







本文重点主要有:
- 聚类
- 质心
- 非监督训练
- K均值算法
理解训练集
多组观测值通常被划分为称作“训练集”的大型集合,这些数据都被用于训练机器学习算法。“训练”指的是通过调整算法的内部状态,使得机器学习算法的输出符合预期输出的过程。
按所使用的训练集不同,机器学习算法宽泛地分为两类:监督学习和非监督学习。在非监督学习过程中,你仅仅向算法提供向量形式的输入数据,但却不设置预期输出;聚类算法就是一种非监督学习。
非监督学习
以鸢尾花的数据集为例来了解监督学习和非监督学习的过程。
这个数据集由与鸢尾花花瓣和花萼尺寸有关的4个比率量组成,还有一个“种属”量指明了每个鸢尾花的种类。
示例如下:

就非监督的聚类算法而言,我们最可能用到的是前4个量而忽略“种属”这个量。在进行比较之后我们可能会给这些数据打上标签,但由于是非监督学习,聚类算法并不需要知道哪个数据属于哪个“种属”。这个算法的目的不在于判断某个鸢尾花属于什么种类,而在于按相似度把这些数据分为几簇。
另外还要注意一个问题,就是这4个观测值都不必进行归一化,K均值聚类算法本身并不需要归一化的过程;当然这并不是说别的算法也不需要。就对这个鸢尾花数据集进行聚类的问题而言,归一化的过程是可有可无的。要是数据的一个或多个特征量过大,以致掩盖了其他的特征量,就一定要先将数据归一化;在本例中,鸢尾花数据集的四个比率量特征值在数值上都比较接近,因此并不一定要将数据进行归一化处理。
鸢尾花数据集中的4个比率量特征值提供的信息并不足以将它按“种属”分类;这完全没有关系,就聚类这个操作而言,我们只是想看看这些数据之间到底有多相似,以及这些数据究竟可以被分为多少组。
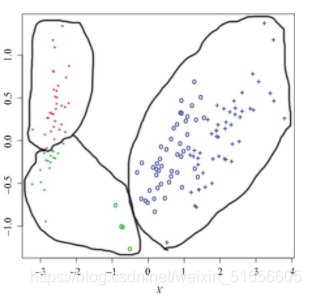
在上图中,各个分好的簇按颜色在图上标注了出来,并且都用曲线围了起来,以便在黑白媒介上也能够区分这些簇。
如果聚类算法能够正确地区分鸢尾花的种类,那么同种符号就应当是同样的颜色;
我们可以看到的簇与簇之间边界十分明晰,但很显然它们并不是按照“种属”这个属性来划分的,这一点几乎无法避免。由于随机性,K均值算法有时确实会得到与按种类划分相近的结果。在上图中簇与簇之间是线性可分的(“线性可分”的意思是可以通过画一条直线把它们分隔开来),而鸢尾花的不同种类之间却不是线性可分的。种类与种类之间存在一部分重叠的区域,仅靠非监督的聚类算法是不可能将两个种类区分开来的。
监督学习
监督学习的限制比非监督学习要高一些,其中的训练集要由输入数据和预期输出组成的成对数据构成。就鸢尾花数据集而言,你要输入4个比率量观测值作为一个四维输入向量,可能还需要用突显编码法将“种属”数据编码为预期输出向量。机器学习算法的性能由给定输入时,产生对应的预期输出的比例来评估。
理解K均值算法
K均值算法实现起来比较简单,效果主要是将数据划分为指定数量的集群。其中,算法的实现有3个泾渭分明的步骤:
- 初始化(两种方法)
- 分配
- 更新
分配
“分配”和“更新”两步会不断重复,直到再也没有新的数据需要划分到新的簇中。每一个簇都会从两方面来定义。首先是“质心”。“质心”也是一个与被聚类数据等长的向量,实际上其本身就是一个数据,只不过表示的是簇内数据的平均值。因此,“质心”究其本质是簇内所有数据的中心点。除了“质心”外,每个簇还有一个由分配给各个簇的数据组成的列表。
“分配”这一步会对所有数据进行循环,并把每个数据分配到其质心与该数据最接近的簇中去。其中“最近”指的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2307
2307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









