








DAIR-V2X数据集
DAIR-V2X数据集是首个用于车路协同自动驾驶研究的大规模、多模态、多视角数据集,全部数据采集自真实场景,同时包含2D&3D标注。DAIR-V2X数据集其实包括3个数据集,分别是DAIR-V2X协同数据集(DAIR-V2X-C)、DAIR-V2X路端数据集(DAIR-V2X-I)和DAIR-V2X车端数据集(DAIR-V2X-V)。具体详细信息在官网。本文中主要介绍DAIR-V2X协同数据集(DAIR-V2X-C)。
DAIR-V2X数据集下载
在这里我只介绍官方的下载方式。数据集的具体下载地址在DAIR-V2X项目中的readme中有给出,具体在这。数据集在谷歌网盘上,需要特殊上网。在进入网站后,点击顺序如下DAIR-V2X------->DAIR-V2X-C------->Full Dataset(train&val) ,然后依此下载即可,速度较慢耐心等待。
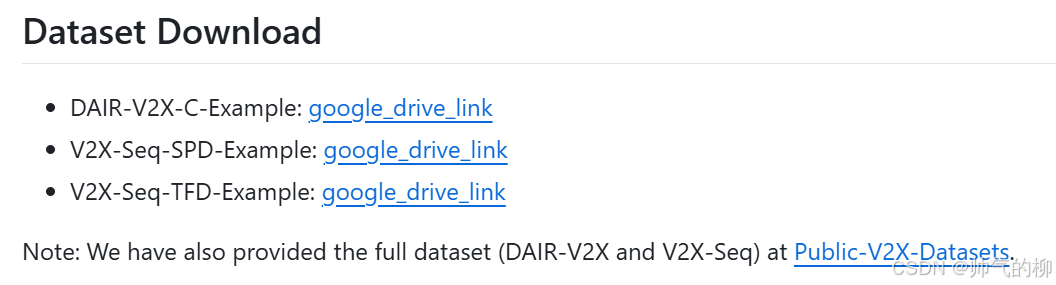
DAIR-V2X数据集解压
在下载完后,会有8个文件,具体如下图所示。其实压缩文件分为5个,cooperative-vehicle-infrastructure.zip、cooperative-vehicle-infrastructure-infrastructure-side-image.zip、cooperative-vehicle-infrastructure-infrastructure-side-velodyne.zip、cooperative-vehicle-infrastructure-vehicle-side-image.zip和cooperative-vehicle-infrastructure-vehicle-side-velodyne.zip,其他的后缀如z01是分卷压缩的。

对于正常的压缩包直接压缩即可,而对于cooperative-vehicle-infrastructure-infrastructure-side-velodyne.zip和cooperative-vehicle-infrastructure-vehicle-side-velodyne.zip通过简单的cat指令得到的结果会有文件损坏,不知道为什么,所以要先进行修复,再解压。根据下main的两条指令就可以对文件进行解压。
zip -FF 损坏的文件名.zip --out 修复后的文件名.zip
例如:zip -FF cooperative-vehicle-infrastructure-infrastructure-side-velodyne.zip --out cooperative-vehicle-infrastructure-infrastructure-side-velodyne_fix.zip
解压指令:unzip cooperative-vehicle-infrastructure-infrastructure-side-velodyne_fix.zip
DAIR-V2X组织情况
在解压完成后可以获得以下5个文件,其中最主要的是cooperative-vehicle-infrastructure,由于我准备跑的算法是CoBEVFlow,所以我就按照CoBEVFlow介绍。首先要把除了cooperative-vehicle-infrastructure的剩下4个文件中的内容分别复制到cooperative-vehicle-infrastructure中的对应位置。例如把cooperative-vehicle-infrastructure-infrastructure-side-image内容复制到infrastructure-side/image。此时cooperative-vehicle-infrastructure中既包含配置文件,也包含原始数据,故都是对cooperative-vehicle-infrastructure中文件进行操作。
解压后的文件目录
cooperative-vehicle-infrastructure中的文件目录

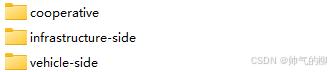
DAIR-V2X数据集介绍
从具体的文件的视角来对数据集中内容进行介绍。争取把每一个文件,以及文件中保存的内容搞明白。总体上来说,cooperative文件夹主要保存车端和路端协作所需要的文件。
由于我主要是参考
CoBEVFlow论文。这篇论文采用的DAIR-V2X数据集不是原始数据集,是增加了标注的数据集,具体介绍DAIR-V2X-C Complemented Annotations。其实也就是把他们标注的文件替换掉原始的标注文件。在下面的介绍中,有时候一个文件夹中会有两个文件xxx和xxx__backup,_backup的表示原始文件,另一个表示新标注文件。
cooperative文件夹
cooperative文件夹目录结构如下,下面具体介绍data_info.json和label_world。
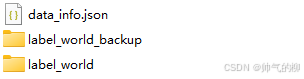
data_info.json
data_info.json中保存的是车端帧和路端帧的对应关系。下面就是json文件中一个字典的内容。
{
# 路端设备在这一帧的图像路径
"infrastructure_image_path": "infrastructure-side/image/007489.jpg",
# 路端设备在这一帧的原始点云路径
"infrastructure_pointcloud_path": "infrastructure-side/velodyne/007489.pcd",
# 车端设备在这一帧的图像路径
"vehicle_image_path": "vehicle-side/image/000289.jpg",
# 车端设备在这一帧的点云路径
"vehicle_pointcloud_path": "vehicle-side/velodyne/000289.pcd",
# 在该帧Object的标注文件路径
"cooperative_label_path": "cooperative/label_world/000289.json",
# 系统错误偏移,在后面计算virtuallidar_to_world的变换矩阵的时候有用
"system_error_offset": {"delta_x": 0.6600000000000001, "delta_y": -1.1}
}
label_world
label_world中保存的是车端帧和路端帧。下面就是文件夹中的目录结构。每一个json文件都对应一个帧的Object标注文件
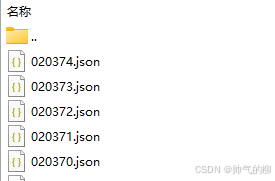
020374.json中保存的是在该帧中所有Object的信息。对于某一个具体的Object,其标注信息如下面所示,最后会根据这些信息生成标签。
{
# (类型,car、truck、van等)
"type": "Car",
# (遮挡状态):从[0, 1, 2]中取值,分别表示不遮挡、0%~50%遮挡,50%~100%遮挡
"occluded_state": null,
# (截断状态):从[0, 1, 2]中取值,分别表示不截断、横向截断、纵向截断
"truncated_state": null
# 观察者视角,范围在[-pi, pi]
"alpha": null,
# (图像中2D bounding box框) 四个值(xmin ymin xmax ymax)
"2d_box": {"xmin": null, "ymin": null, "xmax": null, "ymax": null},
# (height, width, length)
"3d_dimensions": {"h": 1.5230216979980469, "w": 1.8589823246002197, "l": 4.273660182952881},
# (x_loc, y_loc, z_loc)
"3d_location": {"x": 1663.85791015625, "y": 451.52313232421875, "z": 21.390907287597656},
# 表示障碍物绕Y轴旋转角度,一个值
"rotation": -2.6253881454467773,
# 位置
"fill": "1",
# box的8个点
"world_8_points": [[1661.521240234375, 451.2738037109375, 20.690248489379883], [1662.4383544921875, 449.6568298339844, 20.67316246032715], ....]
}
......
vehicle-side文件夹
vehicle-side文件夹主要保存车端采集的原始数据,各种参数文件等。具体目录如下。velodyne和image这两个文件夹,分别保存传感器采集到的原始的点云数据和图像数据,内容简单,就不做详细介绍了。

data_info.json
{
"image_path": "image/000000.jpg",
# 时间戳
"image_timestamp": "1626155123061000",
"pointcloud_path": "velodyne/000000.pcd",
"pointcloud_timestamp": "1626155122981522",
"calib_novatel_to_world_path": "calib/novatel_to_world/000000.json", # 车辆定位系统到世界坐标系的外参文件
"calib_lidar_to_novatel_path": "calib/lidar_to_novatel/000000.json", # 车端LiDAR到定位系统的外参文件
"calib_lidar_to_camera_path": "calib/lidar_to_camera/000000.json", # 车端LiDAR到Camera的外参文件
"calib_camera_intrinsic_path": "calib/camera_intrinsic/000000.json", # 车端Camera的外参文件
"label_camera_std_path": "label/camera/000000.json",
"label_lidar_std_path": "label/lidar/000000.json",
"batch_start_id": "006680", # 批次开始
"batch_end_id": "006901", # 批次结束
"intersection_loc": "",
"batch_id": "51"
}
label文件夹
Label文件保存的仅仅是车端的Object目标,其目录如下。
lidar文件夹中的某一个json文件,存储在该帧中的点云Object的标注信息。其中一个Object的具体标注信息如下。其中内容其实和label_world中一样,所以就不对具体参数进行介绍。
{
"type": "Car",
"occluded_state": null,
"truncated_state": null,
"alpha": null,
"2d_box": {
"xmin": null,
"ymin": null,
"xmax": null,
"ymax": null
},
"3d_dimensions": {
"h": 1.523542,
"w": 1.859057,
"l": 4.27495
},
"3d_location": {
"x": 27.70947,
"y": -12.61107,
"z": -0.7445152
},
"rotation": -1.58316,
"fill": "1"
},
{
"type": "Car",
"occluded_state": null,
"truncated_state": null,
"alpha": null,
"2d_box": {
"xmin": null,
"ymin": null,
"xmax": null,
"ymax": null
},
"3d_dimensions": {
"h": 1.3,
"w": 1.80614,
"l": 4.224961
},
"3d_location": {
"x": 108.7425,
"y": 18.76906,
"z": 0.03543255
},
"rotation": -3.794312e-07,
"fill": "1"
}
camer文件夹中的某一个json文件,存储在该帧中的图像Object的标注信息。其中一个Object的具体标注信息如下。其中内容其实和label_world中一样,所以就不对具体参数进行介绍。
{
"type": "Car",
"occluded_state": 0,
"truncated_state": 0,
"alpha": -1.560667104881363,
"2d_box": {"xmin": 1014.828369, "ymin": 565.370605, "xmax": 1056.707641, "ymax": 601.1560049999999},
"3d_dimensions": {"h": 1.549408, "w": 1.818228, "l": 4.270406},
"3d_location": {"x": 36.81612, "y": -0.01767237, "z": -0.7743582},
"rotation": -0.009744192
}
calib文件夹
calib文件夹主要保存各种坐标变换的信息,包括旋转矩阵和平移矩阵。在代码中会根据这些信息,组成坐标间的变换矩阵。具体目录如下。这里面四个文件具体保存的是什么变换信息,DAIR-V2X官网是有详细的描述的,这里就不赘述。主要来看一下里面的具体内容。

其实这些文件中的json文件大同小异,都肯定包含两个参数translation和rotation。json文件包含的其他参数,我目前在代码中没看到有什么用,最关键的就是上述两个。如果对于坐标系的旋转和平移变换不明白的,可以参考这个博客,写的比较好。
在这里我们用novatel_to_world来举例,translation是(3,1),也就是只有三个数字,这代表从车辆定位坐标系变换到世界坐标系所需要的平移;rotation是(3,3),也就是一个矩阵,这代表从车辆定位坐标系变换到世界坐标系所需要的旋转。有了这两个参数,我们就可以组成车辆定位坐标系变换到世界坐标系的变换矩阵。
{
"translation": [[1627.0745366999763], [600.1771452007815], [22.0908309]],
"rotation": [[0.858972330176, -0.51201056560832, -0.0034242809977601393],
[0.51198052118464, 0.85879836871424, 0.018474762116479755],
[-0.006518506148479754, -0.01762247466175986, 0.9998234631552]]
}
camera_intrinsic文件夹与其他三个不同,因为这是相机内参,不涉及坐标变换。内参矩阵只与相机本身有关,取决于相机的内部参数。相机的内部参数有5个:焦距,像主点坐标,畸变参数;一般不怎么用,不用过于在意。
{
# 畸变参数(cam_D)
"cam_D": [-0.173981, 0.022416, -0.000744, -0.000158, 0.0],
# 内参矩阵(cam_K) 焦距(f_x, f_y) 主点坐标(c_x, c_y)
"cam_K": [797.351678, 0.0, 993.586356, 0.0, 799.238376, 583.568721, 0.0, 0.0, 1.0]
}
infrastructure-side文件夹
infrastructure-side中保存的是路端设备的点云数据和图像数据,以及一些参数文件。具体都是和车端一样,可以类比着来看,这里就不详细解释。

cooperative与infrastructure-side和vehicle-side的Label之间的关系
在上文的介绍中,我们发现在cooperative、infrastructure-side和vehicle-side中都有label文件夹,也都有自己的标注文件,那他们的关系是什么?
根据我们自然的想法,infrastructure-side和vehicle-side中的label应该是路端和车端单个智能体的标注文件,而cooperative是路端和车端协作场景中的标注文件,那么cooperative中的label应该是infrastructure-side和vehicle-side中的label并集再去重后的结果。但是实际不是一样的,cooperative的label是infrastructure-side和vehicle-side中所有type为Car的label组成的。
cooperative中的label数量 =infrastructure-side中type为Car的label数量 +vehicle-side中type为Car的label数量
百度网盘下载地址
通过网盘分享的文件:DAIR-V2X-C
链接: https://pan.baidu.com/s/10yjee6tFp56Ruj6-XEH0Bg?pwd=q9cp 提取码: q9cp
总结
本文中主要介绍了DAIR-V2X协同数据集(DAIR-V2X-C),而对于另外两个数据集没有介绍,原因在于目前科研用不到。CoBEVFlow代码中就只是使用了,DAIR-V2X协同数据集(DAIR-V2X-C)数据集。该数据集是目前协同感知领域用的非常多的数据集,而且不是模拟器采集的,是实地拍摄的,所以更有现实意义。但是让我最困惑的是,数据集中对于一个场景,只有一个无人车和一个路边单元。也就是说对于任何一个场景只有两个智能体,这属实有些让人难以接受了。
目前这个数据集总大小约为30G,用谷歌网盘下载还是有点慢,如果有需要我可以把数据集上传到百度云盘,方便大家下载。

















 770
770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









