









 本文详细介绍了YOLOv5中的损失函数,包括分类损失、定位损失和置信度损失。针对不同的任务需求,YOLOv5采用了多种损失计算方式,如二元交叉熵损失、IoU损失等。
本文详细介绍了YOLOv5中的损失函数,包括分类损失、定位损失和置信度损失。针对不同的任务需求,YOLOv5采用了多种损失计算方式,如二元交叉熵损失、IoU损失等。
YOLOv5代码阅读笔记 - 损失函数
yolov5 中包含了以下三种损失函数:
- classification loss: 分类损失
- localization loss: 定位损失
- confidence loss: 置信度损失
总体的损失即为以上三者的加权相加,通过改变权值可以调整对三者损失的关注度。
分类预测
通常对于分类任务,输出的标签是互斥的。如将某一个生物可能为人、狗或是猫,且该生物只可能是三种类别中的一种。此时将会用到 softmax 函数将三者的预测值转换为总和为 1 的概率值,并分类为概率最高的那一类。
y i = Softmax ( x i ) = e x i ∑ n = 1 N e x n L c l a s s = − ∑ n = 1 N y n ∗ log ( y n ) y_i =\operatorname{Softmax}(x_i) = \frac{e^{x_i}}{\sum_{n=1}^N e^{x_n}} \\ L_{class} = -\sum_{n=1}^N y^*_n\log(y_n) yi=Softmax(xi)=∑n=1NexnexiLclass=−n=1∑Nyn∗log(yn)
yolov3 之后考虑到一个目标可能同时属于多个类别,如同时识别一个人的性别和姿态,则会输出如“男性”、“行走”两个结果。此时概率之和可能将大于 1。故在 yolov3 之后则对每一个类别预测的结果使用二元交叉熵损失:
y
i
=
Sigmoid
(
x
i
)
=
1
1
+
e
−
x
i
L
c
l
a
s
s
=
−
∑
n
=
1
N
y
i
∗
log
(
y
i
)
+
(
1
−
y
i
∗
)
log
(
1
−
y
i
)
y_i = \operatorname{Sigmoid}(x_i) = \frac{1}{1+e^{-x_i}} \\ L_{class} = -\sum_{n=1}^Ny_i^*\log(y_i)+(1-y^*_i)\log(1-y_i)
yi=Sigmoid(xi)=1+e−xi1Lclass=−n=1∑Nyi∗log(yi)+(1−yi∗)log(1−yi)
以上公式中
N
N
N 表示类别总个数,
x
i
x_i
xi 为当前类别预测值,
y
i
y_i
yi 为经过激活函数后得到的当前类别的概率,
y
i
∗
y_i^*
yi∗ 则为当前类别的真实值 (0 或 1),
L
c
l
a
s
s
L_{class}
Lclass 为分类损失。
边界框预测
边界框预测是目标检测中最主要的任务之一,目标检测中想要框出检测到的目标,就需要通过对边界框所在位置数据的预测。
在之前的版本中,使用的是平方损失,即:
L l o c a l = ( x − x ∗ ) 2 + ( y − y ∗ ) 2 + ( w − w ∗ ) 2 + ( h − h ∗ ) 2 L_{local} =(x−x^*)^2+(y−y^*) ^2+(w−w^*)^2+(h−h^*)^2 Llocal=(x−x∗)2+(y−y∗)2+(w−w∗)2+(h−h∗)2
其中 x , y , w , h x, y, w, h x,y,w,h 分别代表预测框的左上角坐标与框的长宽。
但该方法存在一定问题,由于边界框预测需要着重于该框与真实框的重叠区域面积,且重叠区域的面积与两者并集区域的面积之比越大越好,但光使用平方损失无法很好地衡量这一点。为了解决这一问题,之后衍生出多个基于 IoU 的损失计算方式。
- MSE
- IoU loss
- GIoU loss
- DIoU loss
- CIoU loss
IoU
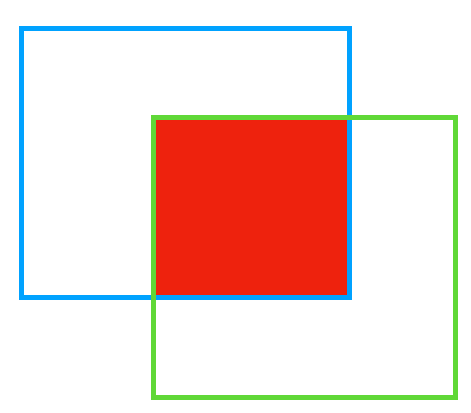
交并比 (IoU) 是目标检测中的一个重要概念,即为目标框与真实框交集与并集的比值,如上图中图上红色部分为蓝绿两个方块的交集,该部分与蓝绿两个方块的并集面积的比值就是交并比。
IoU ( B 1 , B 2 ) = ∣ B 1 ∩ B 2 ∣ ∣ B 1 ∪ B 2 ∣ \operatorname{IoU}(B_1, B_2) = \frac{|B_1\cap B_2|}{|B_1\cup B_2|} IoU(B1,B2)=∣B1∪B2∣∣B1∩B2∣
可见当两个框完全重叠时,其交并比为 1,完全不重叠时为 0。那么损失即可定义为
L I o U = 1 − IoU ( B , B g t ) L_{IoU} = 1 - \operatorname{IoU}(B, B_{gt}) LIoU=1−IoU(B,Bgt)
但该方式还存在两个问题:
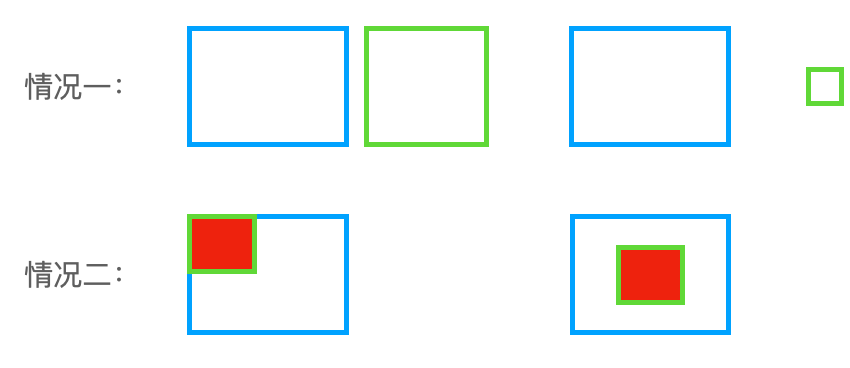
- 当真实框和预测框完全不重叠时,因为其损失都为 1,则无法反映预测框离真实框的远近
- 当真实框包含预测框,且真实框与预测框的大小固定时,其 IoU 很定为预测框与真实框面积的比值,则无论预测框在真实框中的哪个位置,损失都不变。
GIoU
为了解决 IoU 的第一个问题,GIoU 出现了。GIoU 在 IoU 的基础上还增加了一个框,即为能够同时框住真实框与预测框的最小的框,如下图所示:
 橙色部分 (包括蓝色和绿色) 即为最小方框 C。C 的面积减去预测框与真实框的面积,再比上 C 的面积,即可反映出真实框与预测框距离。损失计算公式如下:
橙色部分 (包括蓝色和绿色) 即为最小方框 C。C 的面积减去预测框与真实框的面积,再比上 C 的面积,即可反映出真实框与预测框距离。损失计算公式如下:
x 1 c = min ( x 1 B , x 1 B g t ) , x 2 c = max ( x 2 B , x 2 B g t ) y 1 c = min ( y 1 B , y 1 B g t ) , y 2 c = max ( y 2 B , y 2 B g t ) C = ( x 2 c − x 1 c ) × ( y 2 c − y 1 c ) x^c_1 = \min(x^B_1, x^{B_{gt}}_1),\quad x^c_2 = \max(x^B_2, x^{B_{gt}}_2)\\ y^c_1 = \min(y^B_1, y^{B_{gt}}_1), \quad y^c_2 = \max(y^B_2, y^{B_{gt}}_2)\\[0.5em] C = (x^c_2 - x^c_1) \times (y^c_2 - y^c_1) x1c=min(x1B,x1Bgt),x2c=max(x2B,x2Bgt)y1c=min(y1B,y1Bgt),y2c=max(y2B,y2Bgt)C=(x2c−x1c)×(y2c−y1c)
GIoU ( B , B g t ) = IoU ( B , B g t ) − ∣ C − ( B ∪ B g t ) ∣ ∣ C ∣ L G I o U ( B , B g t ) = 1 − GIoU ( B , B g t ) = 1 − IoU ( B , B g t ) + ∣ C − ( B ∪ B g t ) ∣ ∣ C ∣ \operatorname{GIoU}(B, B_{gt}) = \operatorname{IoU}(B, B_{gt}) - \frac{|C - (B \cup B_{gt})| }{|C|}\\ L_{GIoU}(B, B_{gt}) = 1-\operatorname{GIoU}(B, B_{gt}) = 1 - \operatorname{IoU}(B, B_{gt}) + \frac{|C - (B \cup B_{gt})| }{|C|} GIoU(B,Bgt)=IoU(B,Bgt)−∣C∣∣C−(B∪Bgt)∣LGIoU(B,Bgt)=1−GIoU(B,Bgt)=1−IoU(B,Bgt)+∣C∣∣C−(B∪Bgt)∣
GIoU 中,真实框与预测框距离越远时, C 的值也越大,C 减去预测框与真实框面积的值也越大,最后趋近于 1。那么真实框与预测框当越远时,损失也越接近 2。但是 GIoU 虽然解决了真实框与预测框完全分离时 IoU 无法衡量两者距离的问题,但是依旧无法解决问题二。
DIoU
为了解决上述问题,2020年又衍生出了 DIoU。与 GIoU 不同,DIoU 中使用真实框和预测框中心点距离的平方与两者最小框 C 对角线长度平方的比值作为衡量标准的一部分。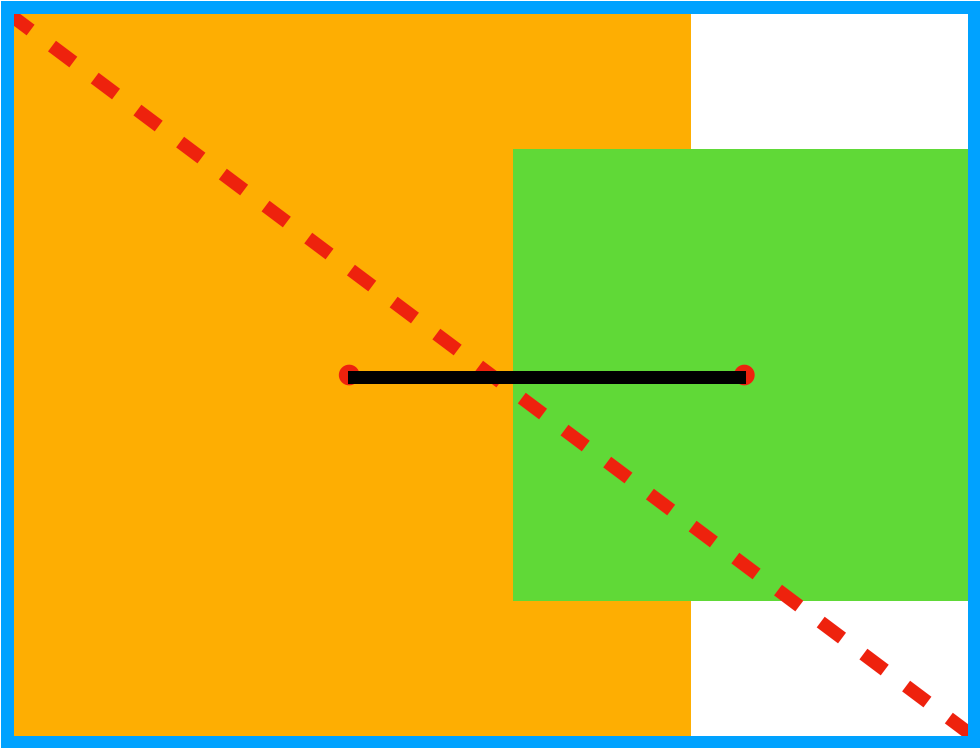
黄色和绿色的方块分别为真实框和预测框,其中红色的点为两者的重点,中间的黑色线段为真实框和预测框中点的连线。蓝色的框为最小框 C,红色虚线为 C 的对角线。DIoU 的计算方法以及损失如下:
x 1 p = x 2 B − x 1 B , y 1 p = y 2 B − y 1 B x 2 p = x 2 B g t − x 1 B g t , y 2 p = y B g t − y 1 B g t ρ 2 ( B , B g t ) = ( x 1 p − x 2 p ) 2 + ( y 1 p − y 2 p ) 2 x^p_1 = x^B_2-x^B_1,\quad y^p_1 = y^B_2- y^B_1\\ x^p_2 = x^{B_{gt}}_2-x^{B_{gt}}_1,\quad y^p_2 = y^{B_{gt}}- y^{B_{gt}}_1\\ \rho^2(B, B_{gt}) = (x^p_1 - x^p_2)^2 + (y^p_1 - y^p_2)^2\\ x1p=x2B−x1B,y1p=y2B−y1Bx2p=x2Bgt−x1Bgt,y2p=yBgt−y1Bgtρ2(B,Bgt)=(x1p−x2p)2+(y1p−y2p)2
x 1 c = min ( x 1 B , x 1 B g t ) , x 2 c = max ( x 2 B , x 2 B g t ) y 1 c = min ( y 1 B , y 1 B g t ) , y 2 c = max ( y 2 B , y 2 B g t ) c 2 = ( x 2 c − x 1 c ) 2 + ( y 2 c − y 1 c ) 2 DIoU ( B , B g t ) = IoU ( B , B g t ) − ρ 2 ( B , B g t ) c 2 L D I o U ( B , B g t ) = 1 − DIoU ( B , B g t ) = 1 − IoU ( B , B g t ) + ρ 2 ( B , B g t ) c 2 x^c_1 = \min(x^B_1, x^{B_{gt}}_1),\quad x^c_2 = \max(x^B_2, x^{B_{gt}}_2)\\ y^c_1 = \min(y^B_1, y^{B_{gt}}_1), \quad y^c_2 = \max(y^B_2, y^{B_{gt}}_2)\\[0.5em] c^2 = (x^c_2 - x^c_1)^2 +(y^c_2 - y^c_1)^2\\[2em] \operatorname{DIoU}(B, B_{gt}) = \operatorname{IoU}(B, B_{gt}) - \frac{\rho^2(B, B_{gt})}{c^2} \\ L_{DIoU}(B, B_{gt}) = 1 - \operatorname{DIoU}(B, B_{gt}) = 1 - \operatorname{IoU}(B, B_{gt}) + \frac{\rho^2(B, B_{gt})}{c^2} x1c=min(x1B,x1Bgt),x2c=max(x2B,x2Bgt)y1c=min(y1B,y1Bgt),y2c=max(y2B,y2Bgt)c2=(x2c−x1c)2+(y2c−y1c)2DIoU(B,Bgt)=IoU(B,Bgt)−c2ρ2(B,Bgt)LDIoU(B,Bgt)=1−DIoU(B,Bgt)=1−IoU(B,Bgt)+c2ρ2(B,Bgt)
DIoU 的好处即为解决了最初的第二个问题,使得预测框的中心点能够向真实框的中心点靠近。同时 DIoU 相比 GIoU 能够更快地收敛。
CIoU
CIoU 为 DIoU 的再次升级版,其中考虑到了预测框与真实框的长宽比例问题,再其中新添加了两个参数,即:
CIoU ( B , B g t ) = IoU ( B , B g t ) − ρ 2 ( B , B g t ) c 2 − α v v = 4 π ( arctan w g t h g t − arctan w h ) 2 α = v 1 − IoU ( B , B g t ) + v \operatorname{CIoU}(B, B_{gt}) = \operatorname{IoU}(B, B_{gt}) - \frac{\rho^2(B, B_{gt})}{c^2} - \alpha v \\ v = \frac{4}{\pi} \left( \arctan\frac{w^{gt}}{h^{gt}} - \arctan\frac{w}{h} \right)^2\\[1em] \alpha= \frac{v}{1-\operatorname{IoU}(B, B_{gt})+v} CIoU(B,Bgt)=IoU(B,Bgt)−c2ρ2(B,Bgt)−αvv=π4(arctanhgtwgt−arctanhw)2α=1−IoU(B,Bgt)+vv
其中 v v v 为预测框和真实框长宽比例差值的归一化, ( arctan w g t h g t − arctan w h ) 2 \left( \arctan\frac{w^{gt}}{h^{gt}} - \arctan\frac{w}{h} \right)^2 (arctanhgtwgt−arctanhw)2 部分的值在 0 到 π/4 之间,乘以 4/π 后就可以转化为到 0 到 1 之间。而 α \alpha α 为权衡长宽比例造成的损失和 IoU 部分造成的损失的平衡因子。
CIoU 通过更多的维度来考虑预测框与真实框的差异,效果更好,所以一般使用 CIoU。
置信度预测
tobj[b, a, gj, gi] = (1.0 - self.gr) + self.gr * score_iou
就一行代码,前半部分作为有无检测目标的损失部分,后半部分为当检测结果为有目标的情况下,检测框准确度的损失。
1.0 - self.gr 计算了置信度的损失,让 gt 中有目标的区域在优化中置信度更高。self.gr * score_iou 则包含 iou 的损失,检测框与真实框差距越大,score_iou 越大,后半部分的 loss 也越大。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









