







Visual Attention 相关论文阅读笔记
SENet
github :https://github.com/hujie-frank/SENet
简介
使用 Squeeze-and-Excitation 模块即 SE 模块,以建模通道之间的依赖关系,自适应校准通道特征响应。说白了就是对每个通道的数据进行提取于变换后,再返回对通道进行加权,同时变换的参数是可学习的。
具体做法
SE block 是一个建立于变换之上的计算单元,当输入经过一个卷积变换 F t r F_{tr} Ftr 之后,由于输出的单个通道是通过对输入的所有通道与单个卷积核进行卷积后求和而得的,所以对通道的依赖在卷积操作上隐式存在。作者希望通过对该依赖进行显式建模,以提高网络的性能。
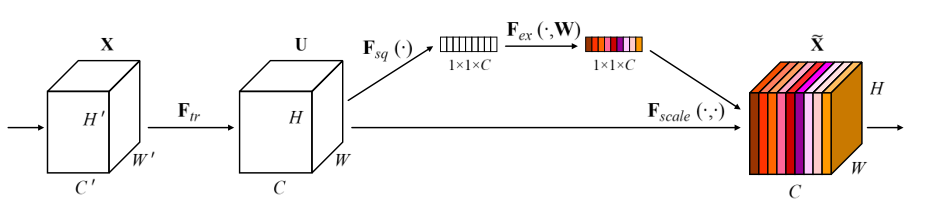
为了获取通道之间的依赖关系,需要先对每个通道的信息进行提取,作者使用的方式为对每个通道进行 GAP 操作,即全局平均池化。作者认为池化后的结果能够描述整个通道,也可以用更复杂的策略以提取通道特征。公式如下:
z
c
=
F
s
q
(
u
c
)
=
1
H
×
W
∑
i
=
1
H
∑
j
=
1
W
u
c
(
i
,
j
)
z_c = F_{sq}(u_c) = \frac{1}{H \times W} \sum_{i=1}^{H} \sum_{j=1}^{W}u_c(i,j)
zc=Fsq(uc)=H×W1i=1∑Hj=1∑Wuc(i,j)
为了完全捕获通道间的依赖关系,作者提出需要满足以下两点:
- 能够学习通道之间的非线性关系
- 多个通道能够同时被激活
为了满足以上需求,作者使用两个全连接层对通道权值进行非线性映射,在第一个全连接层后使用 ReLU 激活函数,第二个全连接层后使用 Sigmoid 激活函数。公式如下:
s
=
F
e
x
(
z
,
W
)
=
σ
(
g
(
z
,
W
)
)
=
σ
(
W
2
δ
(
W
1
z
)
)
s= F_{ex} (z,W) = \sigma (g(z,W)) = \sigma(W_2 \delta(W_1z))
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
最后将得到的通道权值乘回输出就完成了操作。
x
~
=
F
s
c
a
l
e
(
u
c
,
s
c
)
=
s
c
u
c
\widetilde x = F_{scale}(u_c, s_c) = s_cu_c
x
=Fscale(uc,sc)=scuc
一些别的
作者实验了在不同位置增加 SE block 的效果:
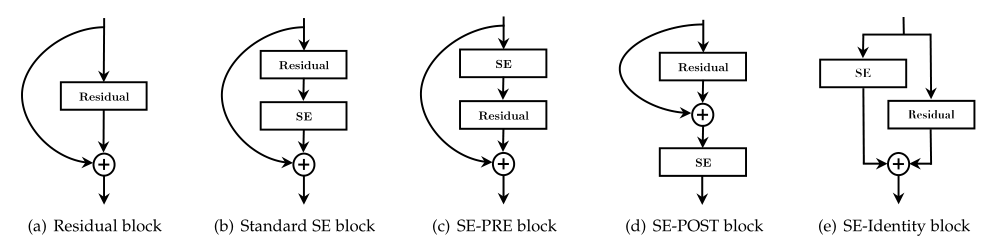
最后显示 Standard SE block 、 SE-PRE block 、 SE-Identity block 都不错。
SKNet
github :https://github.com/implus/SKNet
简介
SKNet 是 SENet 的升级版,在对通道进行加权的同时,对卷积核也进行了选择。其包含分割,融合,选择三个步骤。
在分割中,使用多个卷积核对输入分别进行卷积操作,得到多个结果。
在融合中,对多个卷积结果进行相加,然后使用与 SENet 相同的通道权值提取操作,得到一串通道权值。
在选择中,将通道权值与卷积核数量相同的预设矩阵进行相乘,将单个通道权值转换为多个的通道权值,且数量与卷积核数量相同,再进行 softmax 操作,后乘回卷积的结果,相加后输出。
具体操作
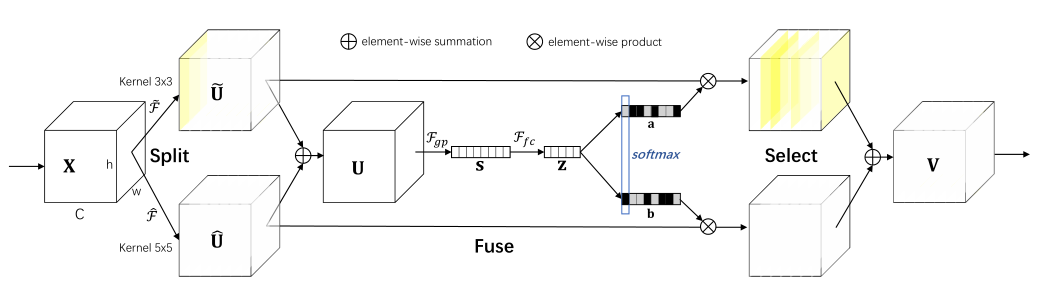
Split
对于输入 X X X , 使用多个不同的卷积核进行卷积操作,文中指出使用的都是深度卷积,并且在卷积之后都经过了 BN 以及 ReLU 激活函数,最终得到 U ~ \widetilde U U 与 U ^ \hat U U^。
Fuse
为了融合使用不同卷积核得到的结果信息,需要将
U
~
\widetilde U
U
与
U
^
\hat U
U^ 相加,得到
U
U
U,即:
U
=
U
~
+
U
^
U = \widetilde U + \hat U
U=U
+U^
与 SENet相同,使用 GAP 获取每个通道的信息:
s
c
=
F
g
p
(
U
c
)
=
1
H
×
W
∑
i
=
1
H
∑
j
=
1
W
U
c
(
i
,
j
)
s_c = F_{gp}(U_c) = \frac{1}{H \times W} \sum_{i=1}^{H} \sum_{j=1}^{W}U_c(i,j)
sc=Fgp(Uc)=H×W1i=1∑Hj=1∑WUc(i,j)
同样的,使用全连接层进行非线性变换:
z
=
F
f
c
(
s
)
=
δ
(
B
(
W
s
)
)
z = F_{fc}(s) = \delta (B(Ws))
z=Ffc(s)=δ(B(Ws))
其中函数
B
B
B 表示 BN 操作。另外需要注意的是,这里也将权值维度减小到
d
d
d,
d
d
d 的值由通道数量除以一个比值决定,该比值为超参数,具体为:
d
=
max
(
C
/
r
,
L
)
d = \max{(C/r, L)}
d=max(C/r,L)
其中
L
L
L 一般取 32。
Select
在这部分,预先设置了几个可学习的参数,这些参数用于将上一步得到的通道信息,分离成与先前进行卷积的卷积核相同个数。参数的个数与卷积核的个数相同。论文中使用了两个卷积核,则该处就预先生成了参数 A A A 与 B B B。 A A A 与 B B B 皆为 C × d C\times d C×d 维矩阵, z z z 为 d d d 维向量。则 A z Az Az 与 B z Bz Bz 为 C C C 维向量,可以乘回 U ~ \widetilde U U 与 U ^ \hat U U^ 。
在乘回之前,需要对
A
z
Az
Az 与
B
z
Bz
Bz 进行 softmax 操作,以选择参数的重要性。该步不仅将通道之间进行了加权,也将
U
~
\widetilde U
U
与
U
^
\hat U
U^ 进行加权。并且与之前一步可以一同进行:
a
c
=
e
A
c
z
e
A
c
z
+
e
B
c
z
,
b
c
=
e
B
c
z
e
A
c
z
+
e
B
c
z
a_c = \frac{e^{A_cz}}{e^{A_cz}+e^{B_cz}}, \ b_c = \frac{e^{B_cz}}{e^{A_cz}+e^{B_cz}}
ac=eAcz+eBczeAcz, bc=eAcz+eBczeBcz
可以看到,当只使用两个卷积核时,也就是只存在参数
A
A
A 与
B
B
B 时,
b
c
=
1
−
a
c
b_c = 1 - a_c
bc=1−ac 。通过上式即可得到
U
~
\widetilde U
U
与
U
^
\hat U
U^ 的通道权值
a
a
a 与
b
b
b ,将其乘回
U
~
\widetilde U
U
与
U
^
\hat U
U^ 并相加后即可得到输出:
V
=
a
⋅
U
~
+
b
⋅
U
^
V = a \cdot \widetilde U + b \cdot \hat U
V=a⋅U
+b⋅U^
Attention-UNet
简介
Attention-UNet 不同于上述两种方法使用通道注意力机制,而是使用空间注意力,原文为三维分割,此处只概述其注意力模块。
具体操作
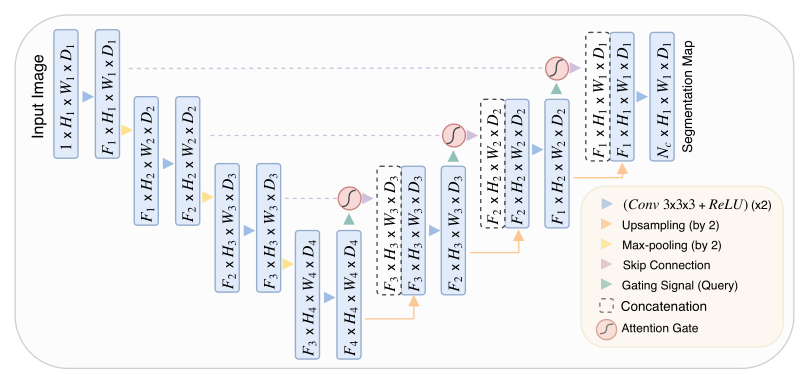
该网络基于 UNet,在跳接部位使用了注意力门(AG)模块。该模块需要两个输入,分别为来自 Encoder 部分的的跳接,与来自 Decoder 部分深一层的输入,具体如上图。
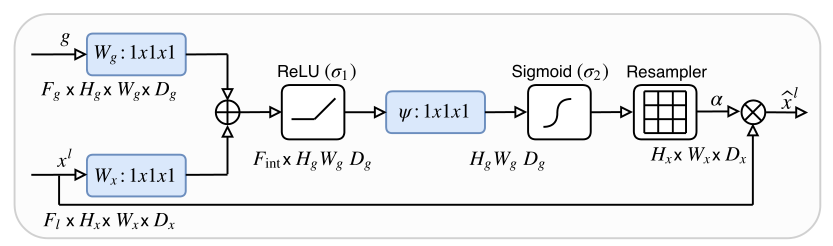
该注意力门模块中
g
g
g 代表的是来自 Decoder 部分输入,
x
l
x^l
xl 代表的是 Encoder 部分的输入。首先
x
x
x 与
g
g
g 都需要经过一次卷积变换,由于
x
x
x 与
g
g
g 的图像尺寸不同,需要将
x
l
x^l
xl 降采样到与
g
g
g 相同的尺寸,然后将他们相加。使用 ReLU 激活函数对结果进行非线性变换后,再进行一个卷积操作:
q
a
t
t
l
=
ψ
(
σ
1
(
W
x
T
x
i
l
+
W
g
T
g
i
+
b
g
)
)
+
b
ψ
q^l_{att} = \psi(\sigma_1(W_x^T x^l_i + W^T_g g_i + b_g))+b_\psi
qattl=ψ(σ1(WxTxil+WgTgi+bg))+bψ
将结果进行 Sigmoid 操作,得到空间权值。但当前的尺寸为
g
g
g 的尺寸,需要再上采样到
x
l
x^l
xl 的尺寸,最后将结果乘回
x
l
x^l
xl 完成输出:
a
i
l
=
σ
2
(
q
a
t
t
l
)
x
^
l
=
R
e
s
a
m
p
l
e
(
α
)
⋅
x
l
a_i^l = \sigma_2(q^l_{att})\\ \hat x^l = Resample(\alpha) \cdot x^l
ail=σ2(qattl)x^l=Resample(α)⋅xl
CBAM
简介
该论文提出了一个新的注意力模块 CBAM,其中通过串联的方式融合了通道注意力与空间注意力,并通过实验证实了该连接结构最优。
具体操作
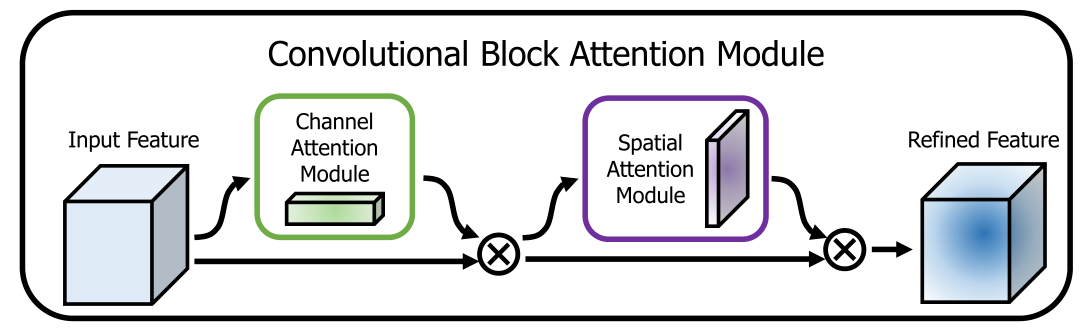
该论文将输入依次通过通道注意力与空间注意力,通过公式可以概括为:
F
′
=
M
c
(
F
)
⋅
F
F
′
′
=
M
s
(
F
)
⋅
F
′
F' = M_c (F) \cdot F\\ F'' = M_s(F) \cdot F'
F′=Mc(F)⋅FF′′=Ms(F)⋅F′

其中通道注意力的结构如上,其实跟 SENet 差不多,将 GAP 变为并行的 GAP 和 GMP,然后将两部分结果经过 同一个 MLP 单元,得到两组通道权值,再将它们相加后进行 sigmoid 并乘回,即可得到通道注意力 Map。因为和之前的区别不大就不概述了,公式如下:
M
c
(
F
)
=
σ
(
M
L
P
(
A
v
g
P
o
o
l
(
F
)
)
+
M
L
P
(
M
a
x
P
o
o
l
(
F
)
)
)
=
σ
(
W
1
(
W
0
(
F
a
v
g
c
)
)
+
W
1
(
W
0
(
F
m
a
x
c
)
)
)
M_c(F) = \sigma (MLP(AvgPool(F)) + MLP(MaxPool(F))) \\ =\sigma(W_1 (W_0(F_{avg}^c))+ W_1 (W_0(F^c_{max})))
Mc(F)=σ(MLP(AvgPool(F))+MLP(MaxPool(F)))=σ(W1(W0(Favgc))+W1(W0(Fmaxc)))
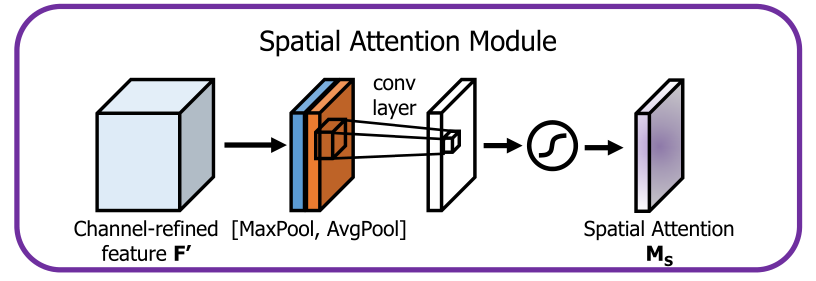
通道注意力部分,使用通道维度的 GAP 和 GMP 变为两个图像尺寸的参数平面,使用 concat 操作连接后一同放入一个卷积操作,文中此处的卷积核尺寸为
7
×
7
7 \times 7
7×7,输出的通道数为1。最后再使用 sigmoid 激活函数即可得到空间注意力 Map,公式如下:
M
s
(
F
)
=
σ
(
f
7
×
7
(
[
A
v
g
P
o
o
l
(
F
)
;
M
a
x
P
o
o
l
(
F
)
]
)
)
=
σ
(
f
7
×
7
(
[
F
a
v
g
s
;
F
m
a
x
s
]
)
)
M_s(F) = \sigma(f^{7\times7}([AvgPool(F); MaxPool(F)]))\\ = \sigma(f^{7\times 7}([F^s_{avg}; F^s_{max}]))
Ms(F)=σ(f7×7([AvgPool(F);MaxPool(F)]))=σ(f7×7([Favgs;Fmaxs]))
BAM
简介
该网络与 CBAM 网络类似,都是结合了通道注意力与空间注意力,两篇论文发布在相同时期。不同的是,CBAM 中使用了将通道注意力和空间注意力串联的方式,而在 BAM 中则使用了并联后直接相加的方式。
具体做法
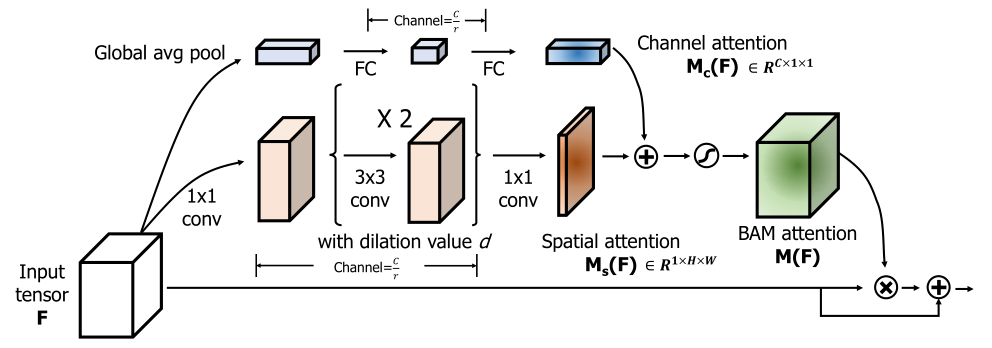
和 CBAM 一样有个精炼公式:
F
′
=
F
+
F
⋅
M
(
F
)
M
(
F
)
=
σ
(
M
c
(
F
)
+
M
s
(
F
)
)
F' = F + F\cdot M(F)\\ M(F) = \sigma (M_c(F) + M_s(F))
F′=F+F⋅M(F)M(F)=σ(Mc(F)+Ms(F))
首先看通道注意力部分,依旧是首先使用 GAP 获取通道权值,使用全连接层进行非线性变换,中间将通道缩减至
C
r
\frac{C}{r}
rC 再变换回来,在最后做一个 BN:
M
c
(
F
)
=
B
N
(
M
L
P
(
A
v
g
P
o
o
l
(
F
)
)
)
=
B
N
(
W
1
(
W
0
A
v
g
P
o
o
l
(
F
)
+
b
0
)
+
b
1
)
M_c(F) = BN(MLP(AvgPool(F))) \\ =BN(W_1 (W_0 AvgPool(F) + b_0) + b_1)
Mc(F)=BN(MLP(AvgPool(F)))=BN(W1(W0AvgPool(F)+b0)+b1)
然后看空间注意力部分,首先使用尺寸为
1
×
1
1\times 1
1×1 的卷积核,将通道缩减至
C
r
\frac{C}{r}
rC ,再经过两次
3
×
3
3\times 3
3×3 的卷积进行非线性变换,最后再使用
1
×
1
1\times 1
1×1 将通道缩减为 1 后经过 BN 得到空间注意力 Map,这公式真的脑溢血:
M
s
(
F
)
=
B
N
(
f
3
1
×
1
(
f
2
3
×
3
(
f
1
3
×
3
(
f
0
1
×
1
(
F
)
)
)
)
)
M_s(F) = BN(f_3^{1\times1}\ (f_2^{3\times 3} \ (f_1^{3\times 3}\ (f_0^{1\times 1}\ (F)))))
Ms(F)=BN(f31×1 (f23×3 (f13×3 (f01×1 (F)))))
得到空间注意力Map 和通道注意力Map 后,需要将他们融合使用,改论文中将他们直接相加,得到一个
C
×
H
×
W
C\times H \times W
C×H×W 的张量,然后经过 Sigmoid 激活函数,得到最终的 BAM注意力 Map。将其乘回输入
F
F
F 即得到最终结果
F
′
F'
F′。公式同之前的精炼公式。
ECA-Net
github : https://github.com/BangguWu/ECANet
简介
该网络为 SENet 的精简版,使用自适应卷积核尺寸的卷积操作替代了原来的 MLP 操作,减少参数的前提下还能提高模型性能(?)。
具体做法
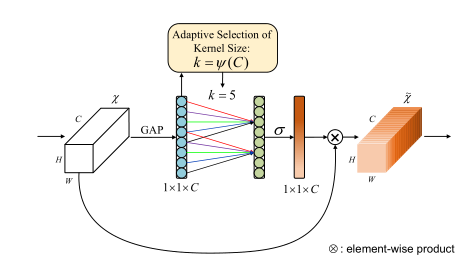
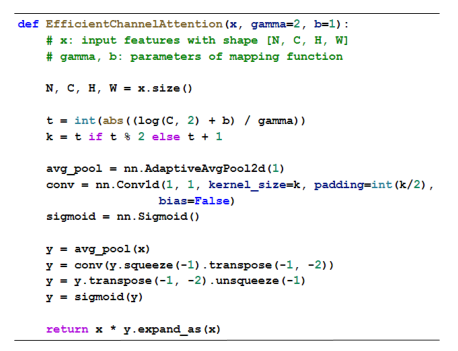
和 SENet 基本没啥区别,就是把 MLP 换成卷积,其中卷积核尺寸的计算公式为:
k
=
ψ
(
C
)
=
∣
log
2
(
C
)
γ
+
b
γ
∣
o
d
d
k = \psi (C) = \left|\frac{\log_2(C)}{\gamma} + \frac{b}{\gamma}\right|_{odd}
k=ψ(C)=∣∣∣∣γlog2(C)+γb∣∣∣∣odd
这个模型的设计思路为,作者认为一个通道不需要和其他所有通道都建立注意力,只需要与邻域的通道进行联系即可。
论文中还有代码…
Coordinate Attention
github : https://github.com/Andrew-Qibin/CoordAttention
简介
SENet 可以建立通道之间地相关性,但是缺乏位置上的信息。作者将通道注意分解为两个一维的特征编码过程,即将对于整张输入图像的全局池化变为仅在输入图像行轴或列轴上的池化。通过这种方法,可以沿着一个空间方向捕获远程依赖关系,同时沿着另一个空间方向保留精确的位置信息。
具体做法
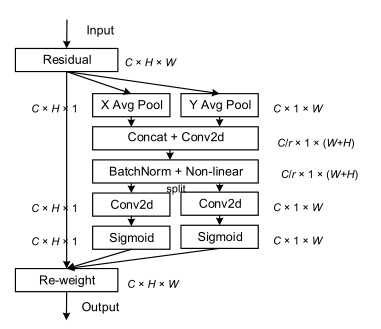
分别使用 X 方向的平均池化 和 Y 方向的平均池化得到两组特征:
z
c
h
=
1
W
∑
i
=
1
W
x
c
(
h
,
i
)
z
c
w
=
1
H
∑
j
=
1
H
x
c
(
j
,
w
)
z_c^h = \frac{1}{W}\sum_{i=1}^W x_c(h, i)\\ z_c^w = \frac{1}{H}\sum_{j=1}^H x_c(j, w)\\
zch=W1i=1∑Wxc(h,i)zcw=H1j=1∑Hxc(j,w)
得到两组特征后对其结构进行变换,统一为
C
×
1
×
(
W
o
r
H
)
C\times 1\times (W or H)
C×1×(WorH) ,再进行 concat 操作,得到
C
×
1
×
(
W
+
H
)
C \times 1 \times (W+H)
C×1×(W+H) 的张量。使用
1
×
1
1 \times 1
1×1 的卷积,将其变换为
C
/
r
×
1
×
(
W
+
H
)
C/r \times 1 \times (W+H)
C/r×1×(W+H) 然后 BN 和 激活函数。再将其按
W
W
W 和
H
H
H 分离,得到
f
h
f^h
fh 和
f
w
f^w
fw 对其分别使用两个
1
×
1
1 \times 1
1×1 的卷积
F
h
F^h
Fh 与
F
w
F^w
Fw ,把通道数变回
C
C
C,并使用 Sigmoid 激活函数得到两个方向上的权值:
g h = σ ( F h ( f h ) ) g w = σ ( F w ( f w ) ) g^h = \sigma(F_h(f^h))\\ g^w = \sigma(F_w(f^w)) gh=σ(Fh(fh))gw=σ(Fw(fw))
然后将其乘回输入 x x x 即可:
y c ( i , j ) = x c ( i , j ) × g c h ( i ) × g c w ( j ) y_c(i,j) = x_c(i,j) \times g^h_c(i) \times g_c^w(j) yc(i,j)=xc(i,j)×gch(i)×gcw(j)
总结
以上为最近阅读的关于视觉中注意力机制的论文,测试得 SENet 和 Attention-UNet以及 CBAM 都有涨点,ECA-Net似乎评价不高,Coordinate Attention 还未使用,评价说涨点明显,等待测试。














 1840
1840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









