






ResNet,全称为“残差网络”,是一种深度学习卷积神经网络(CNN)架构。它于2015年在题为“Deep Residual Learning for Image Recognition”的论文中首次提出。ResNet的设计目的是解决梯度消失问题,这个问题会使训练非常深的神经网络变得困难。
文章链接放置于此,读者有兴趣可以阅读:
链接:https://pan.baidu.com/s/18HLS9Q4nrU4ZdO2vpGTGJg?pwd=kp13
提取码:kp13
梯度消失问题
梯度消失问题它发生在反向传播(Backpropagation)算法中,当梯度值在网络的较深层次传播时逐渐变得非常小,甚至趋近于零,导致网络无法有效地学习参数,或者学习非常缓慢。这个问题的根本原因是链式法则(Chain Rule)在多层网络中的连续应用。在深度神经网络中,反向传播算法使用链式法则来计算每一层的梯度。每一层都要计算关于损失函数的梯度,然后将该梯度传递到前一层,这会导致连续应用链式法则。如果梯度值小于1(部分导数小于1),则在连续应用中梯度会指数级地减小,最终趋近于零。
这个问题可以通过batch normalization在很大程度上进行解决,但是随着网络的深度增加,精度也随之饱和,而后退化。我们先前认为深层网络可以学习到浅层网络学习到的事情,因为更深的网络只需要进行一一映射将先前网络的结果直接输出即可,但在实验上并非如此。
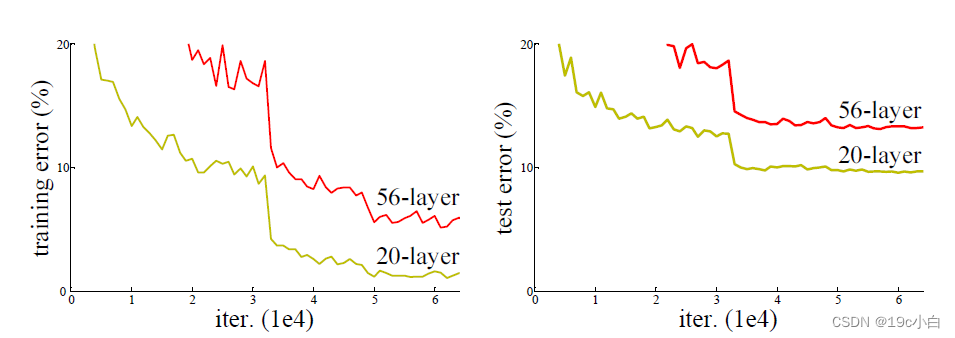
随着神经网络的深度增加,梯度消失问题会变得更加显著。每一层的梯度传播都会引入潜在的梯度消失问题,因此在深层网络中这一问题更容易出现。如图所示,这是论文中所举的一个例子,56层的network在训练集与测试集上的表现均不如20层的network。这与过拟合问题并不相同,过拟合是在训练集上表现的好,但是测试集上表现得差。
ResNet思想
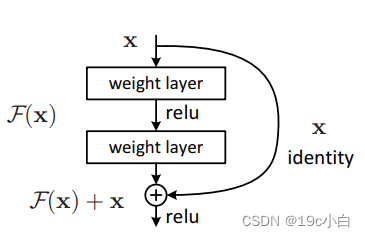
上图为残差块的模型,它与基本模型所不同的是它将输入x与经过隐藏层得到的F(x)相加之后的结果作为输出。如果模型所要求得的方程是H(x),那么隐藏层中所学到的将变为H(x)-x.这样如果一一对应是最优的化,那么直接将隐藏层的输出结果置为0即可。
这种方法既不额外增加参数,也不增加计算复杂度并且可以直接用bp算法求解。
ResNet解决梯度消失的方法
通过将求解函数从f(g(x))变为f(g(x))+g(x),我们进行求导可以发现,原有函数的求导值不变,但增加了g'(x)这一项,当导数小于1时,f(g(x))的导数会指数级的变化,但g(x)的导数变化会小一些,二者相加,大数加一个小数仍然是一个大数,可以有效缓解梯度消失问题。
参考资料:















 3083
3083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









