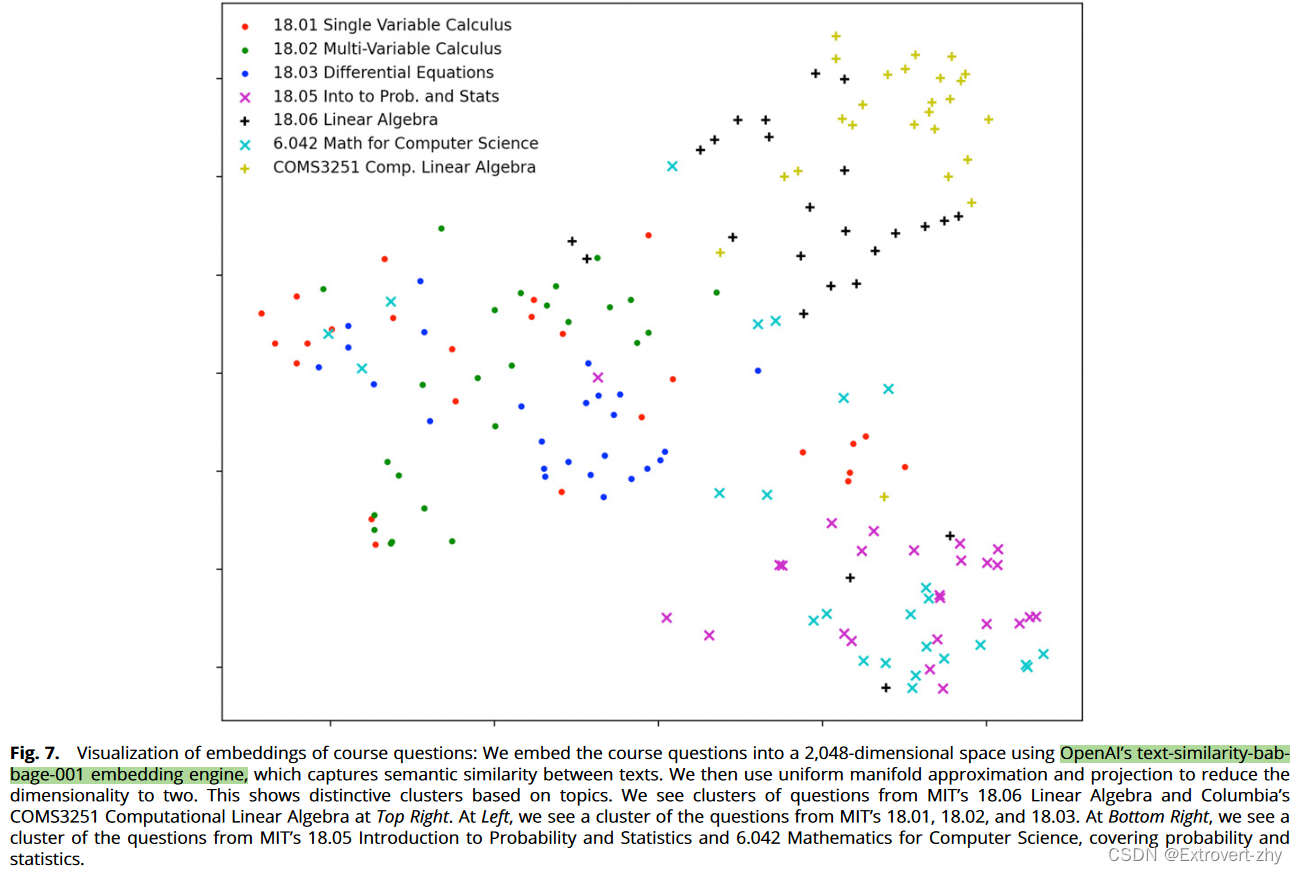
对应代码分析
代码链接:
使用模型:
embedding_engine = 'text-similarity-babbage-001'
整体步骤
在main函数中,从原始文本到嵌入到绘制图像的步骤是:
-
首先进行文本的嵌入:
if not os.path.exists(courses_embeddings_location): make_embeddings(embedding_engine, courses_embeddings_location, courses, questions_per_course) -
然后获取文本的嵌入:
embeddings = get_embeddings(courses_embeddings_location) -
使用UMAP减小维度:
reduced_points = reduce_via_umap(embeddings) -
使用plot画出聚簇:
plot_clusters(reduced_points, image_location, questions_per_course=questions_per_course, question_labels=True)
进行make embeddings的步骤:
make embeddings:
详细情况请看代码注释
#使用openai的嵌入引擎进行嵌入,并将嵌入结果保存在一个新的json文件中
def make_embeddings(embedding_engine, embeddings_location, courses, questions_per_course):
"""
Takes json files of questions using our json file formatting,
embeds them using OpenAI's embedding_engine,
and saves a new json, embeddings.json, of the embeddings.
"""
#用于存储问题的嵌入结果
list_of_embeddings = []
#对于每个课程
for course in courses:
print("Currently embedding " + course + "...")
#对于课程中的每个问题
for num in range(1, questions_per_course + 1):
if num < 10:
#在编号为个位数的时候前面加0,只是为了匹配文件名的格式
q_num = '0' + str(num)
else:
q_num = str(num)
#数据集问题的路径
json_location = './Data/' + \
course.split('_')[0] + '/' + course + \
'_Question_' + q_num + '.json'
with open(json_location, 'r') as f:
data = json.load(f)
#源问题
raw_question = data['Original question']
#使用openai的engine进行嵌入
embedding = openai.Embedding.create(input=raw_question,
engine=embedding_engine)['data'][0]['embedding']
list_of_embeddings.append(embedding)
embeddings = {'list_of_embeddings': list_of_embeddings}
#把嵌入的结果写到文件里
with open(embeddings_location, 'w') as f:
f.write(json.dumps(embeddings))
执行上述函数后,会把问题的原始文本(token的形式)嵌入成类似于以下的形式:
{"list_of_embeddings": [[0.00857878103852272, 0.022301234304904938, -0.018416503444314003, -0.03341588377952576, 0.02199549227952957, -0.0053460015915334225, -0.017598191276192665, 0.009325153194367886, 0.002571835881099105, -0.02134803682565689, 0.008331489749252796, 0.01230164896696806, 0.0260600708425045, 0.0388113409280777, -0.016231341287493706, 0.008848554454743862, -0.000865521724335849.......]]}
获取最相似的文本题目
除了上述代码,该embedding.py文件还提供了一个获取相似题目的函数如下,该函数使用余弦相似度来计算文本之间的相似度:
具体解释请看代码注释
#获取与目标嵌入最相似的问题,相似性是通过余弦相似度来衡量的
def get_most_similar(embeddings, i):
"""
Returns most similar questions, while they are in their embedded form,
to the target, index i, via cosine similarity.
"""
#存储余弦相似度值
cos_sims = []
#存储将余弦相似度映射到相应的问题索引
cos_to_num = {}
for j in range(len(embeddings)):
#计算目标嵌入和当前问题嵌入之间的余弦相似度
cos_sim = util.cos_sim(embeddings[i], embeddings[j]).item()
cos_to_num[cos_sim] = j
cos_sims.append(cos_sim)
#降序排列
ordered = sorted(cos_sims, reverse=True)
closest_qs = []
for val in ordered:
#问题索引通常从1开始
closest_qs.append(cos_to_num[val]+1)
#去除了第一个索引(即目标索引本身,因为目标问题与自己的余弦相似度总是最大的)
return closest_qs[1:]

















 1795
1795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









