






获取方式1(获取弹幕量少)
随便打开一个热门的视频链接,再bilibili.com前加i
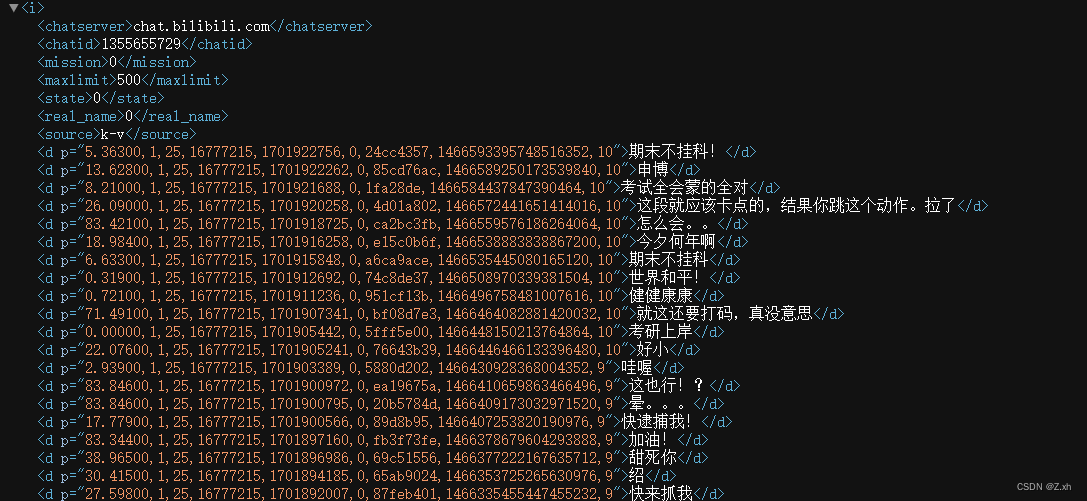
 这里可以直接看到当前视频的弹幕地址,可以直接用正则表达式筛选出所需的弹幕内容
这里可以直接看到当前视频的弹幕地址,可以直接用正则表达式筛选出所需的弹幕内容
获取方式1代码
import requests
import re
url = 'https://api.bilibili.com/x/v1/dm/list.so?oid=1355655729'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0'
}
response = requests.get(url=url,headers=headers)
response.encoding = 'utf-8' #进行转码防止乱码
content_list = re.findall('<d p=".*?>(.*?)</d>',response.text)
content = '\n'.join(content_list)
with open('弹幕1.txt',mode='a',encoding='utf-8') as f:
f.write(content)
print(content)将爬取到的数据保存为弹幕1.txt文件,打开查看内容 (方式一简单但爬取到的弹幕内容较少)
获取方式2(可以获取全部的历史弹幕)
打开页面的开发者模式,打开网络,点击前一天的历史弹幕,能看到弹幕数据
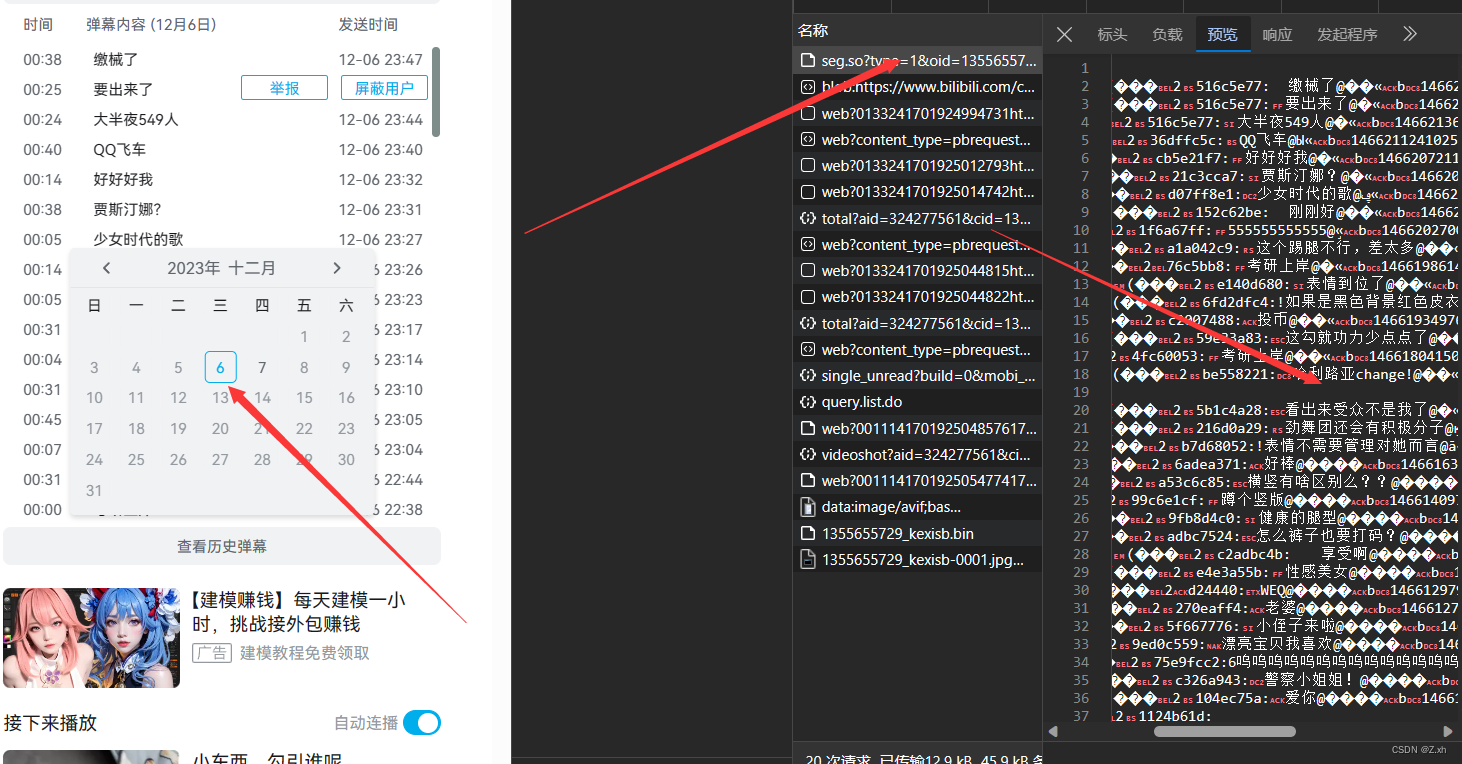
因为历史弹幕要登陆才能查看,这里要在headers中加入自己浏览器的cookie(包含登录信息)
import requests
import re
for page in range (6,8): #爬取六号和七号的弹幕
url = f'https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid=1355655729&date=2023-12-0{page}'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0',
'Cookie': #浏览器中的cookie
}
response = requests.get(url=url,headers=headers)
response.encoding = 'utf-8' #进行转码防止乱码
content_list = re.findall('[\u4e00-\u9fa5]+',response.text) #正则表达式只匹配中文
content = '\n'.join(content_list)
with open('弹幕2.txt',mode='a',encoding='utf_8') as f:
f.write(content)
print(content_list)根据要获取的弹幕天数,我这里for page in range (6,8):只为了获取 ,六号到七号的所有弹幕。
生成结果为弹幕2.txt的文本文件,打开查看结果
















 2496
2496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









