






搭建Xinference的AI环境
搭建xinference
#新建虚拟环境xinference
conda create -n xinference python=3.10
conda activate xinferenceconda create -n xinference python=3.10
#安装xinference:
pip install "xinference[sglang]" -i https://pypi.tuna.tsinghua.edu.cn/simple/这一步要安装的包比较多,需要多要等一会,等待时间看服务器的网速
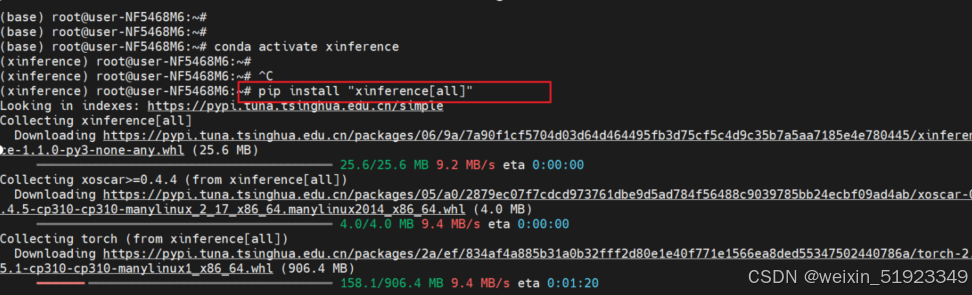
还需要下载这个whl包,然后传服务器上去手动安装(清华源没有这个包,而且,要翻墙,所以只能手动下载,然后传上去)
https://flashinfer.ai/whl/cu124/torch2.4/flashinfer/
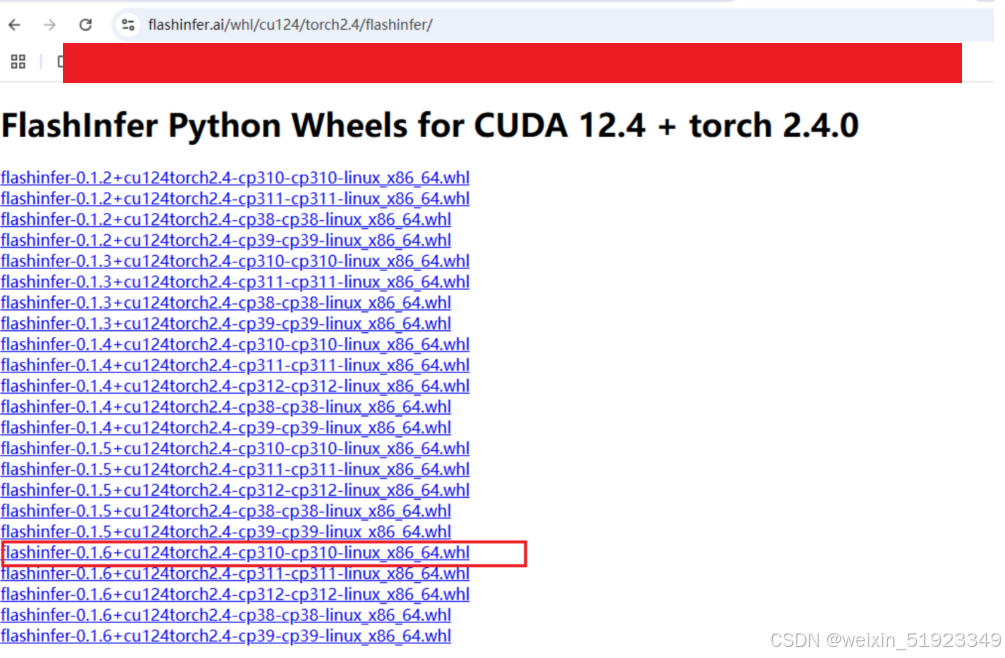
#安装
pip install ./flashinfer-0.1.6+cu124torch2.4-cp310-cp310-linux_x86_64.whl此外还有几个推理的时候常用到的库,建议一起装了
pip install torchao
pip install sentence-transformers
pip install autoawq
pip install -U bitsandbytes
启动xinference
#激活环境
conda activate xinference
#启动界面,host和port分别输入IP和端口:
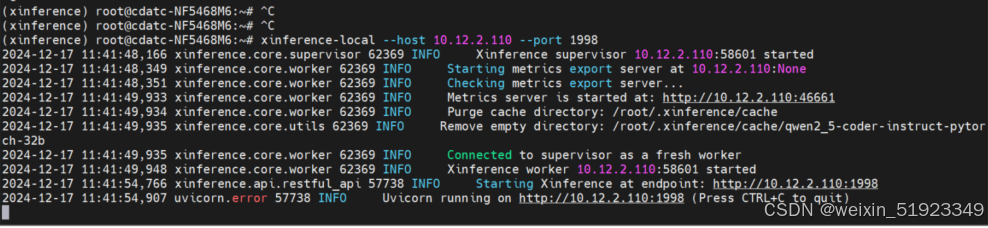
xinference-local --host 10.12.2.110 --port 1998
回显如下,就表示成功:
浏览器输入地址:10.12.2.110:1998可以去下载和启动模型:
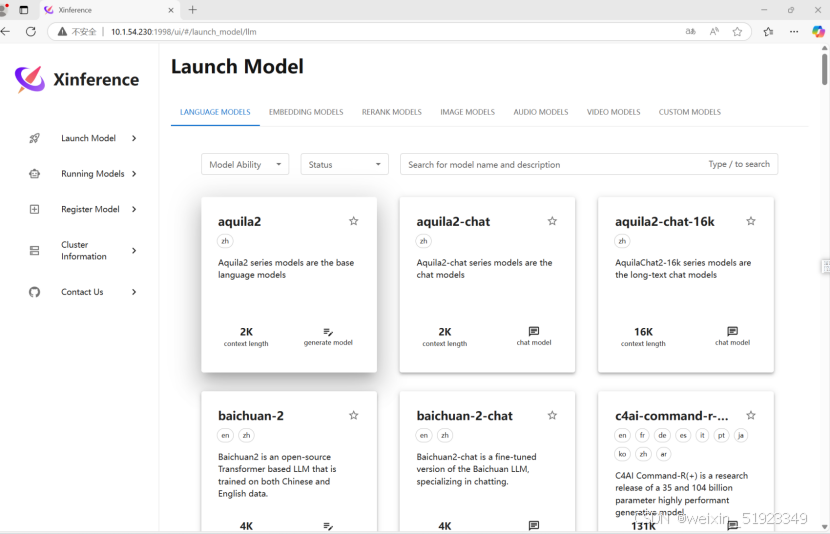
举个例子:
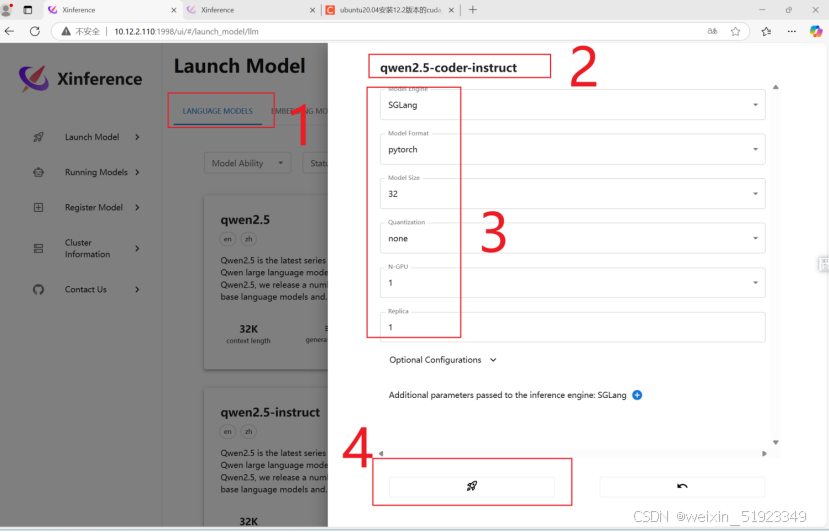
按照上面的方式,下载一个embedding模型,一个LLM模型。
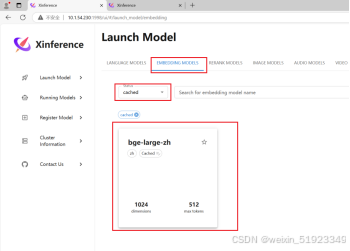
如下,点击cached查看已经下载好的:
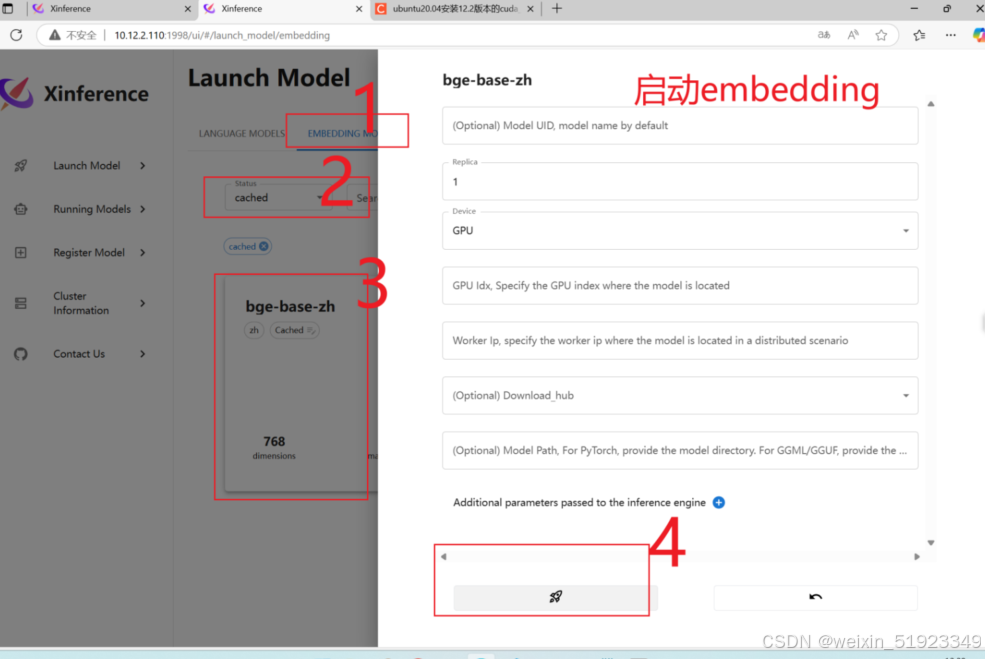
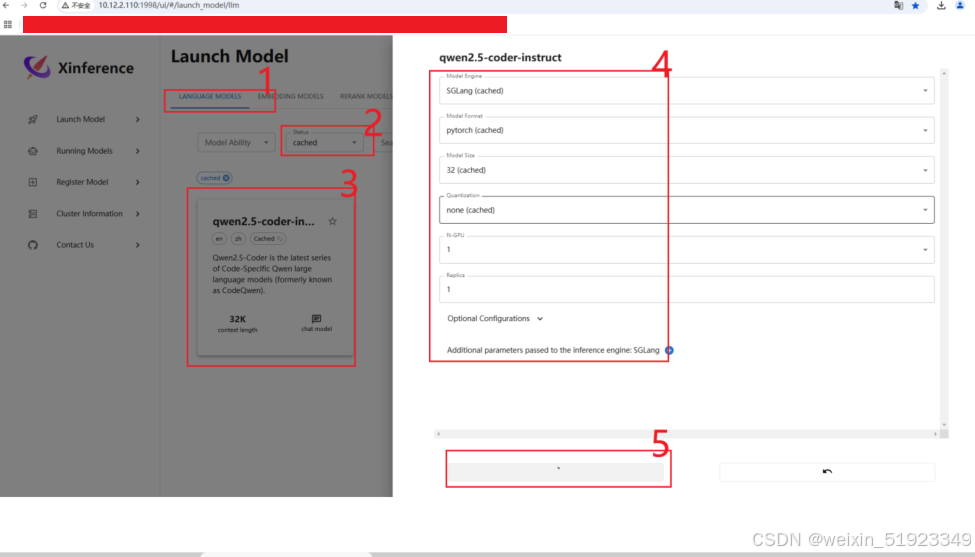
启动模型
按照如下方式启动embedding和LLM模型
搭建chatchat
#新建python3.10的虚拟环境
conda create -n chatchat python=3.10
conda activate chatchat#安装langchainchatchat
pip install langchain-chatchat -U#安装xinference引擎的langchainchatchat
pip install "langchain-chatchat[xinference]" -U#修改一个库的版本(必须修改,否则有BUG):
pip install httpx==0.27.2
启动chatchat
#激活环境:
conda activate chatchat
#创建工作目录/home/llm/chatchat_data
mkdir -p /home/llm/chatchat_data
export CHATCHAT_ROOT=/home/llm/chatchat_data
#初始化(只需要执行一次):
chatchat init回显如下则成功:
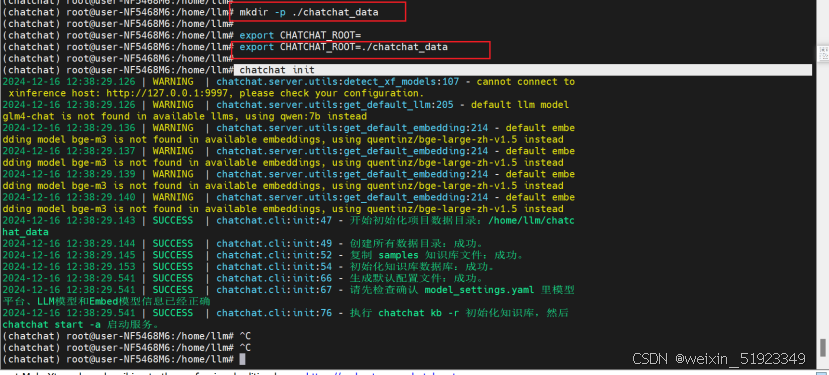
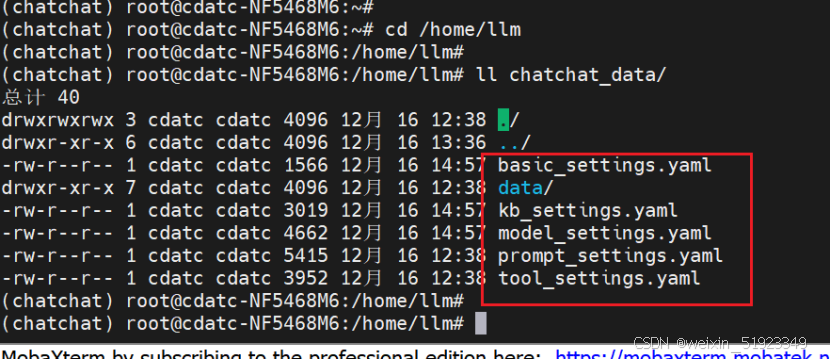
#启动完成以后,工作目录/home/llm/chatchat_data中就生成了如下的配置文件
ll chatchat_data/
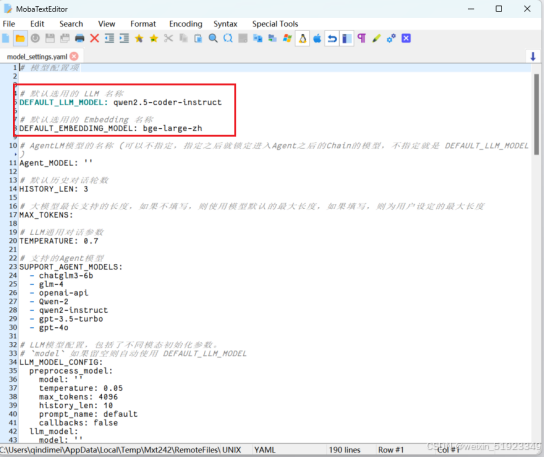
修改里面的配置文件,修改如下。
修改为自己使用的LLM和embedding的名字
修改chatchat的前端和API的启动IP和端口
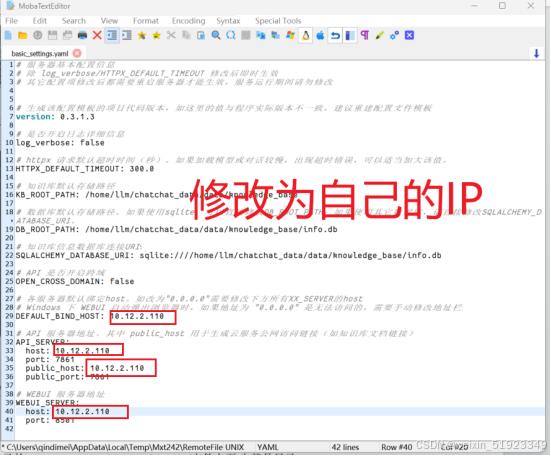
这个修改为xinference的启动IP和端口:
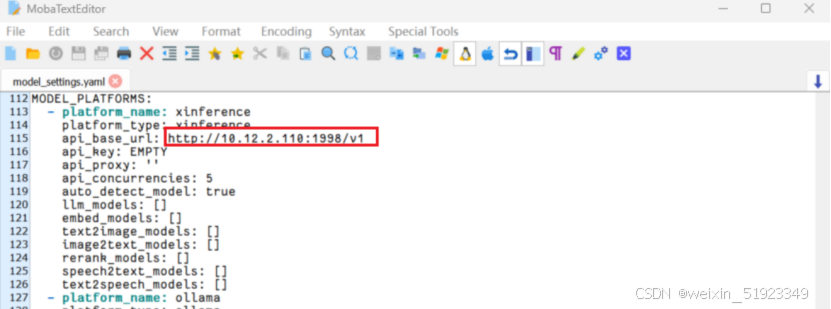
在工作目录的knowledge_base/samples/content/文件夹下,也就是目录/home/llm/chatchat_data/data/nowledge_base/samples/content/下的文件夹就是知识库内容存放的地方,
如下,把文档传入文件夹下就可以了:
#初始化知识库(依赖embedding)(第一次很慢,是正常的。因为要下载nltk_data,第一次以后就会很快)
chatchat kb -r
#启动chatchat
chatchat start -a
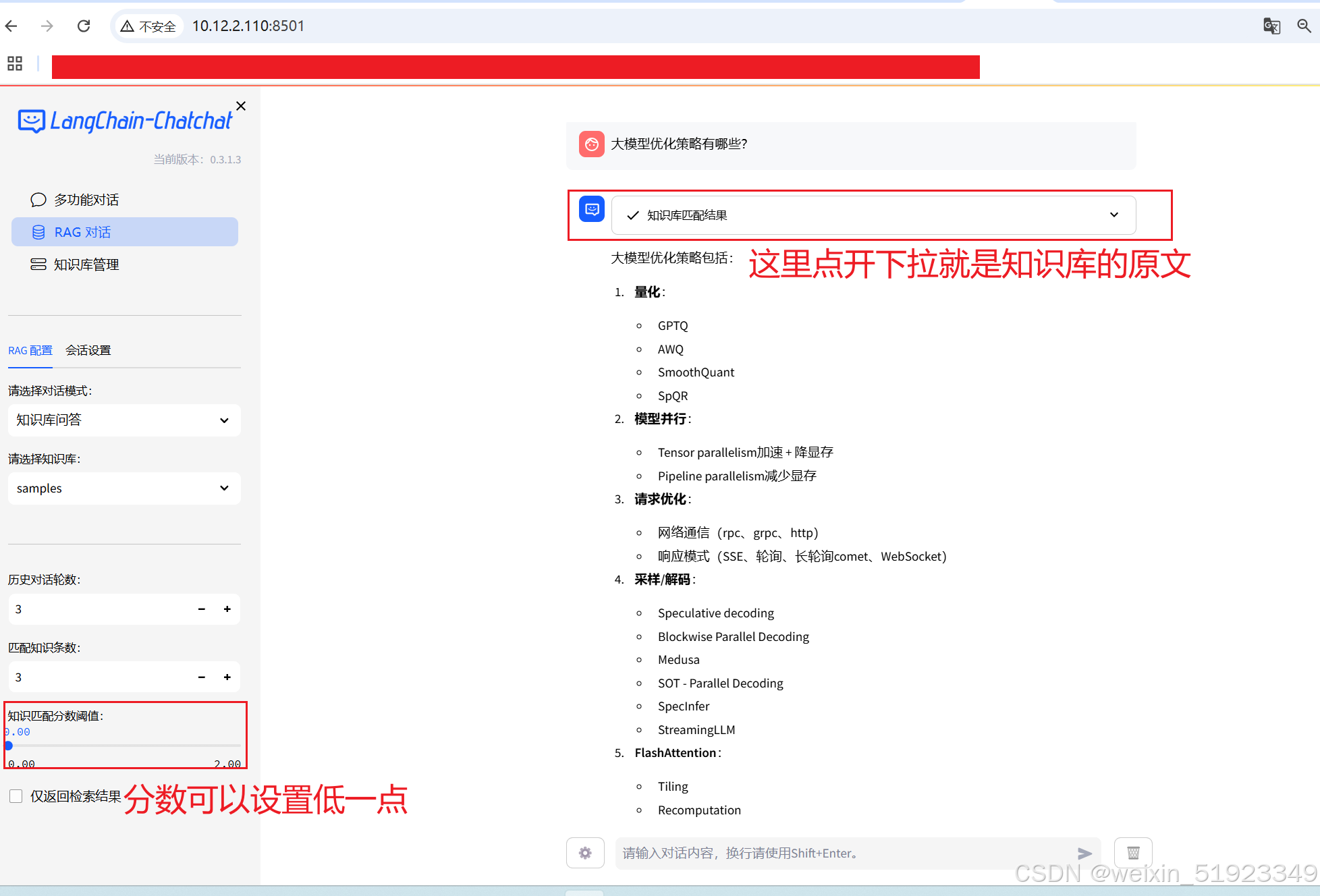
结果展示:
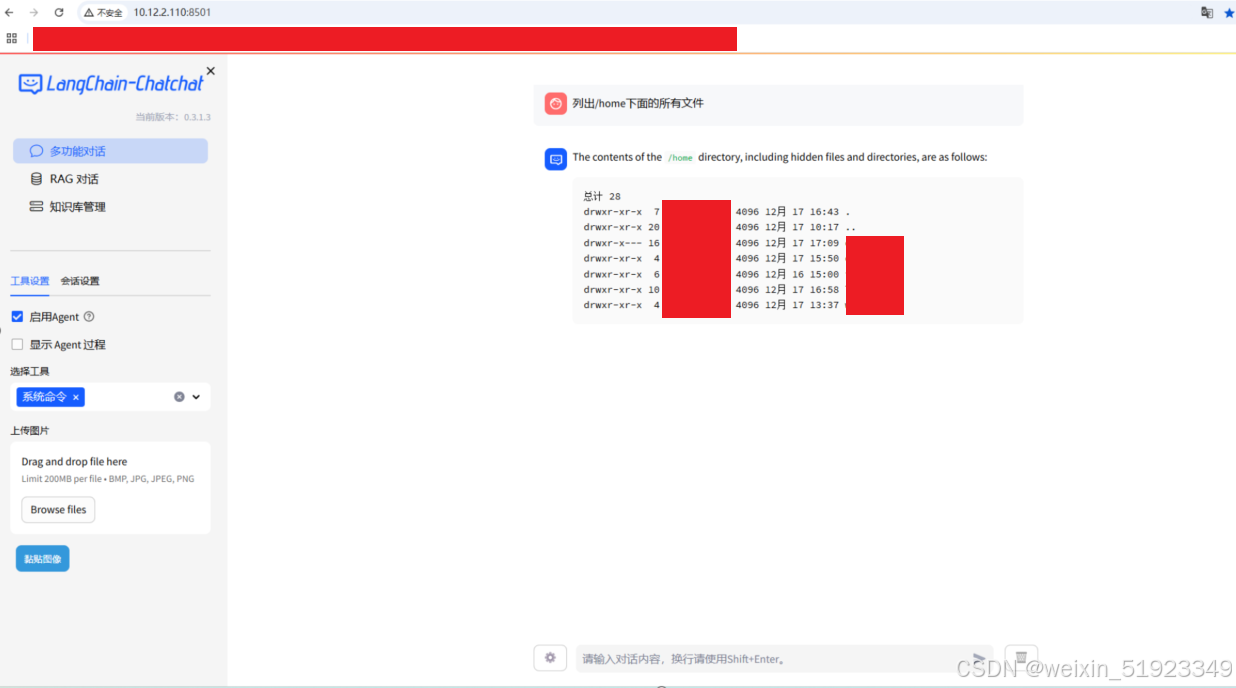
浏览器访问刚才配置文件里面自己写的里面的前端IP+端口就,就可以交互了,我的是http://10.12.2.110:8501
这个有很多功能rag,系统命令,数据库交互,可以多试试

















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









