






一、了解决策树
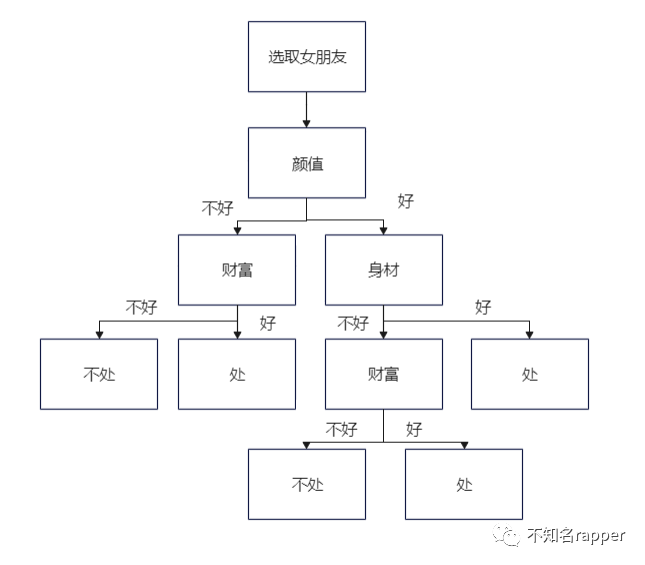
假设咱已经相处了10000个女朋友,我们对一个新的女生是否可以交往有了一定的判断,比如先看脸,再看身材等等,最后判断这个女生是否能进行交往。决策树的思路就是如此。
二、前置知识
熵
高中化学就接触到了这个概念,表示物质混乱程度。而在信息论与概率统计中,表示的是随机变量不确定性的度量。熵越大,不确定性越大,熵的计算公式如下(其中X表示随机变量,pi表示第i类的先验概率):
信息增益
假设现在有一个骰子,有六种可能,我们猜中他点数的可能为六分之一,不确定性较大(也就是熵大)。假设现在有个看了结果的人告诉我们这个点数是一个偶数,那么只剩下三种情况,我们猜中的概率变大为三分之一(不确定性降低,也就是熵小),概率增加的过程其实也就是信息增益值为正数的过程。就像我们现在所说的废话文学他的信息增益为0!具体计算公式如下(表示信息A对D训练集的信息增益):
信息增益比
信息增益比:对于信息增益的公式,当我们把H(D)看作一个常量,先验概率相同的情况下,对于分类情况多的特征的信息增益会大于分类情况较少的,这样子当我们在选取节点特征时会偏向于特征分类树较多的,为了防止这种情况,就有了信息增益比,计算公式如下:
三、基础模型——ID3算法
ID3算法时通过遍历计算不同特征对于当前节点的信息增益,选取信息增益大的特征作为节点创建一个树,接着由该特征的分类情况作为子节点,再对子节点重复计算其他不同特征的信息增益,最后构建出决策树,最后的叶子节点即为最终的分类结果。
具体实例:假设给一批你已经交往过的女朋友特征数据(颜值,身高,体重,财富),再给了一个新的女生数据让你判断该女生是否适合交往。计算步骤如下:
1.计算目前节点各类情况的先验概率(即占比)
2.计算目前节点熵值H(D)
3.计算在某一类情况之下的先验概率p(X|A)
4.计算各特征信息增益g = H(D) - H(D|A/B/C...),并进行比较,较大值作为目前节点,该类的分类情况作为子节点
5.重复1-4,直至没有节点可选
以上就是理想状态下的决策树生成步骤,但是在很多情况下,有些特征的信息增益是几乎为0的,就比如一个女生是否在幼儿园拿过奖,这个特征是几乎不会影响我们的选择的,因此我们需要设置一个阈值,在选取特征节点的时候,当该待选取特征信息增益小于该阈值时就不选取该特征;若剩下的特征信息增益均小于该阈值,则当前节点为叶子节点。
四、ID3算法的不足
-
不能处理连续特征,比如身高的取值,我们只能用离散值特征进行分类。
-
ID3算法容易造成过拟合。
五、剪枝操作
由于ID3算法以及C4.5都是对样本进行彻底的训练一直到无法训练,这样很容易对训练数据过度拟合,导致测试数据的结果不准确。为了防止过拟合现象,就有了剪枝操作,顾名思义就是对已经生成的决策树进行砍枝操作,使得剪枝后的树结构不复杂。
对于原来的树的结构,我们对训练结果的好坏可以用一个损失函数定义:
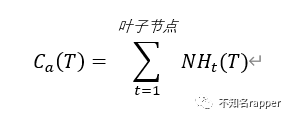
其中N为叶子节点的样本树,Ht为叶子节点的熵,对于未剪枝的决策树,这个损失函数永远是最小的,但是树的复杂程度也是最大的,换句话说也就是叶子节点T最大,因此为了防止过拟合就是要减少叶子节点的个数,所以我们可以把损失函数定义为:

其中a是超参数,当a=0时,即为未剪枝情况,在保证损失函数尽可能小的情况下,当a越来越大时,我们只能使得叶子节点T越来越小,也就是树的结果越来越简化。















 5951
5951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









