







1. Spark架构设计
Spark集群当中一般会有三个角色,分别是资源管理节点(Cluster Manager)、工作控制节点(Driver)和工作执行节点(Worker Node)

相比于MapReduce框架,Spark所采用的Executor有2有两个优点:
-
每个任务有自己专属的采用多线程的方式来执行任务,并且在任务执行的过程当中一直保持着驻留的状态。相比于
MapReduce所采用的多进程模型来说,这样的设计避免了多进程任务频繁的启动开销,使得任务执行变得更加高效和可靠。 -
每个
Executor上都有一个BlockManager模块,默认使用内存作为存储设备,内存不足时再写入磁盘。其主要存储计算的中间结果,相比于MapReduce框架来说,减少了HDFS等文件系统的读写操作。
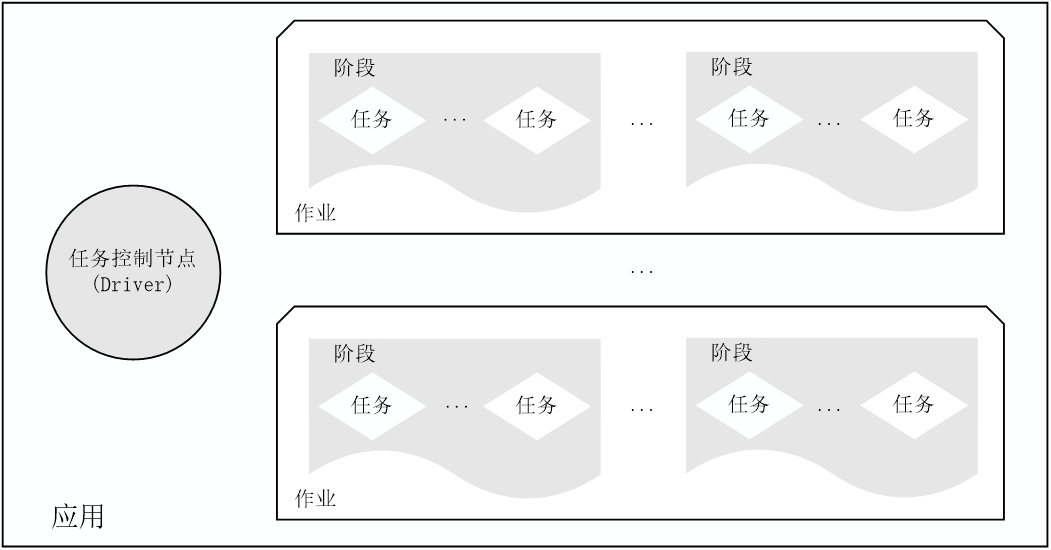
我们还可以从另一个逻辑结构的视角来看Spark的设计,其中的某一个应用程序(Application)主要由一个控制节点(Driver)和多个作业(Job)组成。而每一个作业(Job)又是由多个阶段(Stage)组成,每个阶段(Stage)内是没有Shuffle关系的任务(Task),阶段(Stage)和阶段(Stage)之间应该有Shuffle操作。与上文相呼应的是任务(Task),它跑在工作执行节点(Worker Node)的Executor当中,是具体执行处理操作的角色,但是在逻辑是由控制节点(Driver)进行调控。
2. Spark运行基本流程
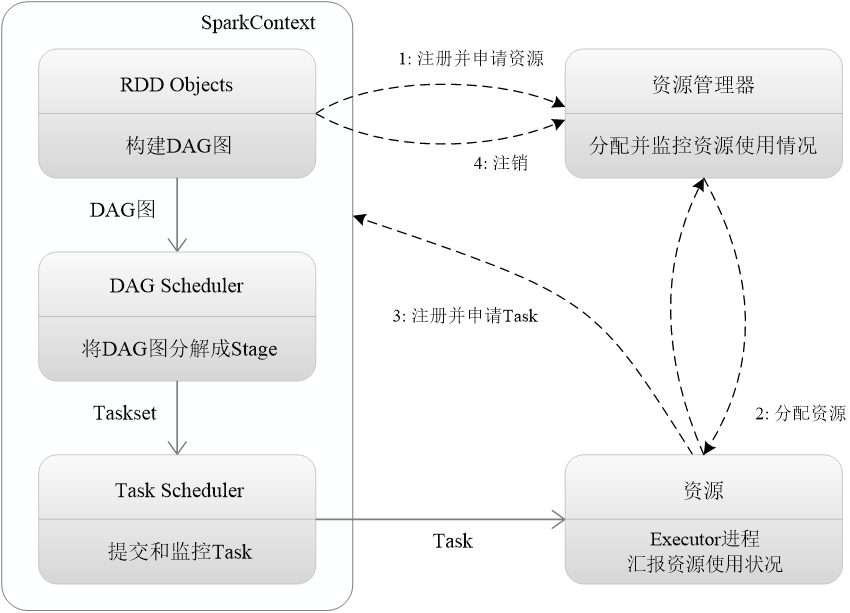
首先为应用构建起基本的运行环境,即由Driver创建一个SparkContext,进行资源的申请、任务的分配和监控
资源管理器为Executor分配资源,并启动Executor进程
SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAGScheduler解析成Stage,然后把一个个TaskSet提交给底层调度器TaskScheduler处理;Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor运行,并提供应用程序代码
Task在Executor上运行,把执行结果反馈给TaskScheduler,然后反馈给DAGScheduler,运行完毕后写入数据并释放所有资源
3. Shuffle操作
在这里我们主要叙述一下Reduce端的Shuffle操作,与MapReduce的流程不同,这里的更像是Combine操作。
Spark在设计时所遵循的假设是,数据的排序操作不是所必须的。
其主要维护了一个HashMap,针对每一个Key只维护一个<K,V>的键值对
对于新数据,如果存在Key就直接累加Value,不存在就新建
4. 依赖关系
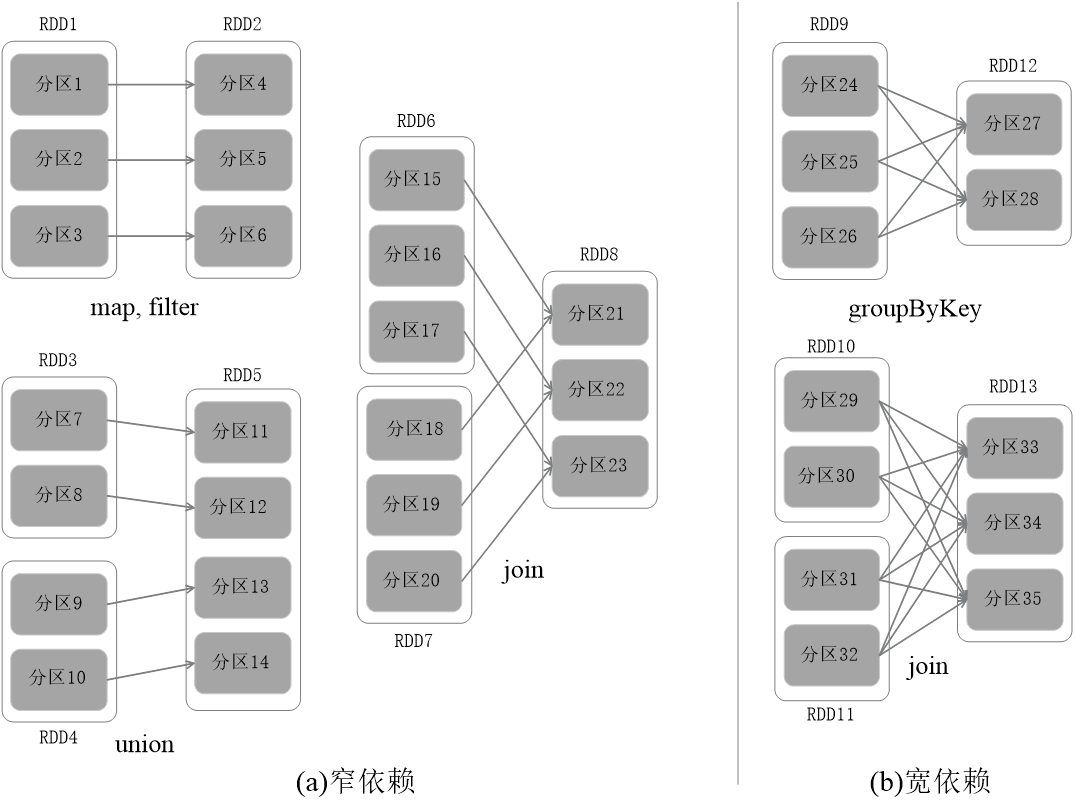
窄依赖表现为一个父RDD的分区对应于一个子RDD的分区或多个父RDD的分区对应于一个子RDD的分区
宽依赖则表现为存在一个父RDD的一个分区对应一个子RDD的多个分区
RDD之间的依赖关系分为宽依赖和窄依赖两种,在阶段划分的时候以此作为标志
一般来说是在DAG当中反向解析,遇到宽依赖就断开阶段
如果遇到的是窄依赖就把当前的RDD加入到Stage当中
我们需要尽量地将窄依赖划分在同一个Stage当中,这样可以实现流水线计算
更详细的资料请参考1,是《Spark编程基础(Python版)》教材配套讲义PPT的第2章-Spark的设计与运行原理2
5. 环境配置
我这里用的是自己的服务器,新建conda环境,也可以在本地机器
或者可以用百度的飞桨3,也可以用阿里的天池实验室4,直接pip install pyspark
可以参考5来持久化安装一下Python的包,避免再次登录之后重复安装
我还发现了一个很好的教程,用的和鲸社区,这是代码6,这是文档7
原本用的是飞桨的notebook,但是发现导出到md太分散了,一块一块的
然后每一块前面都有标那个行号,看起来挺乱的,效果不好
根据我之前的经验,不如直接在python的交互命令行里面操作
然后把代码整体粘贴到博客成为一块,文字和代码分离应该看起来比较好
Update_2024-03-21----------------------------------------------
大概意思是说,安装PySpark的时候,也会顺带安装一个单机模式的Spark,不过这个Spark仅支持Python,也就是没有Scala那些接口,貌似从 18 年之后的版本就是这样了
我没有去文件夹做验证,但据我之前的使用经验来看好像是这样的,我之前貌似在 win10 上单独装过 PySpark,反正是能运行的,对于学习而言一般是够用的。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









