







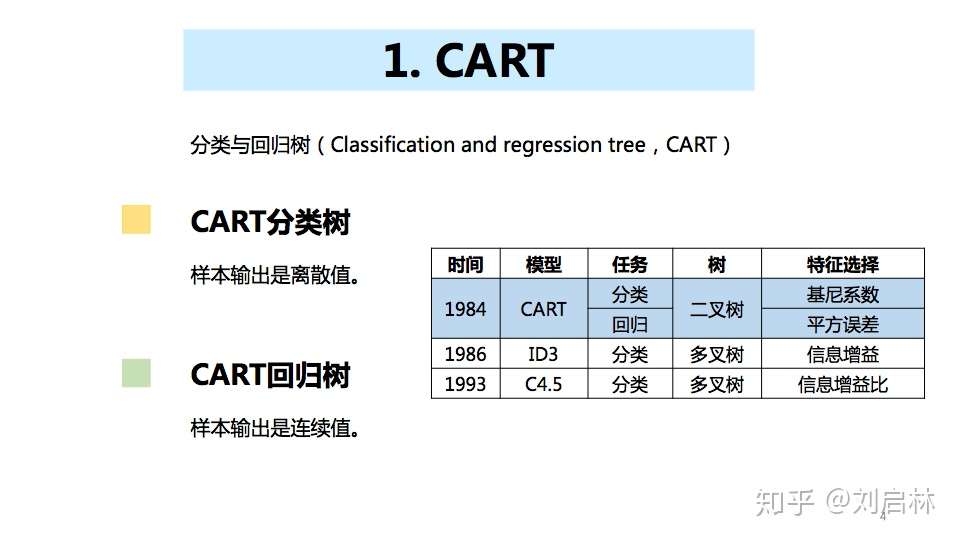
简介
XGBoost(eXtreme Gradient Boosting):极致梯度提升
1、原理
一堆CART树的集合,将每棵树的预测值加在一起得到最后的预测值。xgboost利用了损失函数二阶导的信息,并在目标函数之外加入了正则项,避免过拟合。
2、优点
高效、灵活、轻便
在传统boosting的基础上,利用cpu的多线程,引入正则化项,控制了模型的复杂度。并且xgb可并行处理,并能对缺失值处理,还内置交叉验证。
基础——GBDT
XGBoost和GBDT的基本思想相同,但做出了一些优化,故先介绍GBDT
梯度提升决策树(Gradient Boosting Decision Tree,GBDT)是一种基于boosting集成思想的加法模型,训练时采样前向分布算法进行贪婪学习,每次迭代都学习一棵CART树来拟合之前t-1棵树的预测结果与训练样本真实值的残差。
GBDT中的树是CART回归树。
缺点:依赖强,并行难,效率低
算法:
-
初始化弱学习器。取损失函数为平方损失,求导令导数为0,得到初始学习器为训练样本标签的均值
-
迭代训练m=1,2,…,M棵树
(1)对每个样本i=1,2,…,N计算负梯度(用其近似模拟残差) r m i r_{mi} rmi
(2)将该残差作为样本新的真实值,并将数据 ( x i , r m i ) (x_i,r_{mi}) (xi,rmi)作为下棵树的训练数据,得到一颗新的回归树
(3)对每个叶子节点计算最佳拟合值
(4)更新强学习器
-
得到最终学习器GBDT
XGBoost
优化:
- 利用二阶泰勒公式展开,优化损失函数,提高计算精确度
- 利用正则项,简化模型,避免过拟合
- 采用Blocks存储结构,可以并行计算等
目标函数:
损失函数 + 正则化项















 1027
1027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









