







写在jupternotebook
分代码段运行
主要功能
导入数据、借助模型训练,预测结果
import tensorflow as tf
import pandas as pd
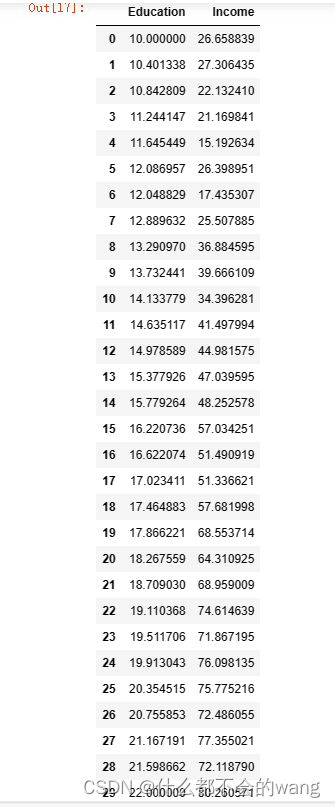
data = pd.DataFrame({'Education': [10.000000, 10.401338, 10.842809, 11.244147, 11.645449, 12.086957, 12.048829, 12.889632, 13.290970, 13.732441, 14.133779, 14.635117, 14.978589, 15.377926, 15.779264, 16.220736, 16.622074, 17.023411, 17.464883, 17.866221, 18.267559, 18.709030, 19.110368, 19.511706, 19.913043, 20.354515, 20.755853, 21.167191, 21.598662, 22.000000],
'Income': [26.658839, 27.306435, 22.13241, 21.169841, 15.192634, 26.398951, 17.435307, 25.507885, 36.884595, 39.666109, 34.396281, 41.497994, 44.981575, 47.039595, 48.252578, 57.034251, 51.490919, 51.336621, 57.681998, 68.553714, 64.310925, 68.959009, 74.614639, 71.867195, 76.098135, 75.775216, 72.486055, 77.355021, 72.11879, 80.260571]})
data
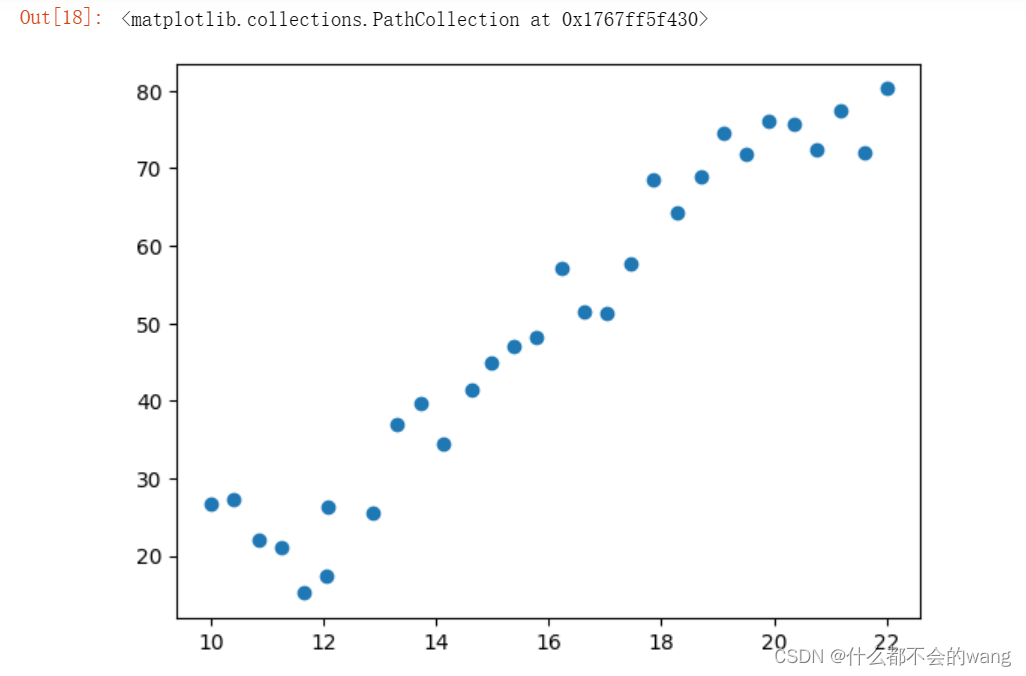
import matplotlib.pyplot as plt
%matplotlib inline
plt.scatter(data.Education,data.Income)
x = data.Education
y = data.Income
model = tf.keras.Sequential() #序贯模型是函数式模型的简略版,为最简单的线性、从头到尾的结构顺序,不分叉,是多个网络层的线性堆叠
model.add(tf.keras.layers.Dense(1,input_shape=(1,))) #将该层添加至模型中 Dense 全连接层建立模型 输出维度 1 输入维度 1 模型中的第一层(只有第一层,因为下面的层可以自动的推断尺寸)需要接收关于其输入尺寸的信息,后面的各个层则可以自动的推导出中间数据的shape
model. Summary()

model.compile(optimizer='adam',loss='mse') # 优化方法 编译
# '''优化器 optimizer:它可以是现有优化器的字符串标识符,如 rmsprop 或 adagrad,也可以是 Optimizer 类的实例。
# 损失函数 loss:模型试图最小化的目标函数。它可以是现有损失函数的字符串标识符,如 categorical_crossentropy 或 mse,也可以是一个目标函数。
# 评估标准 metrics:对于任何分类问题,你都希望将其设置为 metrics = [‘accuracy’]。评估标准可以是现有的标准的字符串标识符,也可以是自定义的评估标准函数
# '''
history = model.fit(x,y,epochs=1000) #学习训练 epochs 次数
model.predict(x) #预测

model.predict(pd.Series([20]))
















 477
477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









