





决策树本质上是通过一系列规则对数据进行分类的过程。
它是一个类似于流程图的树结构,其中每一个树节点表示一个属性上的测试,每一个分支代表一个属性的输出,每一个树叶节点代 表一个类或者类的分布,树的最顶层是树的根节点。
决策树的基本概念
首先我们看一下下面这张表,这个表富含的信息是:用天气、温度,湿度等状况来决定是否出去玩。

Outlook、Temperature、Humidity、Windy是一个个特征,这些特征由信息量组成,是否Play是根据这些特征所预测出的一个结果。
可以说,决策树是通过给出的信息量去预测一个结果。
优缺点
优点:计算量少,显示清晰
缺点:过拟合
(过拟合:指为了得到一致假设而使假设变得过度严格。避免过拟合是分类器设计中的一个核心任务。通常采用增大数据量和测试样本集的方法对分类器性能进行评价。)
决策树算法的分类
·ID3算法:使用信息增益作为分裂的规则,信息增益越大,则选取该分裂规则。
·C4.5算法:使用信息增益率作为分裂规则,此方法避免了ID3算法中的归纳偏置问题,因为ID3算法会偏向于选择类别较多的属性(形成分支较多会导致信息增益大)。
·CART算法:既可以做分类,也可以做回归。只能形成二叉树。
信息熵
在信息论中,熵(entropy)是随机变量不确定性的度量,也就是熵越大,则随机变量的不确定性越大。
过拟合是因为我们在所选择的信息对于结果的过度严格出现的现象,因此熵是用来描述信息源对结果的影响程度。
设X是一个取有限个值得离散随机变量,其概率分布为:
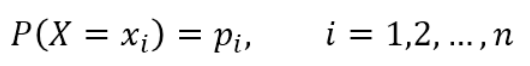
信息熵的公式:
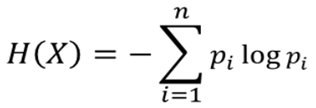
由上式知道,信息量越小,熵越小,信息量越大,熵越大。
信息增益
我们知道决策树是由一个节点出发依次判断的,最开始的那个节点称为根节点,那么如何确定根节点呢?
根节点一般是对结果影响最大的那个,例如在你报考大学的时候,有你的朋友、周边亲戚、父母给你建议,那么谁的影响更大呢?是父母(大多数情况下),所以父母此时就作为根节点。
特征对结果的影响程度用信息增益来衡量。
信息增益表示由于得知特征A的信息后而使得数据集D的分类不确定性减少的程度,定义为:
Gain(D,A) = H(D) – H(D|A)
即集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(H|A)之差。
选择划分后信息增益大的作为划分特征,说明使用该特征后划分得到的子集纯度越高,即不确定性越小。
因此我们总是选择当前使得信息增益最大的特征来划分数据集。
决策树的构造过程
决策树的构造过程一般分为三个部分,特征的选择,决策树的生成以及剪枝。
01 特征的选择
特征选择表示从众多的特征中选择一个特征作为当前节点分裂的标准,如何选择特征有不同的量化评估方法,从而衍生出不同的决策树。
如ID3通过信息增益选择特征;C4.5通过信息增益比选择特征;CART通过Gini指数选择特征······
·计算系统熵
一共有14条记录,值为yes的9条,值为no的记录为5条,称这个样本里有9个正例,5个负例,熵记为:E(S)

·以wind为例计算熵和信息增益
在wind中,值为false的记录有8条,正例6个,负例2个,值为true的记录有6条,正例3个,负例3个,计算相应的熵:
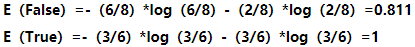
计算wind信息增益:
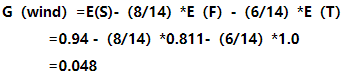
接下来我们用同样的方法计算其余特征的信息增益:
·Humidity
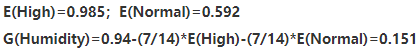
·Outlook

·Temperature
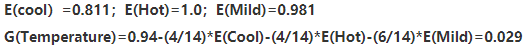
可以看到天气(Outlook)的信息增益最大,因此天气是决定出不出去玩的重要影响因素,因此Outlook是根节点。
02 决策树的生成
根据选择的特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树停止生长。
这个过程实际上就是使用满足划分准则的特征不断的将数据集划分成纯度更高,不确定行更小的子集的过程。
对于当前数据集的每一次划分,都希望根据某个特征划分之后的各个子集的纯度更高,不确定性更小。
根据特征选择的数据,由上至下可以画出这棵决策树。
·由特征选择的结果可知,信息增益最大的特征是Outlook,得出第一步如下图所示;
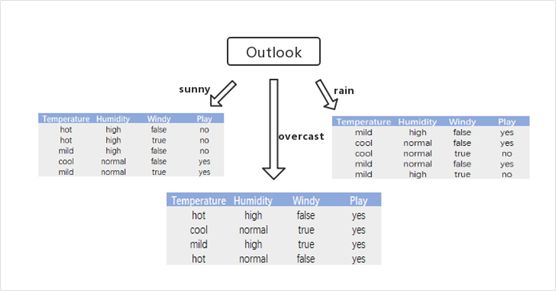
·上图中,针对sunny中的子训练数据集分支,有两个类别,该分支中有3个实例属于no类,有2个实例属于yes类,求类别属性新的信息熵以及三个类别的信息增益,选出信息增益最大的为Humidity。(计算方法与特征选择一样,不再一一展示)
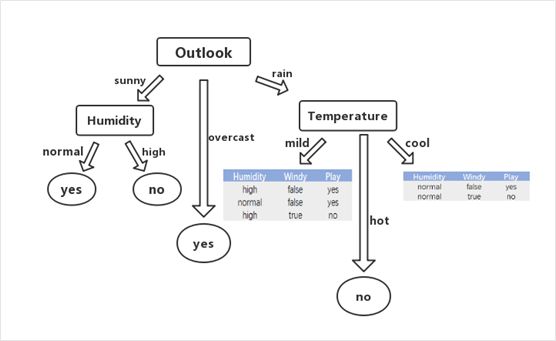
·在mild对应的数据子集中,Humidity和windy的信息增益是相同的,因为在该分组中,yes元组的比例比no元组的大,所以直接写yes;在cool对应得子集中,直接将两个结果分开即可,最终得到的决策树图如图所示:

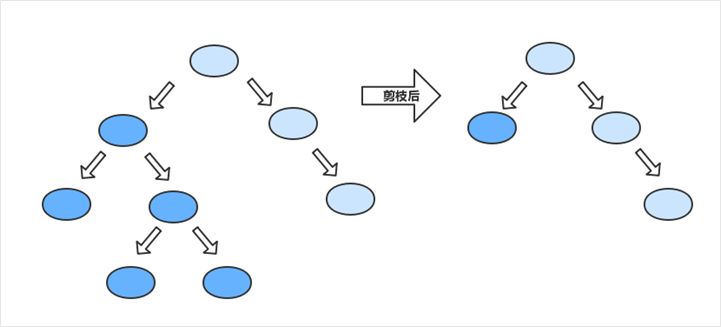
03 决策树的裁剪
决策树容易过拟合,一般需要剪枝来缩小树结构规模、缓解过拟合。
在上面的例子当中,我们使用的是ID3的算法,以信息熵为度量,用于决策树节点的属性选择,每次优选信息量最多的属性,以构造一颗熵值下降最快的决策树,到叶子节点处的熵值为0,此时每个叶子节点对应的实例集中的实例属于同一类。
·先剪枝:当分到一定程度,就不向下增长树了
·后剪枝:把树完全建好后,根据类的纯度来进行树的裁剪
想要获取数据科学相关知识,请关注我们的公众号:DC学习助手















 1215
1215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









