







本文重点:
- 种群
- 精英
- 计分
- 选择
- 选择算法的可伸缩性
理解种群
种群即居住在一个地方的一群特定种类的人或动物。在机器人工智能中,种群是解决问题的一组潜在方法,这些潜在解属于同一种类,因为他们解决相同的问题。有时候,解种群中的成员将分为不同的物种,但是仍然将这些成员归为同一种群。
初始种群
种群规模通常不会随着演化算法的发展而改变。种群规模是一个硬性限制。例如,如果你指定500个人,那么总会保持500个人。我们创建一个初始种群,其计数等于该种群规模,构成初始种群的初始潜在解将被随机生成。这些最初的随机解可能不太好,但是,其中一些随机解的得分会比较高。
程序中使用的算法类型会影响种群规模。种群成员可以是竞争的,也可以是合作的。合作种群通常以固定规模开始,并且永远不会添加或删除新成员。竞争种群总是会创造出后代,以维持这个固定种群的规模。这些后代也被称为==“迭代”==,下一代的孩子仅由最合适的亲本产生,一旦竞争种群的下一代达到这个最大的后代数量,就不会再有孩子出生了。
人工智能中的一些算法模仿自然,因为动物种群通常既有竞争性,又有合作性。
种群成员之间的竞争
竞争种群的算法包括遗传算法和遗传编程。这些算法都会创建潜在的解,分数较高的解更有可能被选择用于交配并提供下一代种群。除交配外,竞争种群的成员之间没有直接合作。
竞争种群总是会包含一个或多个获得最佳分数(比如打平)的解。还有一个可能的结果是,下一代不包含超过上一代最佳分数的新解。如果发生这种情况,最优解的分数将下降,从而使训练倒退一步。这种结果通常是不希望产生的。
可以通过==“精英”==来解决这一问题,精英是一种训练设置,用于指定将多少个获得最佳分数的解用于下一代。因为精英设置始终会保留最优解,所以它可以保证算法不会倒退到较差的分数。可以将其设置为多个获得最佳分数的解,而不只是单个解。精英不是防止种群的最佳分数在代际间倒退的唯一途径。此外,“联赛”也可以防止分数下降。
种群成员之间的合作
AI中的种群并非都是竞争种群,AI中也存在合作种群。合作种群的算法包括粒子群优化(Particle Swarm Optimization,PSO)和蚁群优化(Ant Colony Optimization,ACO),在这两种算法中,各个潜在的解相互学习。在它们寻求指定问题的良好解时,信息在个体之间共享。
合作种群总会跟踪其成员已经找到的最优解,但算法不会贪心,而会在寻求最优解时接受一个较差的解。由于这个特性,跟踪至今为止找到的最优解非常重要。保留这些记录可以使你恢复到最优解,即使种群成员已转向较差的解。
与竞争算法一样,合作算法也是迭代的。但是,一次合作迭代不会用新一代取代先前的种群。合作算法的迭代仅表示对每个潜在解的一次完整遍历,评估解的有效性并获得了分数。在每个迭代周期结束时,所有潜在的解都会进行协作并调整它们的解参数,使得分数最大化。
表型和基因型
表型和基因型是两个来自生物学的术语,它们对某些受大自然启发的算法很重要。基因型是遗传信息,生物体根据它来生长。表型是由基因型产生的实际生物组织。同卵双胞胎就是理解表型和基因型之间差异的一个很好的例子。同卵双胞胎拥有相同的基因型,但是,双胞胎会成长为不同的人,具有稍显不同的身体特征。在AI中,相同的基因型会成长为两个略有不同的表型。
HyperNEAT神经网络是一种可以区分表型和基因型的受大自然启发的算法的例子。
岛屿种群
屿的概念也可以在受大自然启发的算法中使用,以使多个种群在很大程度上彼此独立,就像真实的岛屿将种群分开一样。算法还可以选择允许岛之间的偶然交互。这种间歇性相互作用类似于陆桥或其他允许生物在生态系统之间传播的地质事件。
岛屿概念最常用于竞争种群。将潜在解分为多个种群,可以使新的创新不断发展,而不会受到现有种群的威胁。岛屿之间偶尔可以进行互动,并允许其他岛屿的外来解引入新的想法。
对种群计分
能够对种群成员进行计分是非常有价值的,种群成员的分数决定了该种群成员所代表的潜在解的适用性。大多数演化算法可以使分数最小化或最大化,你需要确定是低分好还是高分好。一些人类运动,例如高尔夫球,追求的是最低分或低分,足球等运动则追求最高分或高分。
在将成员添加到种群时,要对该成员进行计分。潜在解的分数通常与解存储在同一对象上。这个存储位置可以让程序不需要持续重新计算分数。最初,你需要为随机种群的每个成员计分。如果种群成员发生变化,那么它的分数还需要重新计算,如果添加了新的种群成员,那么需要确定它的分数。
对个体进行计分的确切方法,取决于所解决问题的类型。适应度函数用于评估可能的解并指定分数。适应度函数有时称为损失函数(loss function)或目标函数(objective function)
计分通常是演化算法的性能瓶颈。
从种群中选择
选择是从种群中挑选一个或多个潜在解的过程,这个过程通常称为“抽样”,你可以从各种不同的选择过程中进行挑选。每种选择算法都有其优缺点。常见的选择算法包括:
- 截断选择;
- 联赛选择;
- 适应度比例选择;
- 随机遍历抽样。
截断选择
截断选择是最基本的选择算法之一。是由HeinzMuhlenbein在breedergenetic algorithm论文中提出的。截断选择需要根据适应度对种群进行分类。分类后,选择一定比例(例如1/3)的种群作为育种种群。然后从育种种群中取样潜在解,以帮助生产下一代。

def truncate_select(breeding_ratio,sorted_population){
sort(sortrd_population)
count = len(sorted_population)*breeding_ratio
index = uniform_random(0,count)
return sorted_population[index]
}
截断选择算法的最大限制之一,就是必须对种群进行排序,你必须不断使整个种群处于已知的排序状态。这种排序严重限制了该算法针对多核和分布式计算而并行化的能力。结果,该算法无法在大种群中很好地伸缩,因为你可能有许多不同的选择在并行运行。
此外,由于亲本只生孩子,而亲本没有加入下一代,因此有可能没有孩子达到或超过上一代最优解的分数。因此,你应该用精英来选择一个或多个最优解,并直接复制到下一代。如果不用精英,你的最佳得分可能会在两次迭代之间降低。
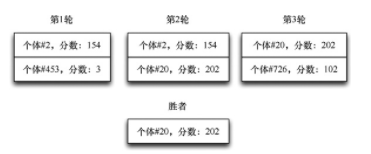
联赛选择
联赛选择通过一系列轮数来进行,并总是让获胜者进入下一轮。轮数是一种训练设置,对于每一轮,你必须在种群中选择两个随机个体,得分较高的个体进入下一轮联赛,解决了截断选择的可伸缩性问题。
def tournament_Select(rounds,population){
champ = null
for x from 0 to rounds:
contender = uniform_random(population)
if champ id null:
champ = contender
else if contender.score >champ.score:
champ = contender
return champ
}
不需要排序,甚至可以将小于翻转为大于,创建反转选择。使用联赛选择还可以打破演化算子经常使用的典型世代模型。打破世代模型将极大提高并行处理的效率,缺少世代模型也更接近生物学。由于每天都有婴儿出生,因此人类世代的开始和结束并没有一个明确的时刻。要放弃世代模型,请使用联赛选择,并选择两个合适的亲本来生一个孩子。要选择不适应的种群成员,请进行反转联赛。不适应的种群成员被“杀死”,由新的孩子代替。这种联赛模型消除了对精英的需求。最优解永远不会被取代,因为反转联赛永远不会选择它。
联赛选择在生物学上也是合理的。为了生存到第二天,个体不需要战胜种群中最快的掠食者,只需要战胜它在任何给定的一天遇到的掠食者。
如何选择轮数
轮数是一种训练设置,就像种群计数一样,即使训练设置不是最终解的一部分,它们也会影响你找到合适解的速度。通常,训练设置是通过反复试验来设置的。
可以通过实验来选取折中的方式。
适应度比例选择
适应度比例选择,也称为轮盘赌选择,是一种用于演化算法的流行选择算法 [4]。该算法类似于轮盘赌,个体占据了轮盘赌的一部分,该部分与他们的得分意愿成正比。当人们旋转轮盘赌时,得分意愿更大的个体更有可能被选择。
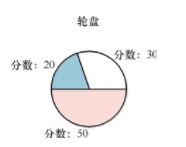
上图所示在轮盘上分配20、30和50的分数。分数为50有50%的机会被选中。分数不一定要像这样与个体所占的百分比相等,因为比例可以简单地根据分数总和来调整。==适应度比例选择可能会选择最不适合的个体,而联赛或截断选择永远不会选择最不适合的个体。==这个选择过程不一定很糟糕,选择过程中的多样性有时会产生有趣的结果,因为它允许新的想法进入种群。
def fittness_proportion_select(population){
total_score = 0
for individual in population:
total_score = total_score+individual.score
r = random_uniform(0,1)
covered_so_far = 0
for individual in population:
covered_so_far = covered_so_far+(individual.score/total_score)
if r<coveres_so_far:
return individual
return null
}
首先计算所有分数的总和。这个过程使我们能够计算出每个单独分数所占的百分比,所需的计算是简单的百分比计算。然后,我们生成一个0~1的随机数。我们现在从0开始,将每个种群成员的大小加到总和上。一旦总和超过先前生成的随机数,我们就找到了包含我们的随机数的轮盘部分。轮盘的较大区域具有较高的被选择概率。当种群中的一个成员与其他成员相比得分非常高时,适应度比例选择可能会导致不良表现。这种类型的个体将主导选择。
随机遍历抽样
适应度比例选择利用重复随机选择从种群中选择几个个体,James Baker(1987)引入了随机遍历抽样(StochasticUniversal Sampling,SUS),用单个随机值对请求个体的数量进行抽样。这些个体按均匀的间隔来选择。这种类型的选择为种群中较弱(根据它们的适应度来衡量)的成员提供了被选择的机会,从而减弱了适应度比例选择的不公平性。
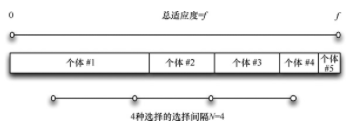
随机遍历抽样和以前看到的选择方法之间有一个非常重要的区别:当你同时选择所有需要的个体时,SUS的效果最佳。先前的选择方法分别选择个体。
以固定间隔来选择的个体。该线的最左侧位置是生成的唯一随机数,它介于0和每条线段的长度之间。每条线段均等于f/N(总适应度除以请求的个体数量)。一旦选择了这个初始随机点,就可以通过向前移动来选择其他每个个体。
def stochastic_universal_sampling(population,N){
f = 0
for individual in population:
f = f+individual.score
p=f/N
start = random_uniform(0,p)
points = []
for i from 0 to (N-1):
points[i]=start+(i*p)
selected = []
i=0
for p in pointd:
while population[i].score<p:
i=i+1
selected.add(population[i])
return selected
}
SUS从计算种群总体得分开始。SUS还要求对种群进行排序.尽管SUS在少数分数较高的个体主导适应度比例选择的情况下很有用,但是该算法在大数据和高度并行化的情况下效果不佳。当一个高分的个体主导选择时,联赛选择是一个很好的选择。联赛选择不会有某个个体占主导地位,因为每个个体都有参加联赛的机会。SUS可能会选拔非常弱小的个体,但是在联赛中它们总是会被淘汰。这个结果可能是理想的,也可能不理想。
如何选择一种算法
联赛选择的主要缺点在于,非常弱的个体往往很早就被淘汰,没有机会经过几代来优化和适应。这个结果可能导致种群止步于已经获得的最佳分数。如果你没有使用物种形成,并且种群仍处于停滞状态,则可能要尝试随机遍历抽样。这种选择允许某些时候选择较弱的成员。如果性能是问题,可以禁用排序。你仍然必须跟踪种群的总适应度,但是,总适应度可以计算一次,然后随着种群的出生和死亡进行调整。这些调整可以使随机遍历抽样具有相当的可扩展性和可并行性。















 4380
4380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









