








基于深度学习的图像增强操作旨在改善图像质量并提高视觉识别系统的性能。通过对图像进行预处理和增强,可以使其更加清晰、明亮、鲜明,消除噪声、模糊、失真等问题,从而提高图像的可读性和可解释性。
复现YOLO代码时遇到了一系列的图像增强操作,接下来从原理到代码进行总结。
🎏目录
🎈1 图像增强
🎄1.1 随机改变图像亮度
🎄1.2 转换颜色空间
🎄1.3 随机改变饱和度
🎄1.4 改变色调
🎄1.4 改变颜色平衡
🎈2 零填充
🎈3 随即水平翻转
🎈4 随即裁剪
🎈5 Resize
🎈6 打包
✨ 1 颜色增强
class PhotometricDistort:
def __init__(self):
self.pd = [
RandomContrast(), # 改变光暗
ConvertColor(current="BGR", transform="HSV"), # 颜色空间BGR到HSV
RandomSaturation(), # 改变图像饱和度
RandomHue(), # 改变图像色调
ConvertColor(current="HSV", transform="BGR"), # 颜色空间HSV到BGR
RandomContrast(), # 改变光暗
]
self.rand_brightness = RandomBrightness() # 改变图像颜色平衡
def __call__(self, image, bboxes, labels):
image, bboxes, labels = self.rand_brightness(image, bboxes, labels)
if random.randint(2):
transforms = Compose(self.pd[:-1])
else:
transforms = Compose(self.pd[1:])
image, bboxes, labels = transforms(image, bboxes, labels)
return image, bboxes, labels
该类是颜色增强的主要类:
__init__中的self.pd储存了颜色增强需要做的事情:改变图像光暗,颜色空间,图像饱和度,图像色调。__init__中的self.rand_brightness储存的操作改变图像整体亮度和打破图像颜色平衡。
下面对这部分进行总结
🎄 1.1 随机改变图像亮度
假设我们有一张图像,其大小为(h, w, c),每个像素点的值确定。
此时我们同时对该图像矩阵所有值乘小于1大于0的数,则相当于相当于把整个图像在每个颜色通道上缩小了一定的比例,这样就会导致图像亮度的降低。
而如果同时对该图像矩阵所有值乘大于1的数,则相当于相当于把整个图像在每个颜色通道上扩大了一定的比例,这样就会导致图像亮度的变高。
Code:
class RandomContrast: # 英文命名不对,需要改
def __init__(self, lower=0.5, upper=1.5):
self.lower = lower
self.upper = upper
assert self.upper >= self.lower, "contrast upper must be >= lower."
assert self.lower >= 0, "contrast lower must be non-negative."
def __call__(self, image, boxes=None, labels=None):
if random.randint(2): # Randomly take True or False
alpha = random.uniform(self.lower, self.upper) # take value between lower and upper
image *= alpha
return image, boxes, labels
其中random.randint(2)在1和0之间随机取值,增加了随机性。alpha = random.uniform(self.lower, self.upper)在0.5到1之间取值。image *= alpha等比例缩小或扩大图像像素值,使图像亮度升高或降低。
🎏 1.2 转换颜色空间
HSV颜色模型,全称是Hue Saturation Value,也称作HSB(Brightness),它是一种描述颜色的方式。
与常见的RGB颜色模型有所不同,HSV颜色模型将颜色分为三个属性:
1.色调(Hue):表示颜色在色轮上的位置,取值范围为0~360度。其中,红色位于0度位置,绿色位于120度位置,蓝色位于240度位置。这种表示方法能够很好地表达出不同颜色之间的关系,例如红色、黄色、绿色等颜色呈现在色轮上的位置,使得人们能够更加直观地理解和操作颜色信息。
2. 饱和度(Saturation):表示颜色的纯度或鲜艳程度,取值范围为0~100%。当饱和度为0时,颜色呈现出灰度效果;当饱和度为100%时,颜色最纯净、最饱和。这种形式的表达方式更直观,能够很好地反映出颜色的强度和纯度。
3. 明度(Value/Brightness):表示颜色的亮暗程度或亮度,取值范围为0~100%。当明度为0时,颜色呈现出黑色;当明度为100%时,颜色呈现出白色。与RGB模型不同的是,HSV模型中的明度是一种与色彩分离的属性,它能够更好地描述颜色的亮度和对比度,也更易于图像增强和调整。
基于上面三点,通过HSV颜色模型可以更直观地描述和处理颜色信息。特别是在图像识别、图像增强、图像分割等领域中应用广泛。例如,在图像检测中,可以利用HSV颜色空间来提取出特定颜色范围内的像素,并减少光照、阴影等因素对检测结果的干扰,进而增强图像的识别效果。同时,还可以利用HSV颜色模型进行图像增强、调整色彩平衡等操作,进一步提高图像的质量和观感效果。
Code:
class ConvertColor:
def __init__(self, current='BGR', transform='HSV'):
self.transform = transform
self.current = current
def __call__(self, image, boxes=None, labels=None):
if self.current == 'BGR' and self.transform == 'HSV':
image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
elif self.current == 'HSV' and self.transform == 'BGR':
image = cv2.cvtColor(image, cv2.COLOR_HSV2BGR)
else:
raise NotImplementedError
return image, boxes, labels
上述只支持从BGR=>HSV和HSV=>BGR。利用的是opencv库的函数cvtColor(img, type)
✨ 1.3 随机改变饱和度
self.pd中储存的增强操作顺序即执行顺序,因此该这里总结是以在颜色空间HSV中为准的。
在颜色空间为HSV时,图像三个维度(0, 1, 2)代表的是(色调,饱和度,明亮)。
这里,复习一下HSV中的饱和度:表示颜色的纯度或鲜艳程度,取值范围为0~100%。当饱和度为0时,颜色呈现出灰度效果;当饱和度为100%时,颜色最纯净、最饱和。
用一个大于1的数乘图像第二通道(饱和度S通道),可以增强图像的整体饱和度,使得颜色更加鲜艳明亮。而用一个在0和1之间的数乘图像第二通道(饱和度S通道),会降低图像的整体饱和度。因此,具体做法是等比例缩小或扩大HSV空间中图像第二通道的值。
Code:
class RandomSaturation:
def __init__(self, lower=0.5, upper=1.5):
self.lower = lower
self.upper = upper
assert self.upper >= self.lower, "contrast upper must be >= lower."
assert self.lower >= 0, "contrast lower must be non-negative."
def __call__(self, image, boxes=None, labels=None):
if random.randint(2):
image[:, :, 1] *= random.uniform(self.lower, self.upper)
return image, boxes, labels
random.randint(2)随机取值0或1。image[:, :, 1]即代表饱和度的图像通道,random.uniform(self.lower, self.upper)在0.5到1之间随机取值,等比例缩小或扩大图像第二通道的值,即增强或降低图像饱和度。
🍕 1.4 改变色调
与改变饱和度很像。
这里进行该操作,仍然在颜色空间HSV中进行,其中第一通道代表色调。
色调表示颜色在色轮上的位置,取值范围为0~360度。其中,红色位于0度位置,绿色位于120度位置,蓝色位于240度位置。
改变色调即使该图像中的所有颜色整体偏移,具体做法是对该通道加或减去同一个数。
Code:
class RandomHue:
def __init__(self, delta=18.0):
assert delta >= 0.0 and delta <= 360.0
self.delta = delta
def __call__(self, image, boxes=None, labels=None):
if random.randint(2):
image[:, :, 0] += random.uniform(-self.delta, self.delta)
image[:, :, 0][image[:, :, 0] > 360.0] -= 360.0
image[:, :, 0][image[:, :, 0] < 0.0] += 360.0
return image, boxes, labels
image[:, :, 0] += random.uniform(-self.delta, self.delta)即使该图像中的所有颜色整体偏移。
但是需要注意的是,该操作可能使该通道数值不在0~360之间。因此,后面两句image[:, :, 0][image[:, :, 0] > 360.0] -= 360.0和image[:, :, 0][image[:, :, 0] < 0.0] += 360.0将大于360的数值减360,小于0的数值加360,这种循环移位操作可能会改变图像中不同颜色之间的关系,但不会改变整体颜色分布。
🐬1.5 改变颜色平衡
该部分具体操作是将BGR空间上的图像所有像素值加或减一个数,会起到两方面的作用:
- 整体图像像素值便大或变小,因此亮度对应变大或变小。但是由于不是等比例变化,不同地方亮度变化会不一致。
- 对于同一个位置的点,三个通道的值不是等比例变化,因此结合起来显现的颜色发生改变,则图像的颜色平衡就放生了改变。
Code:
class RandomBrightness:
def __init__(self, delta=32):
assert delta >= 0.0
assert delta <= 255.0
self.delta = delta
def __call__(self, image, boxes=None, labels=None):
if random.randint(2):
delta = random.uniform(-self.delta, self.delta)
image += delta
return image, boxes, labels
✨ 2 零填充
该操作将图像扩大,扩大的部分用0填充。假设我们有图像(h, w, c),其中有个目标(橙色框):

具体操作如下:
- 随机生成扩大因子,这里假设为r
- 生成扩大后的图像模板,大小为(h+rh, w+wr, c)

- 将原图放置到图像模板右下角
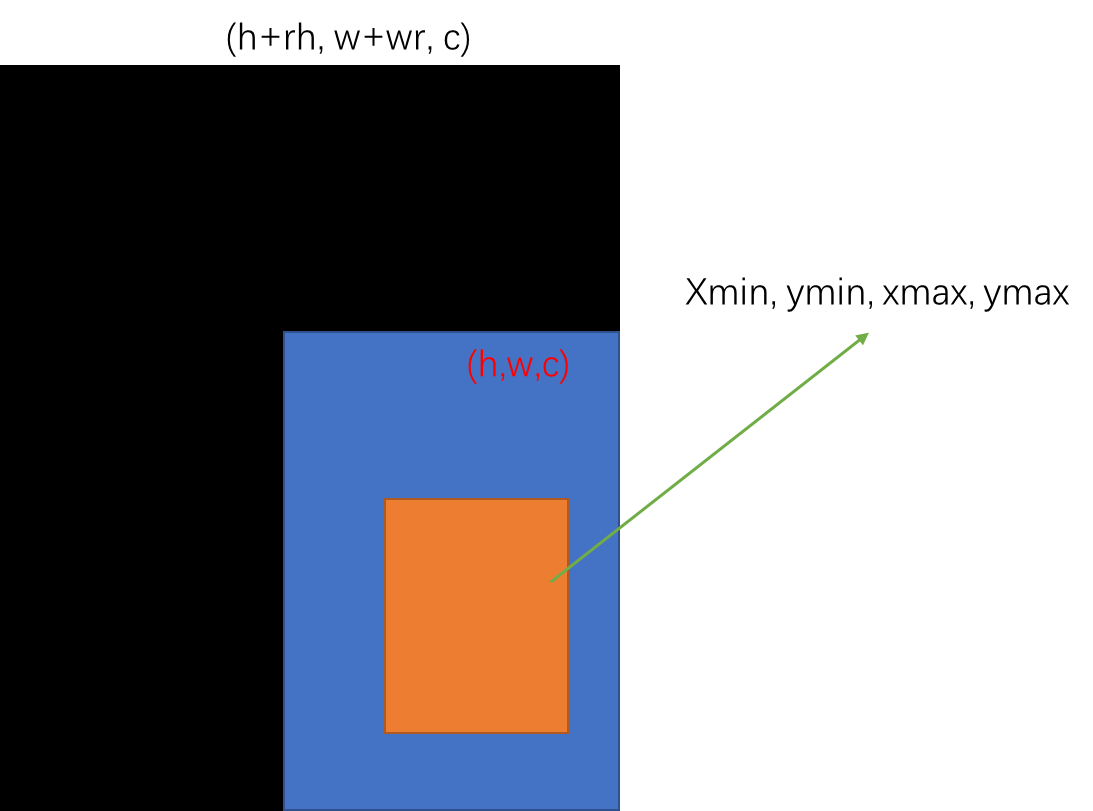
- 重新计算包含目标的矩形框坐标
(xmin, ymin, xmax, ymax),公式为:
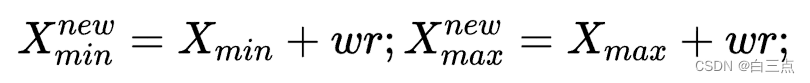
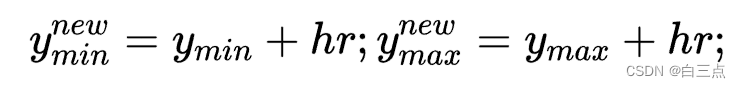
Code:
class Expand:
def __call__(self, image, bboxes, labels):
if random.randint(2):
return image, bboxes, labels
height, width, depth = image.shape
ratio = random.uniform(1, 4)
left = random.uniform(0, width * ratio - width)
top = random.uniform(0, height * ratio - height)
expand_image = np.zeros((int(height * ratio), int(width * ratio), depth), dtype=image.dtype)
expand_image[int(top):int(top + height), int(left):int(left + width)] = image
image = expand_image
boxes = bboxes.copy()
boxes[:, :2] += (int(left), int(top))
boxes[:, 2:] += (int(left), int(top))
return image, boxes, labels
expand_image = np.zeros((int(height * ratio), int(width * ratio), depth), dtype=image.dtype)对于第二步,生成图像模板expand_image[int(top):int(top + height), int(left):int(left + width)] = image对于第三步,将原图放置在模板右下角boxes[:, :2] += (int(left), int(top))和boxes[:, 2:] += (int(left), int(top))即重新计算含目标的矩形框坐标,其中left=wr,top=hr。
✨ 3 随机水平翻转
随机水平翻转,即将图像在x方向反过来。
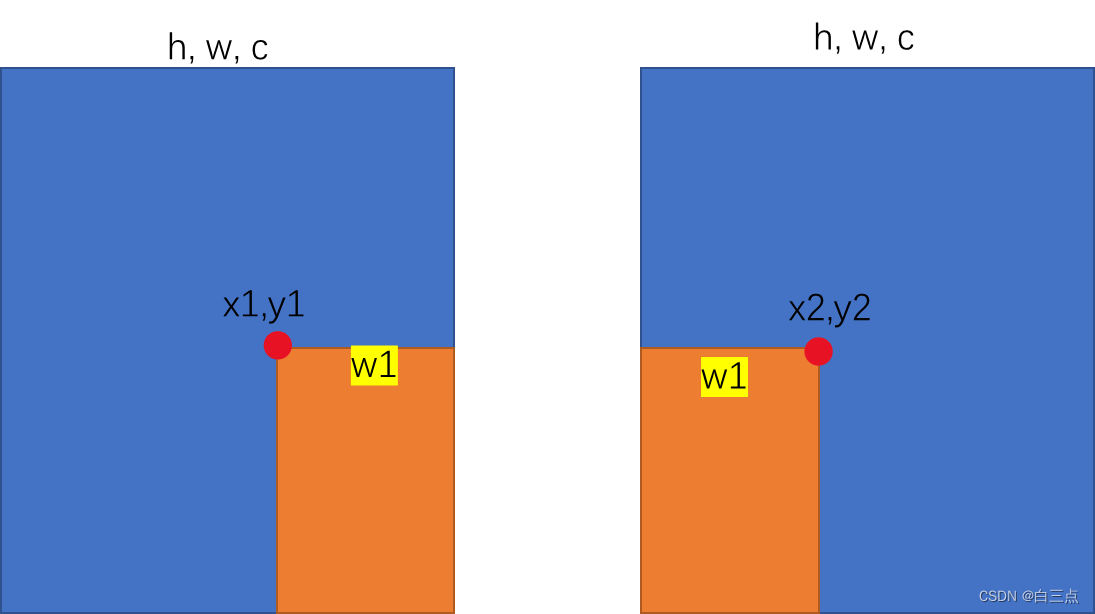
对于x轴,从左侧很容易看出,x1+w1=w。而从右侧,很容易得到x2=w1。则x2=w-x1。
y轴方向由于未作出改变,因此坐标不变,即y2=y1。
其余点坐标也是如此。
因此总结一下,水平翻转后:
- x1坐标发生变化,变化后的横坐标x2计算公式为
x2=w-x1(w为矩形框的宽) - y坐标不发生变化
Code:
class RandomHorizontalFlip:
def __call__(self, image, boxes, classes):
_, width, _ = image.shape
if random.randint(2):
image = image[:, ::-1]
boxes = boxes.copy()
boxes[:, 0::2] = width - boxes[:, 2::-2]
return image, boxes, classes
其中,image = image[:, ::-1]将图像水平翻转,image的第一维度代表纵坐标,不发生变化,而第二维度代表横坐标,将像素点左侧和右侧对调。boxes[:, 0::2] = width - boxes[:, 2::-2]计算新的横坐标。
✨ 4 随机裁剪
随机裁剪,即随机将图像一部分截取下来。
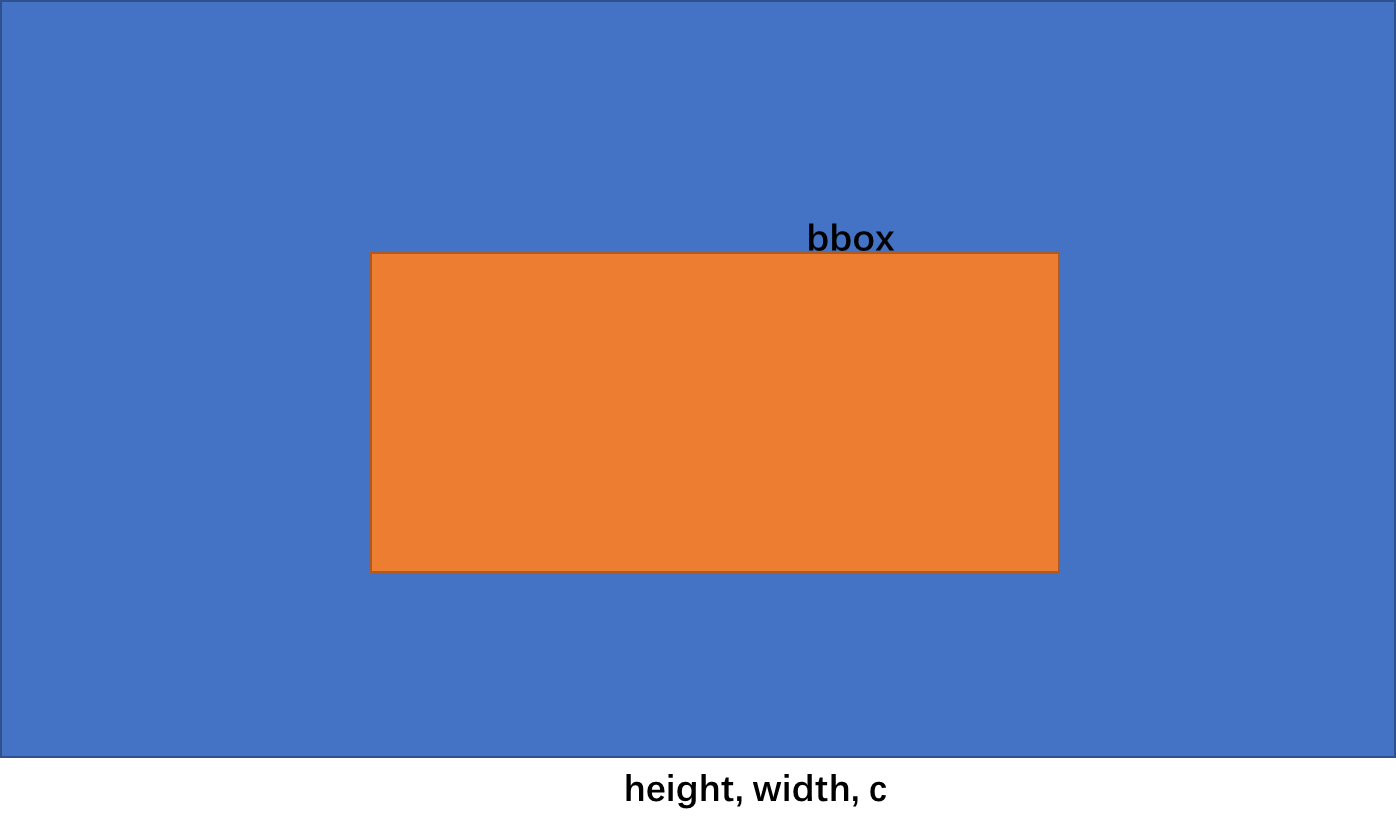
如上图,假设我们有一个含一个目标(bbox)的图像(h, w, c),具体做法为:
- 确定截取高和宽(如果截取图像高/宽大于2或小于0.5从新截取),生成截取图像模板

- 确定该模板在原图中的位置(紧贴右下角)
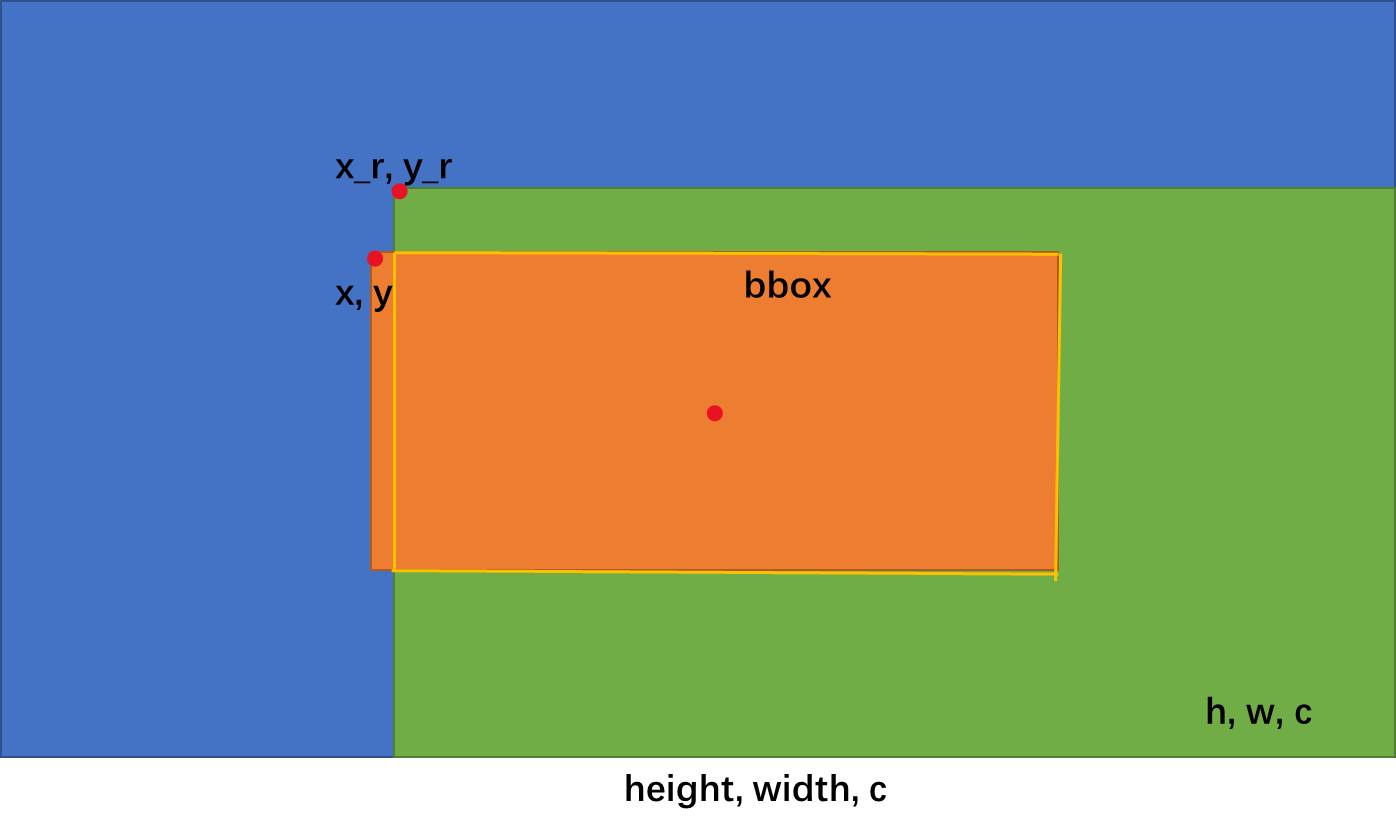
- 计算目标框和截取矩形的IOU,若该IOU不在规定范围内,返回第一步
- 计算目标框的中心点,如果不在截取的图像范围内,返回第一步
- 计算目标框在截取图像中的坐标
========================================================
a). 如果目标框含有不在截取图像内,则去掉不在的部分。以上图为例,x<x_r,即目标框左侧不在截取后的图像中。则需要把标注的目标框左侧x坐标更新为x_r(截取图像左侧在原图的位置),最终bbox坐标代表的矩形框为黄色线包围的位置。
b).此时需要把目标bbox在原图位置(xmin, ymin, xmax, ymax),截取图像在原图中的位置(x1, y1, x2, y2)。我们需要把利用公式把bbox在原图坐标转化为在截取图像中的坐标位置:
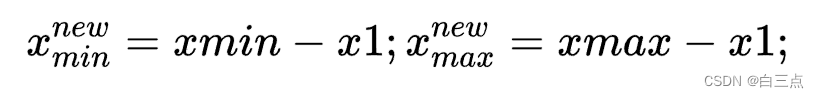
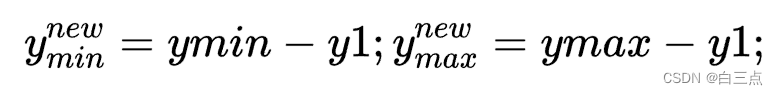
Code:
class RandomSampleCrop:
def __init__(self):
self.sample_options = (
# using entire original input image
None,
# sample a patch s.t. MIN jaccard w/ obj in .1,.3,.4,.7,.9
(0.1, None),
(0.3, None),
(0.7, None),
(0.9, None),
# randomly sample a patch
(None, None),
)
def __call__(self, image, boxes=None, labels=None):
height, width, _ = image.shape
# check
if len(boxes) == 0:
return image, boxes, labels
while True:
# randomly choose a mode
sample_id = np.random.randint(len(self.sample_options))
mode = self.sample_options[sample_id]
if mode is None:
return image, boxes, labels
min_iou, max_iou = mode
if min_iou is None:
min_iou = float('-inf')
if max_iou is None:
max_iou = float('inf')
# max trails (50)
for _ in range(50):
current_image = image
w = random.uniform(0.3 * width, width)
h = random.uniform(0.3 * height, height)
# aspect ratio constraint b/t .5 & 2
if h / w < 0.5 or h / w > 2:
continue
left = random.uniform(width - w)
top = random.uniform(height - h)
# convert to integer rect x1,y1,x2,y2
rect = np.array([int(left), int(top), int(left + w), int(top + h)])
# calculate IoU (jaccard overlap) b/t the cropped and gt boxes
overlap = jaccard_numpy(boxes, rect) # (rect ∩ bbox) / (rect ∪ bbox)
# is min and max overlap constraint satisfied? if not try again
if overlap.min() < min_iou and max_iou < overlap.max():
continue
# cut the crop from the image
current_image = current_image[rect[1]:rect[3], rect[0]:rect[2], :]
# keep overlap with gt box IF center in sampled patch
centers = (boxes[:, :2] + boxes[:, 2:]) / 2.0
# mask in all gt boxes that above and to the left of centers
m1 = (rect[0] < centers[:, 0]) * (rect[1] < centers[:, 1])
# mask in all gt boxes that under and to the right of centers
m2 = (rect[2] > centers[:, 0]) * (rect[3] > centers[:, 1])
# mask in that both m1 and m2 are true
mask = m1 * m2
# have any valid boxes? try again if not
if not mask.any():
continue
# take only matching gt boxes
current_boxes = boxes[mask, :].copy()
# take only matching gt labels
current_labels = labels[mask]
# should we use the box left and top corner or the crop's
current_boxes[:, :2] = np.maximum(current_boxes[:, :2], rect[:2])
# adjust to crop (by substracting crop's left,top)
current_boxes[:, :2] -= rect[:2]
current_boxes[:, 2:] = np.minimum(current_boxes[:, 2:], rect[2:])
# adjust to crop (by substracting crop's left,top)
current_boxes[:, 2:] -= rect[:2]
return current_image, current_boxes, current_labels
# 本质上是计算交并比
def jaccard_numpy(box_a, box_b):
inter = intersect(box_a, box_b) # 目标的框被裁剪后的面积
area_a = (box_a[:, 2] - box_a[:, 0]) * (box_a[:, 3] - box_a[:, 1]) # [A,B]
area_b = (box_b[2] - box_b[0]) * (box_b[3] - box_b[1]) # [A,B]
union = area_a + area_b - inter
return inter / union # [A,B]
def intersect(box_a, box_b):
max_xy = np.minimum(box_a[:, 2:], box_b[2:])
min_xy = np.maximum(box_a[:, :2], box_b[:2])
inter = np.clip((max_xy - min_xy), a_min=0, a_max=np.inf)
return inter[:, 0] * inter[:, 1]
✨ 5 Resize
图像整体不变,缩放图像。同时需要按照比例改变bbox标注信息。
假设,原图为(h, w),缩放至(h_new, w_new),则坐标计算公式为:
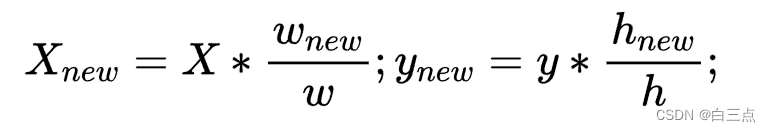
Code:
class Resize:
def __init__(self, img_size=640):
self.img_size = img_size
def __call__(self, image, boxes=None, labels=None):
orig_h, orig_w = image.shape[:2]
image = cv2.resize(image, (self.img_size, self.img_size))
# rescale bbox
if boxes is not None:
img_h, img_w = image.shape[:2]
boxes[..., [0, 2]] = boxes[..., [0, 2]] / orig_w * img_w
boxes[..., [1, 3]] = boxes[..., [1, 3]] / orig_h * img_h
return image, boxes, labels
✨ 6 打包
最后为了可以更方便的使用上面的操作,我们进行打包。
Code:
class Compose:
def __init__(self, transforms: list):
self.transforms = transforms
def __call__(self, img, boxes=None, label=None):
for transform in self.transforms:
img, boxes, label = transform(img, boxes, label)
return img, boxes, label
self.transforms是一个列表,里面即存储了各种数据增强操作。__call__,通过遍历进行一项项增强操作。
__call__重载括号,具体用法见Python 实例方法
















 206
206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











