






基于pytorch的LSTM单变量预测的实例
说明:
初学pytorch,试着做一做实例。数据处理参考了一些大佬的代码。
数据集来源于:champagne.csv · MJ/Datasets - Gitee.com
1.import库+读取数据集
df.fillna()#对缺失值进行填充,mean是一列的平均数。
import torch
import torch.nn as nn
import pandas as pd
import numpy as np
from scipy.interpolate import make_interp_spline
from torch.utils.data import Dataset,DataLoader
from itertools import chain
import matplotlib.pyplot as plt
def read_csv(filename):
df=pd.read_csv(filename)
colums=df.columns
df.fillna(df.mean(),inplace=True)
#归一化处理
MAX=np.max(df[colums[1]])
MIN=np.min(df[colums[1]])
df[colums[1]]=(df[colums[1]]-MIN)/(MAX-MIN)
return df2.数据预处理
由于LSTM是时间序列预测,所以需要seq_len,以下代码中8就是seq_len。
原理:通过前8个时刻的数据来预测下一个时刻。
def process(filename,b):
print("procedding-------")
data=read_csv(filename)
print(data.shape)
load=data[data.columns[1]]
load=load.tolist()
data=data.values.tolist()
seq=[]
for i in range(len(data)-8):#8个时刻为一组
train_seq=[]
train_label=[]
for j in range(i,i+8):
x=[load[j]]
#如果是多变量,在这里可以添加列
train_seq.append(x)
train_label.append(load[i+8])
train_seq=torch.FloatTensor(train_seq)
train_label=torch.FloatTensor(train_label)
seq.append((train_seq,train_label))
print(len(seq))
Dtr=seq[:int(len(seq)*0.8)]
Dte=seq
train_len=int(len(Dtr)/b)*b
test_len=int(len(Dte)/b)*b
Dtr,Dte=Dtr[:train_len],Dte[:test_len]
Dtr=DataLoader(dataset=Dtr,batch_size=b,shuffle=False,num_workers=0)
Dte=DataLoader(dataset=Dte,batch_size=b,shuffle=False,num_workers=0)
return Dtr,Dte3.LSTM搭建
pred[:-1:]是为了只取最后一个时刻的数据。
class LSTM(nn.Module):
def __init__(self,input_size,hidden_size,num_layers,output_size,batch_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.output_size = output_size
self.num_directions = 1
self.batch_size = batch_size
self.lstm=nn.LSTM(self.input_size,self.hidden_size,self.num_layers,batch_first=True)
self.linear=nn.Linear(self.hidden_size,self.output_size)
def forward(self,input):
seq_len = input.shape[1]
#input(batch_size, seq_len, input_size)
output,_=self.lstm(input)
pred=self.linear(output)
pred=pred[:,-1,:]
return pred4.训练
optimizer.step()这步不能忘记,否则结果只是限定在一个小范围内。
def train(name,b):
Dtr,Dte=process(filename=name,b=b)
model=LSTM(input_size=1,hidden_size=12,output_size=1,num_layers=1,batch_size=b)
print(model)
loss_fu=nn.MSELoss()
optimizer=torch.optim.Adam(model.parameters(),lr=0.01)
epoch=40
for i in range(epoch):
cnt=0
print('NOW',i)
for(seq,label) in Dtr:
cnt+=1
y_pred=model(seq)
loss=loss_fu(y_pred,label)
optimizer.zero_grad()
loss.backward()
optimizer.step()#梯度上升
print('epoch',i,':',cnt,loss.item())
5.测试结果
make_interp_spline插值法,是一种曲线平滑处理的方法。
可参考Python scipy.interpolate.make_interp_spline用法及代码示例 - 纯净天空 (vimsky.com)
x = [i for i in range(1, 97)]#x是横坐标 1-96
x = np.linspace(np.min(x), np.max(x), 900)
#np.linspace(start,end,num)在start 和end之间返回900个数字 np.min 是返回最小的数字
y = make_interp_spline(x, y.T)(x)#画图方式 x,y行数要一样
plt.plot(x, y, c='green', marker='*', ms=1, alpha=0.75, label='true')
y = make_interp_spline(x, pred.T)(x)#预测的
plt.plot(x, y, c='red', marker='o', ms=1, alpha=0.75, label='pred')
#plt.grid(axis='y')
plt.legend()#图例的名称
plt.show()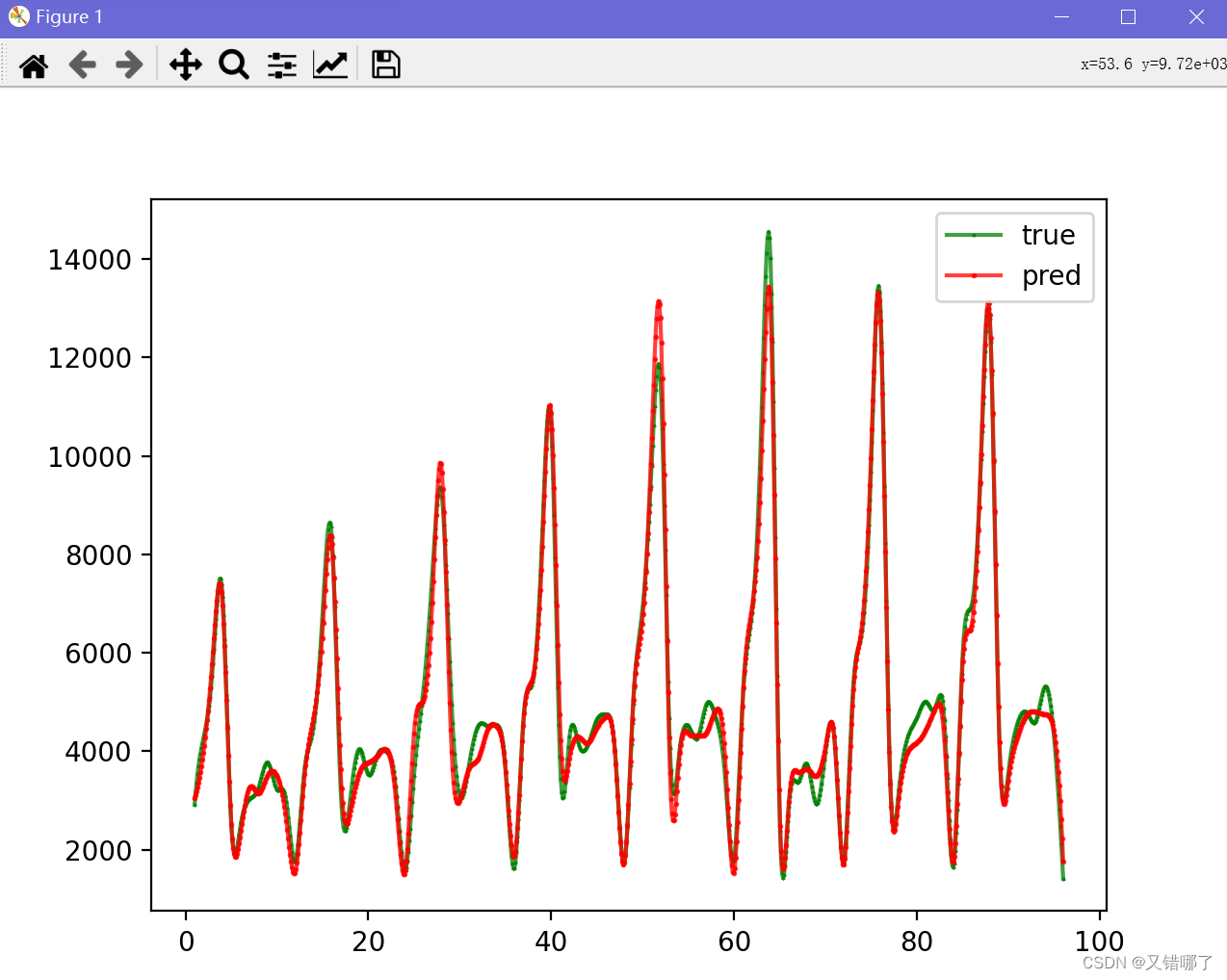
结果似乎还不错。文章有什么问题的话,欢迎指正。
8.22更新
阅读了一些单步预测的文章,发现一些自身的问题:
每次预测时都是用前8个时刻的真实值来预测下一个时刻,实际应用这种预测做的没有意义。应该将第9个的预测值加入数据集中,并参与到预测,实现迭代预测。但是这样误差会越来越大。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









