







1、协同过滤、矩阵分解(稀疏矩阵✓)
用户作为矩阵行坐标,物品作为列坐标

-
计算用户相似度 >> top N 个相似用户
每个用户对应的行向量其实就可以当作一个用户的 Embedding 向量,“余弦相似度”
-
用户评分的预测 >> 根据预测得分进行排序后输出
在获得 Top n 个相似用户之后,利用 Top n 用户生成最终的用户 u 对物品 p 的评分
利用用户相似度和相似用户评价的加权平均值,来获得目标用户的评价预测
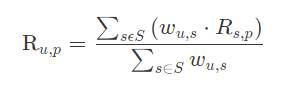
权重 wu,s 是用户 u 和用户 s 的相似度,Rs,p 是用户 s 对物品 p 的评分
- 矩阵分解算法(for 稀疏矩阵)


2、模型特征
一是样本从哪里来,二是样本的标签是什么(CTR预估)
注意引入未来信息(Future Information)的问题
我们利用 t 时刻的样本进行训练,但是使用了全量的样本生成特征,这些特征就包含了 t+1 时刻的未来信息,这就是一个典型的引入未来信息的错误例子。
在处理历史行为相关的特征的时候,我们一定要考虑未来信息问题,
Spark 中,我们应该如何处理这些跟历史行为相关的特征呢?这就需要用到 window 函数了
(创建一个滑动窗口)
3、Embeddig + MLP


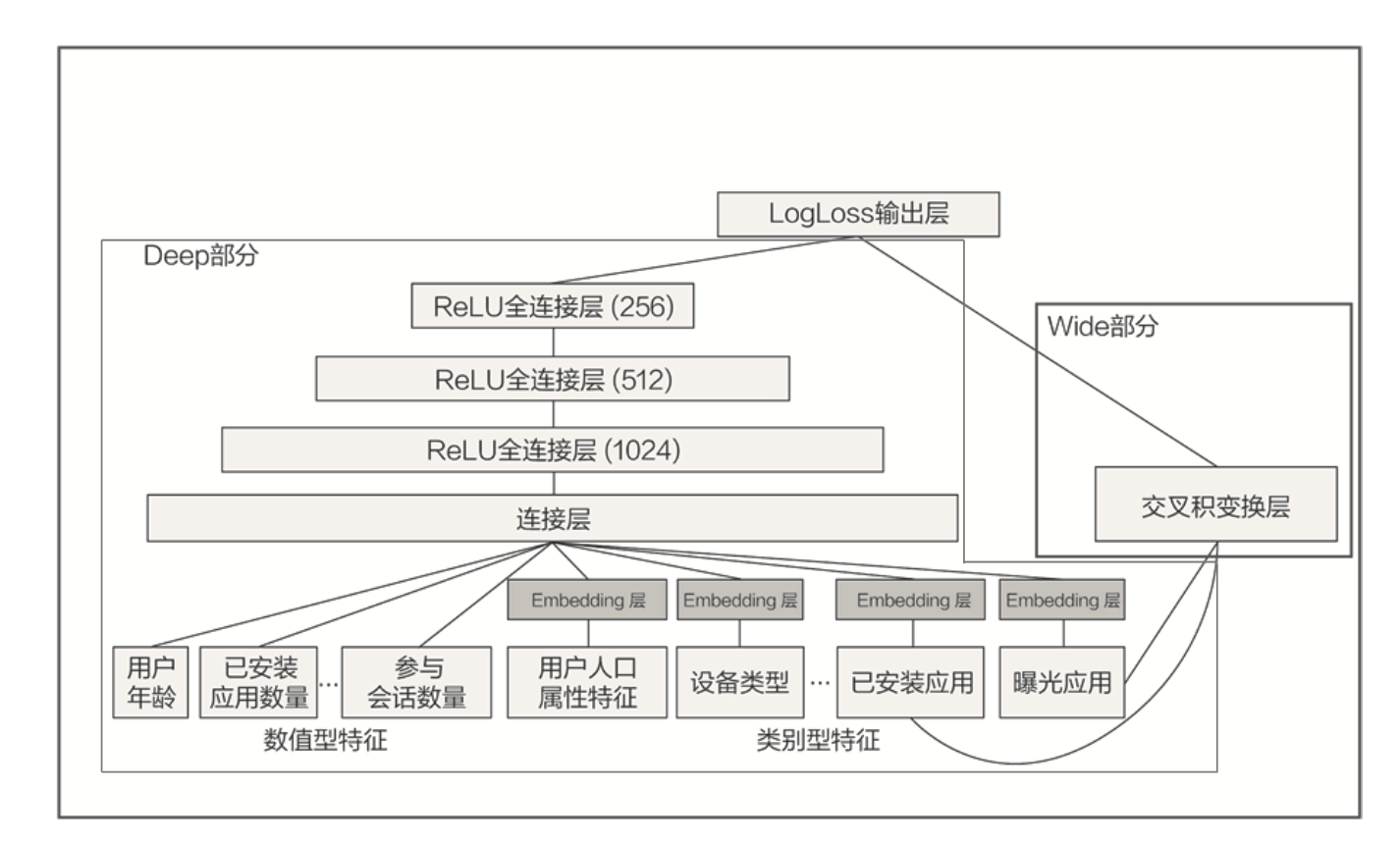
4、Wide &Deep(记忆 + 泛化)

“记忆能力”,可以被宽泛地理解为模型直接学习历史数据中物品或者特征的“共现频率”,并且把它们直接作为推荐依据的能力 。
“泛化能力”指的是模型对于新鲜样本、以及从未出现过的特征组合的预测能力。
5、Neural CF
对协同过滤的改善,提高了协同过滤算法的泛化能力和拟合能力


我们可以把模型分成用户侧模型和物品侧模型两部分,然后用互操作层把这两部分联合起来,产生最后的预测得分。

双塔模型最重要的优势就在于它易上线、易服务。为什么这么说呢?
我们就可以把 u(x) 和 v(y) 存入特征数据库,这样一来,线上服务的时候,我们只要把 u(x) 和 v(y) 取出来,再对它们做简单的互操作层运算就可以得出最后的模型预估结果了!
6、DeepFM
为什么深度学习需要加强处理特征交叉的能力。
一个是用户喜欢的电影风格,一个是电影本身的风格,这两个特征明显具有很强的相关性。如果我们能让模型利用起这样的相关性,肯定会对最后的推荐效果有正向的影响。
那我们不如去设计一些特定的特征交叉结构,来把这些相关性强的特征,交叉组合在一起,这就是深度学习模型要加强特征交叉能力的原因了。
"辛普森悖论"
- 善于处理特征交叉的机器学习模型 FM(点积,concat)

FM 层中有多个内积操作单元对不同特征向量进行两两组合,这些操作单元会把不同特征的内积操作的结果输入最后的输出神经元,以此来完成最后的预测。
有两个地方需要我们重点注意,一个是 FM 部分的构建,另一个是 FM 部分的输出和 Deep 输出的连接。
- NFM(Neural Factorization Machines,神经网络因子分解机)(元素积,求和)

NFM 并没有使用内积操作来进行特征 Embedding 向量的交叉,而是使用元素积的操作。在得到交叉特征向量之后,也没有使用 concatenate 操作把它们连接起来,而是采用了求和的池化操作,把它们叠加起来。
要想再进一步提高推荐系统的效果,就需要清楚地知道业界有哪些新的思路可以借鉴,学术界有哪些新的思想可以尝试,
1-注意力机制和兴趣演化序列模型
计算注意力权重就是为了计算历史行为物品和广告物品的相关性
2-强化学习
“注意力机制”来源于人类天生的“选择性注意”的习惯。
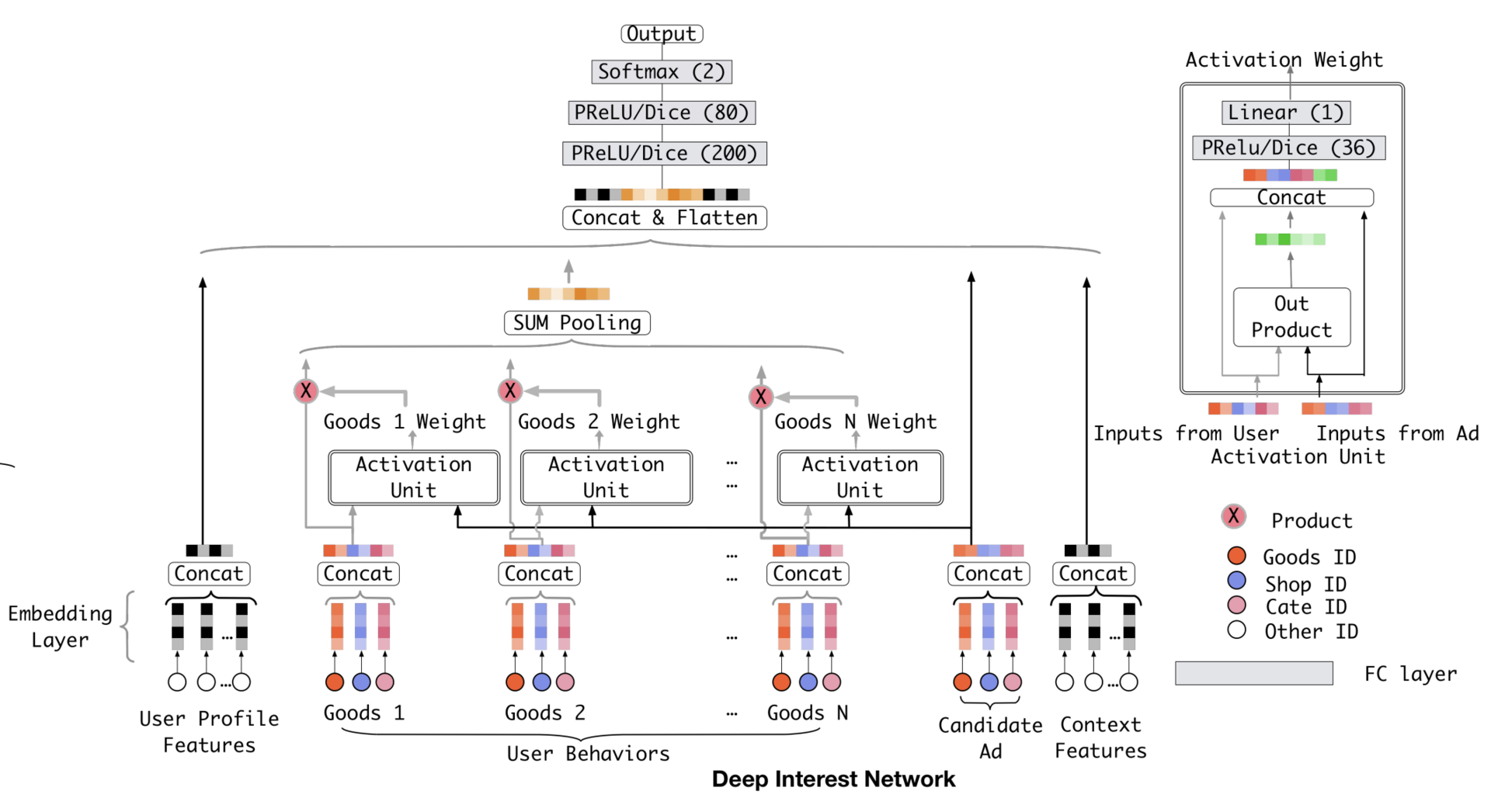
注意力机制已经成功应用在各种场景下的推荐系统中了,其中最知名的,要数阿里巴巴的深度推荐模型,DIN(Deep Interest Network,深度兴趣网络)
7、DIN 、DIEN
DIN 模型的应用场景是阿里最典型的电商广告推荐,本质上是点击率预估模型
注意力机制是怎么应用在 DIN 模型里的呢?
阿里正是在 Base Model 的基础上,把注意力机制应用在了用户的历史行为序列的处理上,从而形成了 DIN 模型
激活单元就相当于一个小的深度学习模型,它利用两个商品的 Embedding,生成了代表它们关联程度的注意力权重。
深度兴趣进化网络 DIEN(Deep Interest Evolution Network)
如果我们能让模型预测出用户购买商品的趋势,肯定会对提升推荐效果有益。而 DIEN 模型正好弥补了 DIN 模型没有对行为序列进行建模的缺陷,它围绕兴趣进化这个点进一步对 DIN 模型做了改进。
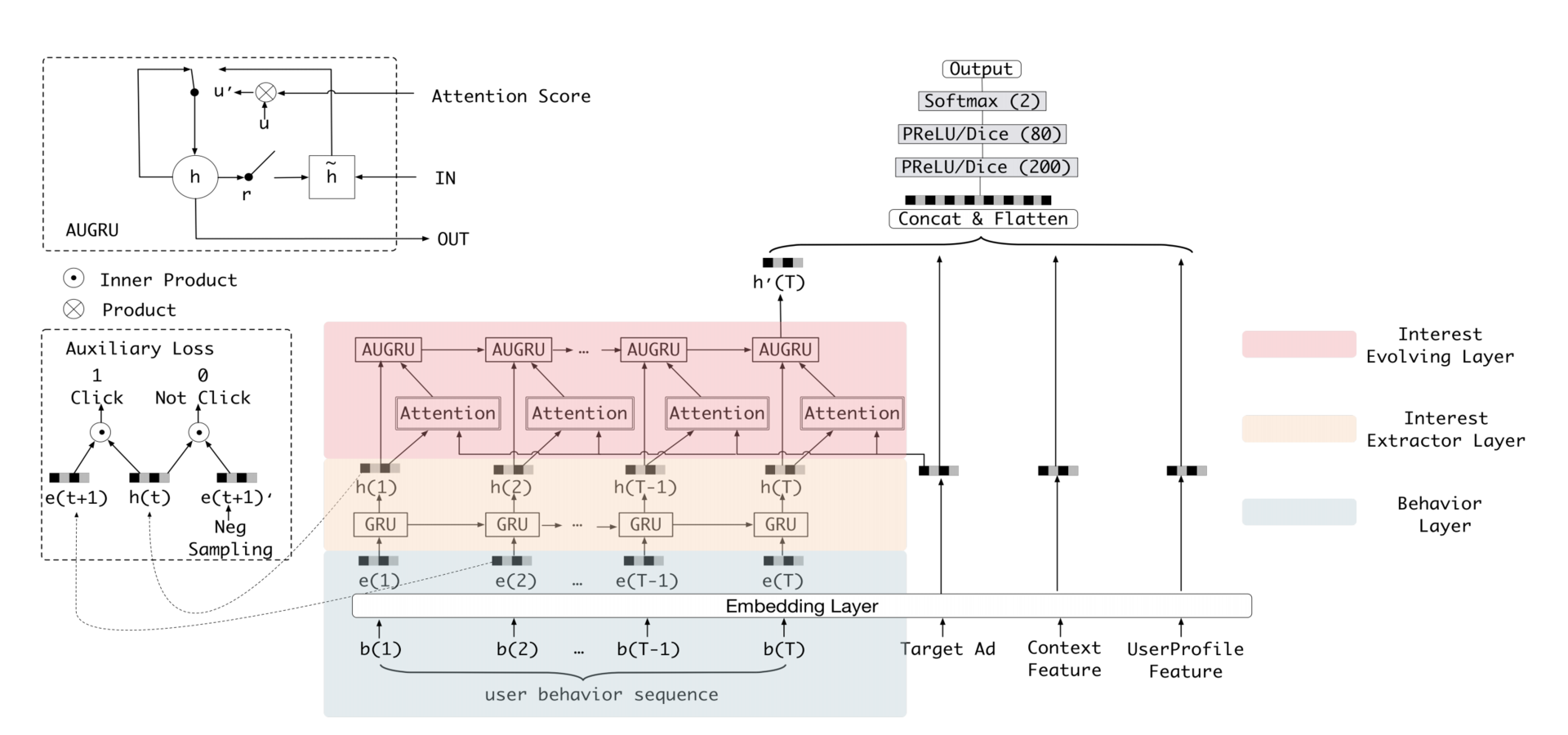
GRU 序列模型,它其实是序列模型的一种,根据序列模型神经元结构的不同,最经典的有RNN、LSTM、GRU这 3 种。
注意力机制的引入是对经典深度学习模型的一次大的改进,因为它改变了深度学习模型对待用户历史行为“一视同仁”的弊端。而序列模型则把用户行为串联起来,让用户的兴趣随时间进行演化,这也是之前的深度学习模型完全没有考虑到的结构。
8、强化学习
就是一个智能体通过与环境进行交互,不断学习强化自己的智力,来指导自己的下一步行动,以取得最大化的预期利益。

DRN 正是通过这种方式,让模型时刻与最“新鲜”的数据保持同步,实时地把最新的奖励信息融合进模型中。模型的每次“探索”和更新也就是我们之前提到的模型“微更新”。

一个是 DRN 构建了双塔模型作为深度推荐模型,来得出“行动得分”。第二个是 DRN 的更新方式,它利用“微更新”实时地学习用户的奖励反馈,更新推荐模型,再利用阶段性的“主更新”学习全量样本,更新模型。第三个是微更新时的方法,竞争梯度下降算法,它通过比较原网络和探索网络的实时效果,来更新模型的参数。
9、存在银弹吗?
















 968
968











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









