







原论文
将ViT适配到视频,较3D Conv精度很小的下降但速度显著提高,可以用于更长时间的视频(超过一分钟)。
ViT
Bert的Add&Norm在后面,即Multi-head Attention -> Add&Norm -> Feed Forward -> Add&Norm,所以最后的输出特征是LayerNorm之后的,不需要LayerNorm后再使用。
ViT系列的Add&Norm在前面,即Norm -> Multi-head Attention -> Add -> Norm -> Feed Forward -> Add,所以最后的输出特征最好经过LayerNorm后使用。
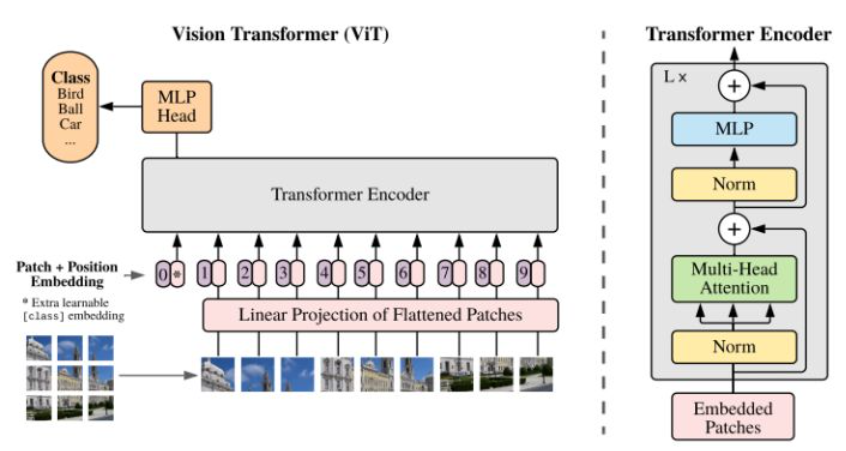
按照上面的流程图,一个ViT block可以分为以下几个步骤:




TimeSformer
Bert的Add&Norm在后面,即Multi-head Attention -> Add&Norm -> Feed Forward -> Add&Norm,所以最后的输出特征是LayerNorm之后的,不需要LayerNorm后再使用。
ViT系列的Add&Norm在前面,即Norm -> Multi-head Attention -> Add -> Norm -> Feed Forward -> Add,所以最后的输出特征最好经过LayerNorm后使用。

经视频多帧图片分为N*F个patch,F为帧数,先在时间上计算自注意力(不带cls),再在空间上计算自注意力(带cls,对cls产生的多个特征向量取平均),比同时计算大大减小了计算量。
计算次数:由
(
N
F
+
1
)
2
−
>
F
N
2
+
N
(
F
+
1
)
2
计算次数:由(NF+1)^2 -> FN^2+N(F+1)^2
计算次数:由(NF+1)2−>FN2+N(F+1)2
# vit.py
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0.1, act_layer=nn.GELU, norm_layer=nn.LayerNorm, attention_type='divided_space_time'):
...
def forward(self, x, B, T, W):
num_spatial_tokens = (x.size(1) - 1) // T
H = num_spatial_tokens // W
if self.attention_type in ['space_only', 'joint_space_time']:
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
elif self.attention_type == 'divided_space_time':
## Temporal
## 时间内计算自注意力(不包含cls)
xt = x[:,1:,:]
xt = rearrange(xt, 'b (h w t) m -> (b h w) t m',b=B,h=H,w=W,t=T)
res_temporal = self.drop_path(self.temporal_attn(self.temporal_norm1(xt)))
res_temporal = rearrange(res_temporal, '(b h w) t m -> b (h w t) m',b=B,h=H,w=W,t=T)
res_temporal = self.temporal_fc(res_temporal)
xt = x[:,1:,:] + res_temporal
## Spatial
## 空间内计算自注意力(包含cls)
init_cls_token = x[:,0,:].unsqueeze(1)
cls_token = init_cls_token.repeat(1, T, 1)
cls_token = rearrange(cls_token, 'b t m -> (b t) m',b=B,t=T).unsqueeze(1)
xs = xt
xs = rearrange(xs, 'b (h w t) m -> (b t) (h w) m',b=B,h=H,w=W,t=T)
xs = torch.cat((cls_token, xs), 1)
res_spatial = self.drop_path(self.attn(self.norm1(xs)))
## Taking care of CLS token
## Spatial对于cls多次作为q产生的多个特征向量取平均
cls_token = res_spatial[:,0,:]
cls_token = rearrange(cls_token, '(b t) m -> b t m',b=B,t=T)
cls_token = torch.mean(cls_token,1,True) ## averaging for every frame
res_spatial = res_spatial[:,1:,:]
res_spatial = rearrange(res_spatial, '(b t) (h w) m -> b (h w t) m',b=B,h=H,w=W,t=T)
res = res_spatial
x = xt
## Mlp
x = torch.cat((init_cls_token, x), 1) + torch.cat((cls_token, res), 1)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
配置环境
conda create -n torch181 python=3.7
conda activate torch181
conda install pytorch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1 cudatoolkit=11.3 -c pytorch -c conda-forge
pip install fvcore simplejson einops timm psutil scikit-learn opencv-python tensorboard
conda install av -c conda-forge
conda install git -c conda-forge
git clone https://github.com/facebookresearch/TimeSformer
cd TimeSformer
python setup.py build develop
如果使用PyTorch 1.8.1则无需任何修改,如果使用PyTorch1.10.1,则需要:
TimeSformer/timesformer/models/resnet_helper.py 15
_LinearWithBias 改为 NonDynamicallyQuantizableLinear
TimeSformer/timesformer/models/vit_utils.py 14
from torch._six import container_abcs 改为 import collections.abc as container_abcs
预训练模型
预训练数据集:
| 数据集 | 描述 |
|---|---|
| Kinetics-400(K-400) | 该数据集包含400个人类动作类,每个动作至少有400个视频剪辑。每段视频时长约10秒,来自不同的YouTube视频。这些动作以人为中心,涵盖了广泛的类别,包括人与物体的交互,如演奏乐器,以及人与人的交互,如握手。 |
| Kinetics-600(K-600) | 我们描述了DeepMind Kinetics人类动作数据集的扩展,从400个类(每个类至少有400个视频剪辑)扩展到600个类(每个类至少有600个视频剪辑)。为了扩大数据集的规模,我们改变了数据收集过程,以便每个类使用多个查询,其中一些查询使用英语以外的语言——葡萄牙语。本文详细描述了数据集的两个版本之间的变化,包括一组综合的新版本的统计数据以及使用I3D神经网络体系结构的基线结果。这篇论文是公共测试集的基础真理标签发布的伴生文件。 |
| Something-Something-V2(SSv2) | 一个带标签的视频剪辑的大型集合,展示了人类对日常物体执行预定义的基本动作。数据集是由大量的众包工作者创建的。它允许机器学习模型对物理世界中发生的基本行为进行细致的理解。它包含220,847个视频,其中168,913个在训练集,24,777个在验证集,27,157个在测试集。有174个标签。 |
| HowTo100M | 由Miech等人在《HowTo100M:通过观看亿个解说视频片段学习文本视频嵌入》中介绍,HowTo100M是一个讲述视频的大型数据集,重点是教学视频,内容创作者教授复杂的任务,明确的意图是解释屏幕上的视觉内容。HowTo100M功能共: 1.366亿段配有字幕的视频剪辑来自120万段Youtube视频(15年的视频);23611活动来自烹饪、手工制作、个人护理、园艺或健身等领域;每个视频都配有字幕,可从Youtube上自动下载。 |
下载地址及配置:
| name | dataset | # of frames | spatial crop | acc@1 | acc@5 | url |
|---|---|---|---|---|---|---|
| TimeSformer | K400 | 8 | 224 | 77.9 | 93.2 | model |
| TimeSformer-HR | K400 | 16 | 448 | 79.6 | 94.0 | model |
| TimeSformer-L | K400 | 96 | 224 | 80.6 | 94.7 | model |
| name | dataset | # of frames | spatial crop | acc@1 | acc@5 | url |
|---|---|---|---|---|---|---|
| TimeSformer | K600 | 8 | 224 | 79.1 | 94.4 | model |
| TimeSformer-HR | K600 | 16 | 448 | 81.8 | 95.8 | model |
| TimeSformer-L | K600 | 96 | 224 | 82.2 | 95.6 | model |
| name | dataset | # of frames | spatial crop | acc@1 | acc@5 | url |
|---|---|---|---|---|---|---|
| TimeSformer | SSv2 | 8 | 224 | 59.1 | 85.6 | model |
| TimeSformer-HR | SSv2 | 16 | 448 | 61.8 | 86.9 | model |
| TimeSformer-L | SSv2 | 64 | 224 | 62.0 | 87.5 | model |
| name | dataset | # of frames | spatial crop | single clip coverage | acc@1 | url |
|---|---|---|---|---|---|---|
| TimeSformer | HowTo100M | 8 | 224 | 8.5s | 56.8 | model |
| TimeSformer | HowTo100M | 32 | 224 | 34.1s | 61.2 | model |
| TimeSformer | HowTo100M | 64 | 448 | 68.3s | 62.2 | model |
| TimeSformer | HowTo100M | 96 | 224 | 102.4s | 62.6 | model |
示例代码
以TimeSformer-L K600 96 224为例
# main.py 动作分类
import torch
from timesformer.models.vit import TimeSformer
# 如果img_size, num_classes, num_frames和pretrained_model模型定义的不匹配,可能导致部分参数被随机初始化(但不会报错)。
# 例如,将num_classes=600改为601,将导致model.head.weights和model.head.bias被随机初始化。
model = TimeSformer(img_size=224, num_classes=600, num_frames=96, attention_type='divided_space_time',
pretrained_model='pretrained/TimeSformer_divST_96x4_224_K600.pyth')
model = model.to(device='cuda')
dummy_video = torch.randn(2, 3, 96, 224, 224) # (batch x channels x frames x height x width)
dummy_video = dummy_video.to(device='cuda')
with torch.no_grad():
pred = model(dummy_video,) # (2, 600)
print(pred)
print(pred.shape)
TimeSformer(
(model): VisionTransformer(
(dropout): Dropout(p=0.0, inplace=False)
(patch_embed): PatchEmbed(
(proj): Conv2d(3, 768, kernel_size=(16, 16), stride=(16, 16))
)
(pos_drop): Dropout(p=0.0, inplace=False)
(time_drop): Dropout(p=0.0, inplace=False)
(blocks): ModuleList(
(0): Block(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(attn_drop): Dropout(p=0.0, inplace=False)
)
(temporal_norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(temporal_attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(attn_drop): Dropout(p=0.0, inplace=False)
)
(temporal_fc): Linear(in_features=768, out_features=768, bias=True)
(drop_path): Identity()
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
) * 12个
)
(norm): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(head): Linear(in_features=768, out_features=600, bias=True)
)
)
















 1465
1465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











