








利用pandas 读取pdf 中的指定表格文件

-
实例pdf文件中的表格
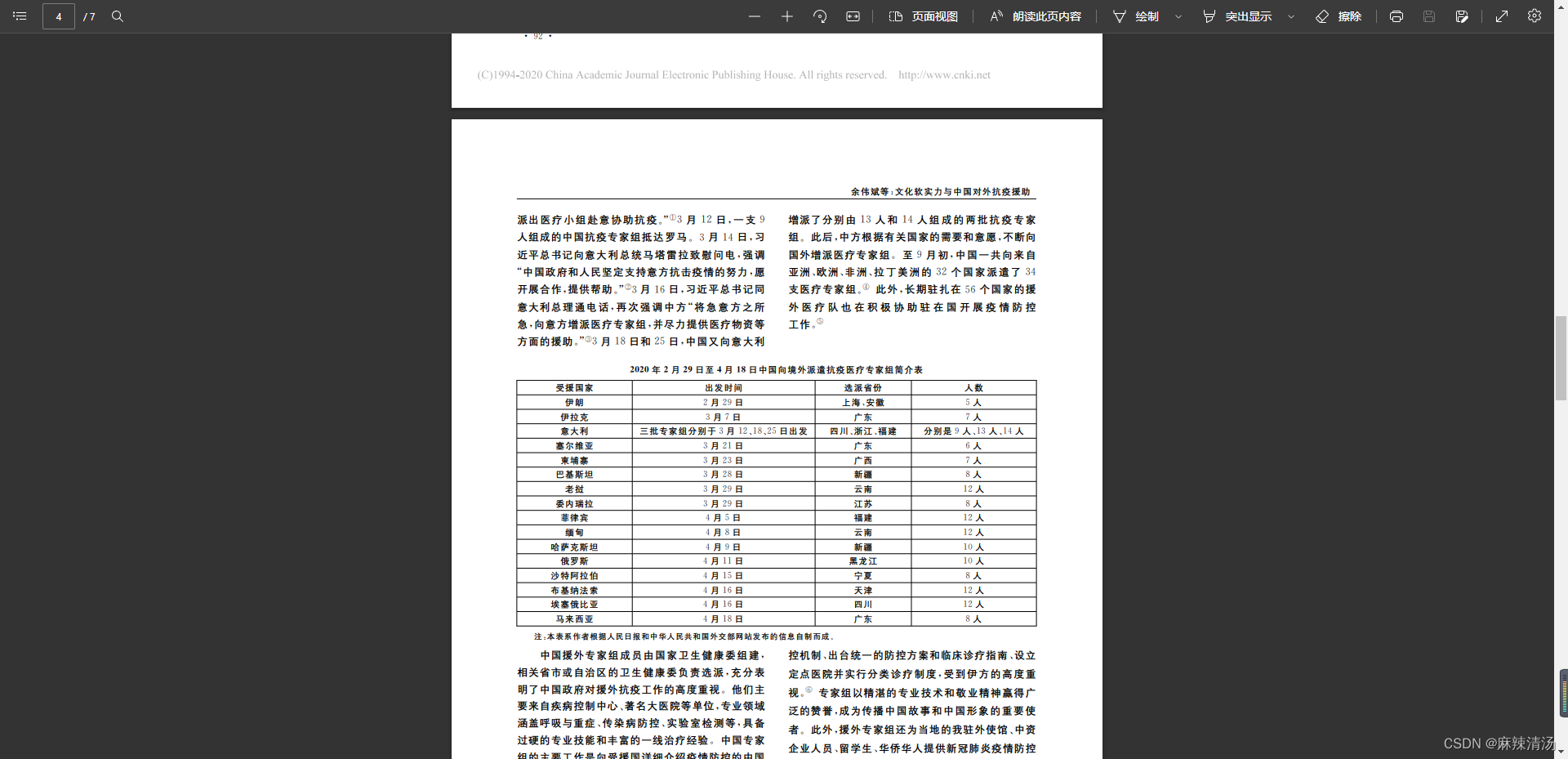
-
了解表格所在pdf具体页数(第四页)
-
加载所需要的库
pip install pdfplumber
pip install pandas
import pdfplumber
import pandas as pd
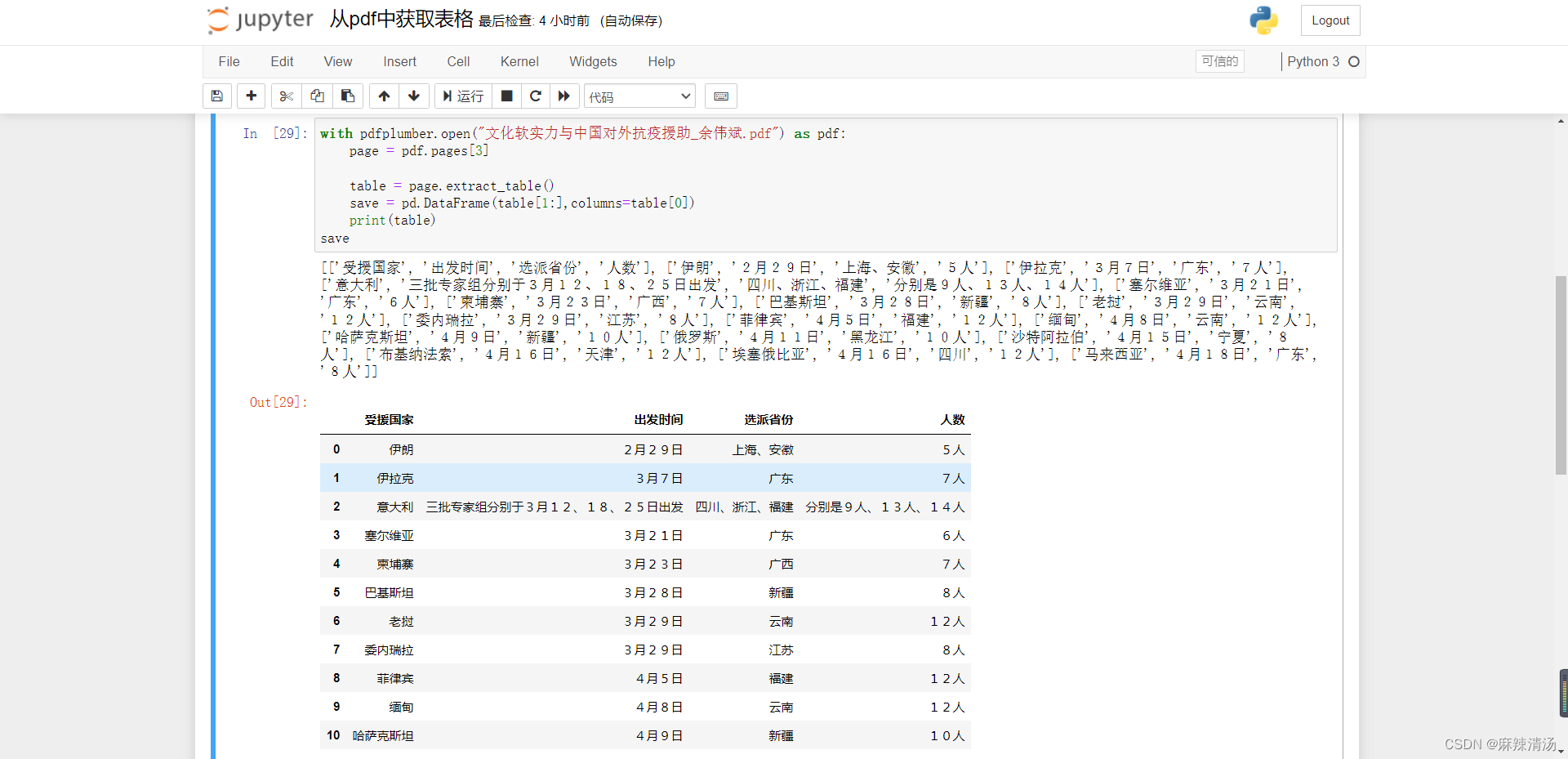
with pdfplumber.open("文化软实力与中国对外抗疫援助_余伟斌.pdf") as pdf:
page = pdf.pages[3] # 按照列表的规则,第四页
table = page.extract_table() #表格以列表的形式取出
save = pd.DataFrame(table[1:],columns=table[0])
print(table)
save
#得到的save为DateFrame类型
save.to_excel('pdf表格文件.xlsx')#保存在跟目录中

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









