






整体框架
代码主要由两部分组成,特征提取(forward_features)和分类头(head)两部分。
输入的x的维度为[1,3,8,224,224]
特征提取
def forward_features(self, x):
B = x.shape[0]
1、###################################################
#对x进行分块,并对每个patch进行embed输出一个向量来表示这个patch,
#输入x:[1,3,8,224,224]
#输出x:[8,196,768]
x, T, W = self.patch_embed(x)
cls_tokens = self.cls_token.expand(x.size(0), -1, -1)
#将cls_token和path拼接起来
x = torch.cat((cls_tokens, x), dim=1)
## resizing the positional embeddings in case they don't match the input at inference
if x.size(1) != self.pos_embed.size(1):
pos_embed = self.pos_embed
cls_pos_embed = pos_embed[0,0,:].unsqueeze(0).unsqueeze(1)
other_pos_embed = pos_embed[0,1:,:].unsqueeze(0).transpose(1, 2)
P = int(other_pos_embed.size(2) ** 0.5)
H = x.size(1) // W
other_pos_embed = other_pos_embed.reshape(1, x.size(2), P, P)
new_pos_embed = F.interpolate(other_pos_embed, size=(H, W), mode='nearest')
new_pos_embed = new_pos_embed.flatten(2)
new_pos_embed = new_pos_embed.transpose(1, 2)
new_pos_embed = torch.cat((cls_pos_embed, new_pos_embed), 1)
x = x + new_pos_embed
else:
#加入位置编码
#x的维度[(b t) n m],即8,197, 768,
#批次(1)*时间(总共采样8张图片),patch数(196+1个cls_token),
#通道数(768=16*16*3)
#pos_embed的维度为[1,197,768]
#两者相加,由于广播机制,pos_embed的维度会自动扩展为[8,197,768]
#这样可以保证x[(b t) n m]在第0维度相等,而只是不同patch(位置)加的值不一样而已
#[8,197,768]+[1,197,768]=[8,197,768]+[8,197,768]
x = x + self.pos_embed
x = self.pos_drop(x)
2、###################################################
#加入时间编码,类似于之前的位置编码,值得注意的是,在进行时间编码时,需要进行维度变换
#x为(b t) n m -> (b n) t m
#去除cls_token [8,197,768]->[8,197,768]
#[8,196,768]->[196,8,768]
## Time Embeddings
if self.attention_type != 'space_only':
cls_tokens = x[:B, 0, :].unsqueeze(1)
#除了cls_token外,所有的都要加上时间编码
x = x[:,1:]
x = rearrange(x, '(b t) n m -> (b n) t m',b=B,t=T)
## Resizing time embeddings in case they don't match
if T != self.time_embed.size(1):
time_embed = self.time_embed.transpose(1, 2)
new_time_embed = F.interpolate(time_embed, size=(T), mode='nearest')
new_time_embed = new_time_embed.transpose(1, 2)
x = x + new_time_embed
else:
#time_embed的维度为[1,8,768],由于广播机制,使得其在不同时间上加上了位置编码
#[196,8,768]+[1,8,768]=[196,8,768]+[196,8,768]
x = x + self.time_embed
x = self.time_drop(x)
x = rearrange(x, '(b n) t m -> b (n t) m',b=B,t=T)
x = torch.cat((cls_tokens, x), dim=1)
3、###################################################
## Attention blocks
for blk in self.blocks:
x = blk(x, B, T, W)
### Predictions for space-only baseline
if self.attention_type == 'space_only':
x = rearrange(x, '(b t) n m -> b t n m',b=B,t=T)
x = torch.mean(x, 1) # averaging predictions for every frame
x = self.norm(x)
return x[:, 0]
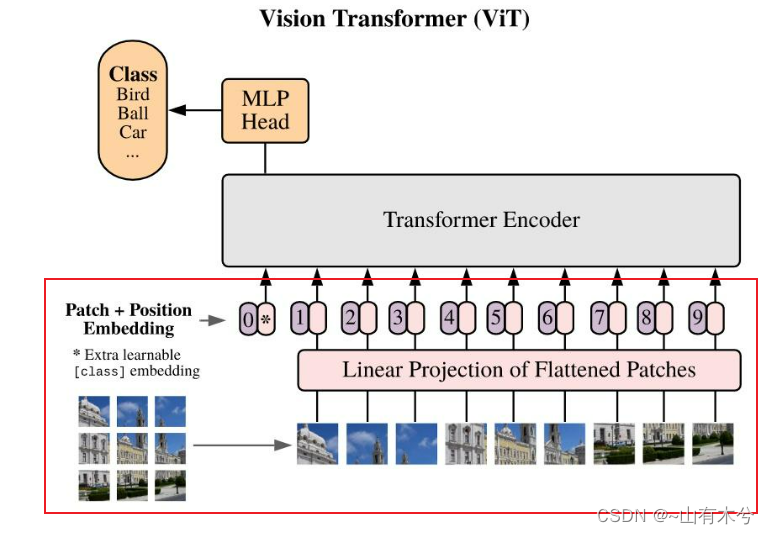
一、这一部分就是下图框起来的部分
二、时间编码
根据注意力类型判断是否需要加时间编码,这个时间编码主要是为了后续进行Time Attention;
就像加入位置编码后,用以Space Attention一样。
三、注意力块
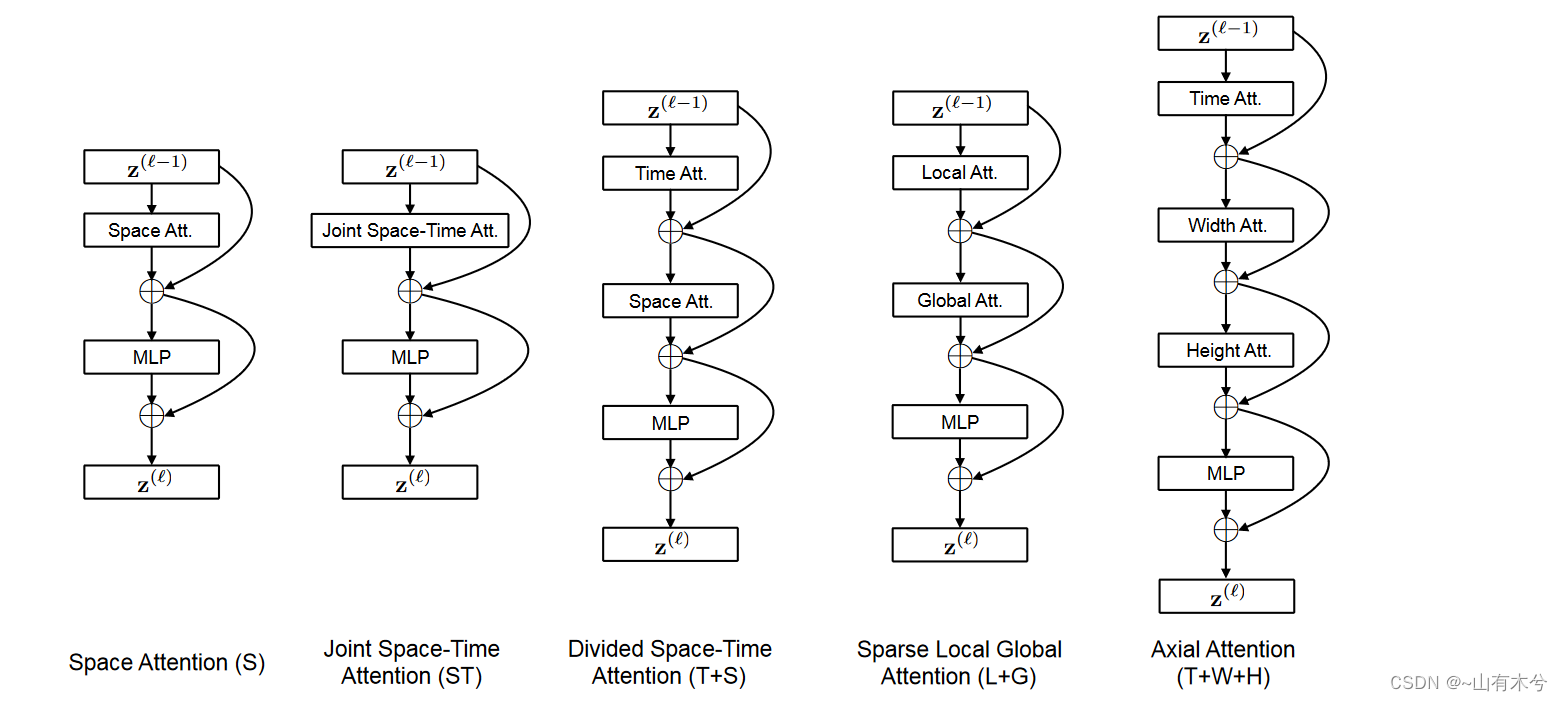
ModuleList(
(0): Block(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(attn_drop): Dropout(p=0.0, inplace=False)
)
(temporal_norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(temporal_attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(attn_drop): Dropout(p=0.0, inplace=False)
)
(temporal_fc): Linear(in_features=768, out_features=768, bias=True)
(drop_path): Identity()
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU(approximate=none)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
***重复depth次,根据Timesformer初始化传入的depth值来确定*
)
下面就是一个block所执行的代码
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0.1, act_layer=nn.GELU, norm_layer=nn.LayerNorm, attention_type='divided_space_time'):
super().__init__()
self.attention_type = attention_type
assert(attention_type in ['divided_space_time', 'space_only','joint_space_time'])
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
## Temporal Attention Parameters
if self.attention_type == 'divided_space_time':
self.temporal_norm1 = norm_layer(dim)
self.temporal_attn = Attention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.temporal_fc = nn.Linear(dim, dim)
## drop path
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x, B, T, W):
num_spatial_tokens = (x.size(1) - 1) // T
H = num_spatial_tokens // W
#判断注意力类型
if self.attention_type in ['space_only', 'joint_space_time']:
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
elif self.attention_type == 'divided_space_time':
## Temporal
#cls_token不参与attention计算
xt = x[:,1:,:]
xt = rearrange(xt, 'b (h w t) m -> (b h w) t m',b=B,h=H,w=W,t=T)
#xt【1,1568,768】>>>>>>【196,18,768】
#norm>>>attention>>>DropPath
res_temporal = self.drop_path(self.temporal_attn(self.temporal_norm1(xt)))
res_temporal = rearrange(res_temporal, '(b h w) t m -> b (h w t) m',b=B,h=H,w=W,t=T)
res_temporal = self.temporal_fc(res_temporal)
#res_temporal【1,1568,768】,时间自注意力
#xt【1,1568,768】,xt不包含cls_token
xt = x[:,1:,:] + res_temporal
#cls_token沿着时间维度上复制T次,然后变换成(b t) m,进行spatial attention
init_cls_token = x[:,0,:].unsqueeze(1)
cls_token = init_cls_token.repeat(1, T, 1)
cls_token = rearrange(cls_token, 'b t m -> (b t) m',b=B,t=T).unsqueeze(1)
## Spatial
xs = xt
xs = rearrange(xs, 'b (h w t) m -> (b t) (h w) m',b=B,h=H,w=W,t=T)
#xs【8,196,768】
#cls_token【8,1,768】
#xs【8,197,768】
#输入attention的维度也为8,197,768
xs = torch.cat((cls_token, xs), 1)
#res_spatial 【8,197,768】
res_spatial = self.drop_path(self.attn(self.norm1(xs)))
### Taking care of CLS token
cls_token = res_spatial[:,0,:]
#cls_token 【8,768】>>>>>>>>【1,8,768】>>>mean>>>>>【1,1,768】
cls_token = rearrange(cls_token, '(b t) m -> b t m',b=B,t=T)
cls_token = torch.mean(cls_token,1,True) ## averaging for every frame
res_spatial = res_spatial[:,1:,:]
#res_spatial【8,196,768】>>>>>>>>【1,1568,768】
res_spatial = rearrange(res_spatial, '(b t) (h w) m -> b (h w t) m',b=B,h=H,w=W,t=T)
res = res_spatial
x = xt
## Mlp,全连接操作
x = torch.cat((init_cls_token, x), 1) + torch.cat((cls_token, res), 1)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
经过block之后的x的维度大小为x【1,1569,768】,最后返回为x[:,0]为【1,768】
可以参考学习详解Transformer中Self-Attention以及Multi-Head Attention
用到的Attention实现:
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., with_qkv=True):
super().__init__()
#多头数目
self.num_heads = num_heads
#每一头对应的维度
head_dim = dim // num_heads
#self-attention 公式的根号d
self.scale = qk_scale or head_dim ** -0.5
self.with_qkv = with_qkv
#生成q,k,v
if self.with_qkv:
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.attn_drop = nn.Dropout(attn_drop)
def forward(self, x):
B, N, C = x.shape
if self.with_qkv:
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
else:
qkv = x.reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
q, k, v = qkv, qkv, qkv
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
if self.with_qkv:
#这里实现的是concate和乘以Wo矩阵,用一个全连接层代替,因为是以矩阵形式表示的,所以不需要concate步骤,即原来就是一个整体,即矩阵可以实现并行计算
x = self.proj(x)
x = self.proj_drop(x)
return x
行为分类
最后返回的x[1,768为]经过分类头
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
,求得每一个类别的概率,取一个最大值,即实现了分类。















 1276
1276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









