







目录
表1:员工表
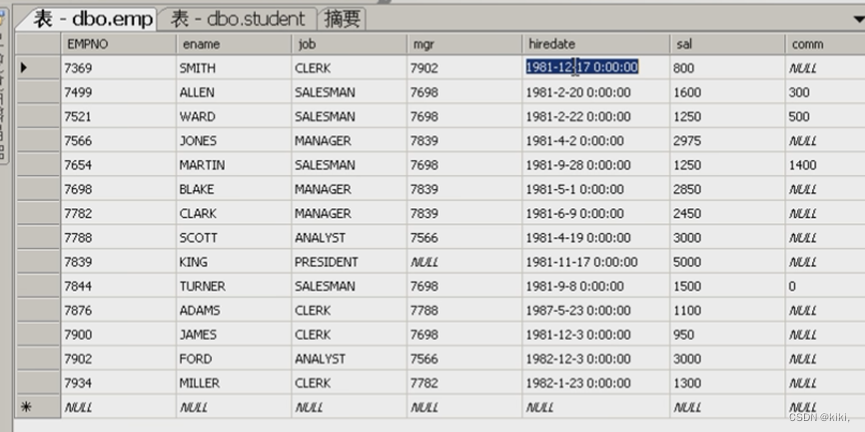
表2:部门表
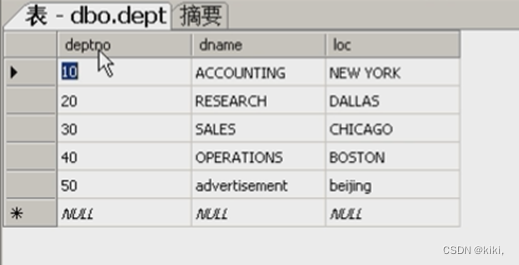
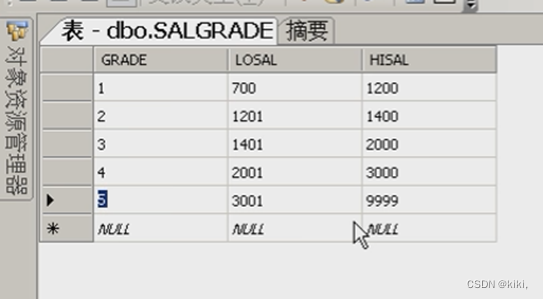
表3:薪资表
1.计算列
select ename,sal from emp;--输出员工表中的员工姓名和薪资
计算某一列的和用select sum(b) from a就可以输出a表中b这一列的和
Select * from emp;
--* 表示所有的
--from emp 表示从emp表查询
Select empno, ename from emp;
Select ename,sal from emp;
Eslect ename,sal*12 as “年薪”from emp;
--as 可以省略 记住“年薪”不要写成‘年薪’尽量写成双引号。
Select 5 from emp;
--ok 输出的行数是emp表的行数 每行只有一个字段值是5
Select 5;--ok 不推荐,一行
练习结果:
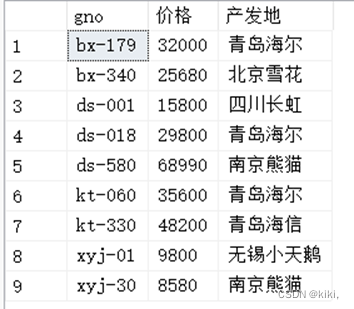
select 3 from goods;
--输出的行数是emp表的行数 每行只有一个字段,值是3
select gno,price*10 as"价格",producer "产发地"from goods;
--输出商品表中的商品名,价格在原有的价格上*10
(as)"价格":别名一定用双引号其余符号不可以
select *from goods;
--*表示所有的
--from goods 表示从goods表查询
select gno,gname from goods;
select gno,price*10 as "价格" from goods;
--as 可以省略, 记住"价格"不要写成'价格'或其他形式
select 5 from goods;
select gno,price*10 as"价格",producer "产发地"from goods;
select 888 from goods;
--ok
--输出的行数是emp表的行数 每行只有一个字段,值是888
2.Distinct【不允许重复的】
select distinct A from B;
--distinct A 过滤掉 重复的A
Select deptno from emp;
--14行记录并不是3行记录
Select distinct deptno from emp;
--distinct deptno会过滤掉重复的deptno
Select distinct comm from emp;
--也可以过滤掉重复的null,
Select distinct comm,deptno from emp;
--把comm和deptno的组合进行过滤
Select deptno,distinct comm from emp;
--error 逻辑上有冲突
3.Between【在某个范围】
--查找工资在1500到3000之间(包括1500和3000)的所有的员工的信息
Select * from emp
Where sal>=1500 and sal <=3000;
等价于:
Select * from emp
Where sal between 1500 and 3000;
--查找工资在小于1500或大于3000之间的所有员工的信息
Select * from emp
Where sal<1500 or sal>3000
等价于
Select * from emp
Where sal no between 1500and 3000;
练习结果:
select *from goods
where price =3200;
select * from goods
where price>=3000 and price<=5000;
select *from goods
where price between 3000 and 5000;
4.In【在某个里面,属于若干个孤立的值】
Select * from emp where sal (not) in (1500,3000,5000);
--把sal(不是)是1500,3000,5000的值输出
是的话等价于:
Select * from emp
Where sal = 1500 or sal=3000 or sal =5000;
不是的话
--数据库中不等于有两种表示
①Select * from emp
Where sal != 1500 and sal!=3000 and sal !=5000;
推荐使用第二种
②Select * from emp
Where sal <> 1500 and sal <> 3000 and sal <>5000;
对或取反是并,对并取反是或
5.top
语法格式: SELECT TOP n <列名表> FROM <表名> [查询条件]
--其中,n为要返回结果集中的记录条数
输出薪资在1500~3000之间按降序排列的前四名员工在表中的记录
select * from emp;
select top 2 * from emp;
select top 15 percent * from emp;
select top 4 * from emp
where sal between 1500 and 3000
order by sal desc —desc降序 不写则是默认升序
6.null 【没有值】
null不能参与<> !=运算
null不能参与任何数据运算,否则结果永远是null.
Select * from emp;
--输出奖金非空的员工的信息
Select *from emp where comm <> null;--输出为空error
Select * from emp where com !=null; --输出为空error,
--总结null不能参与<> !=运算
Select * from emp where comm=null; --输出为空error
--null可以参与is not is 运算
Select * from emp where comm is null;--输出奖金为空的员工信息
Select * from emp where comm is not null;
零和Null是不一样的,null表示空值,0表示一个确定的值。
任何类型的数据都允许为null
--输出每个员工的姓名 年薪(包含奖金)comm假设是一年的奖金
Select * from emp;
Select empno,ename,sal*12+comm “年薪” from emp;
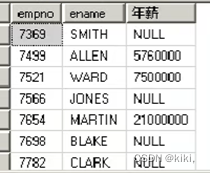
加上一个不是值的东西结果不是值,这样相加是不对的。
--证明null不能参与任何数据运算,否则结果永远是null.
--正确写法
Select ename,sal*12+isnull(comm,0) “年薪” from emp;
--isnull(comm ,0)如果comm是null就返回零否则返回comm的值
7. Order by【以某个字段排序】
Select * from emp order by sal;--默认升序
Select * from emp order by deptno,sal;--先按部门deptno排序,再按找工资sal排序
Select * from emp order by deptno desc,sal;
--先按照deptno降序排序,如果deptno相同再按照sal升序排序
--order by a desc,b,c,d;--desc只对a产生影响,不会对其他产生影响。
Select * from emp order by deptno ,sal desc;
--desc是否对deptno产生影响
--不会,先按照deptno升序,如果deptno相同,再按sal降序。
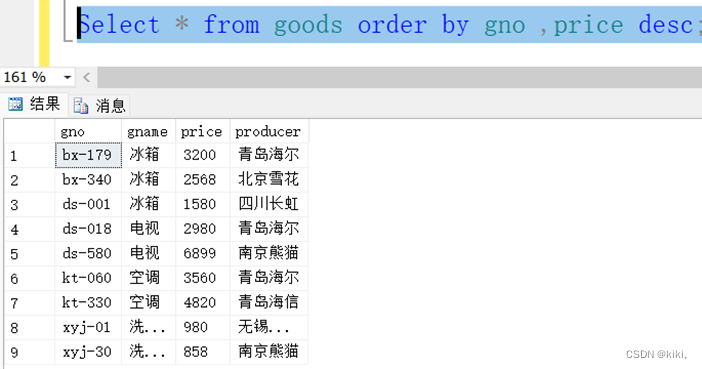
自己练习
先按照商品序号默认升序排序,如果相同则按照价格降序排序

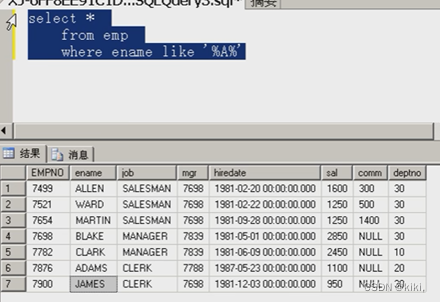
8.模糊查询【搜索时经常使用】
格式:Select *
From emp
Where ename like‘%A%’; --ename只要含有字母A就输出
A%--只要首字母是A就输出
%A—只要为字母是A就输出
这里可参考正则表达式
格式:
Select 字段集合
from 表明
where 某个字段的名字 like 匹配的条件;
匹配的条件通常含有通配符
通配符:
%百分号:表示任意0个或多个字符
_下划线:任意单个字符
[a-f]:a到f中的任意单个字符,只能是a b c d e f中的任意单个字符
[a,f]:a或f
[^a-c]:不是a也不是b也不是c也不是c的任意单个字符

注意:匹配的条件要使用单引号括起来,不能省略 也不能改用双引号


9.聚合函数【多行记录返回一个值,通常用于统计分组的信息】
函数的分类
单行函数:
每一行返回一个值
多行函数
多行返回一个值
聚合函数是多行函数
Select lower(ename) from emp;--最终返回14行
--lower()是单行函数
Select max(sal) from emp;
--返回一行max()是多行函数
聚合函数的分类
Max()
Min()
Avg()平均值
Count()求个数
Select count(*) from emp;--返回emp所有记录的个数
Select count(deptno) from emp;--返回是14这说明deptno重复记录也被返回
Select count(distinct deptno)from emp;--返回值是3 统计deptno不重复的deptno
Select count(comm) from emp;--返回值是4这说明comm为null的记录不会被当做有效的记录。
Count(*)返回表中所有记录的个数
Count(字段名)返回字段值非空的记录个数,重复的值也会被当做有效的记录
Count(distinct 字段名)返回字段不重复并且非空的记录个数
注意的问题:
判断如下sql语句是否正确
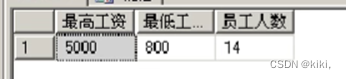
Select max(sal),min(sal),count(*) from emp;
Select max(sal)”最高工资”,min(sal) “最低工资”,count(*) “员工人数”from emp;
Select max(sal) ,lower(ename) from emp;
--error 单行函数和多行函数上不能混用。不然会出错。
10.Group by
Use 数据库名;切换数据库
Select * from emp;
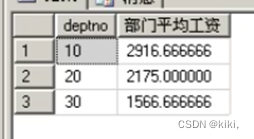
--输出每个部门编号 和该部门的平均工资
Select deptno, avg(sal) as “部门平均工资”
from emp
group by deptno
组分好后就不能显示组内的信息,统计的是组的信息
Select deptno, ename
from emp
group by deptno
![]()
总结:使用了group by 之后select中只能出现分组后的整体信息,不能出现组内的详细信息。
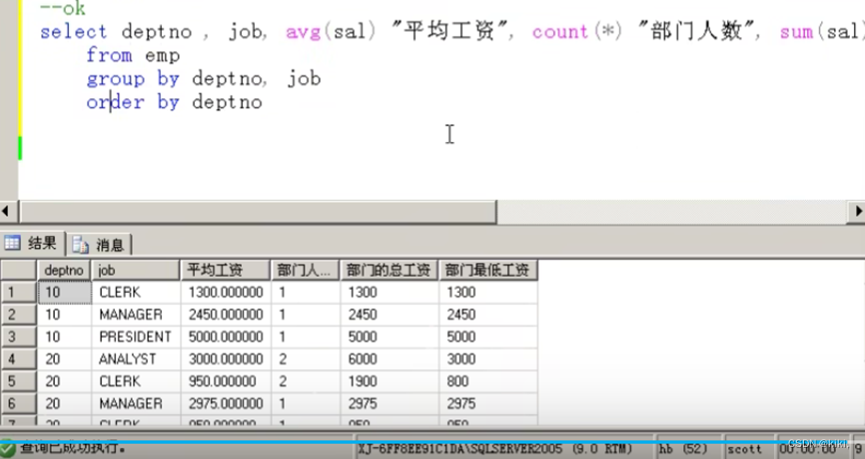
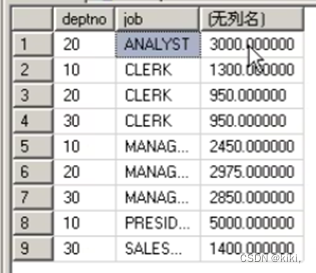
Group by a,b的用法
--error
Select deptno,job,sal (*) (deptno,job,avg(sal))-这个是正确的
From emp;
Group by deptno , job

格式:
Group by 字段的集合
功能:把表中的记录按照字段分成不同的组
注意:理解:group by a,b,c的用法
先按a分组,如果a相同,再按b分,如果b相同再按c分
最终统计的是最小分组的信息。
11.Having【对分组之后的信息进行过滤】
--输出部门的平均工资大于2000的部门的部门编号部门的平均工资
Select deptno avg(sal)
From emp
Group by deptno
Having avg(sal)>2000
--判断下列sql语句是否正确:
Select deptno avg(sal) as “平均工资”
From emp
Group by deptno
Having avg(sal)>2000
Select deptno avg(sal) as “平均工资”
From emp
Group by deptno
Having count(*)>3
Select deptno “部门编号” avg(sal) as “平均工资”
From emp
Group by deptno
Having deptno>1
12.连接查询
定义:
将两个表或者两个以上的表以一定的连接条件连接起来
从中检索出满足条件的数据
分类:
内连接(重要)
- select … from A,B的用法
- select … from A,B where…的用法
- select … from A join B on…的用法
-
select … from A,B where…
与
Select …from A join B on …
的比较
- select 、from、 where、 join、 group、 order、 top 、having的混合使用
select "G".gname, "I".number
from goods "G"
join invent "I" ---join是连接
on "G".gno= "I".gno --on表示连接条件,on不能省,有join就必须有on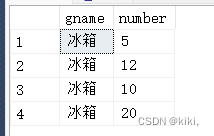
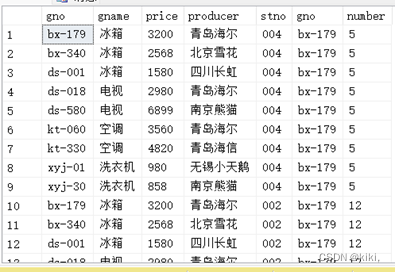
--1.select...from A,B的用法
--goods 9行4列
--invent 4行3列
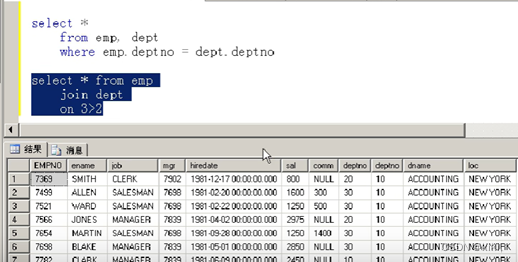
select * from goods,invent;
--36行7列
--2.select ... from A,B where ...的用法
select *
from goods , invent
where gname='冰箱';
--输出12行7列
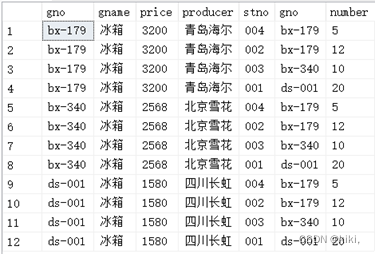
Where就是对产生的笛卡尔积的数据进行过滤
select "G".gname "商品名字", "I".number "商品数量"
from goods "G"
join invent "I" ---join是连接
on "G".gno= "I".gno --on表示连接条件on不能省,有join就必须有on
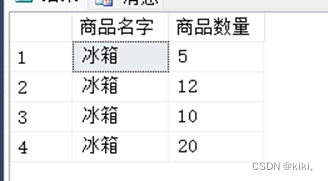
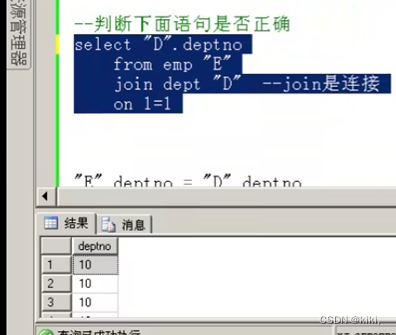
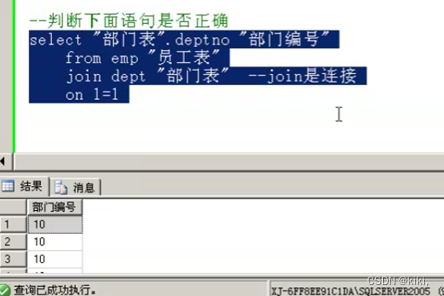
外部看起来不一样,但结果是一样的,推荐使用sql99标准使用join on
注意:select * from A,B where
A,B互换输出结果一样。
外连接
参考博客:数据库的内,外连接方式_猫耳苍苍的博客-CSDN博客_数据库外连接
定义:不但返回满足连接条件的所有记录,而且会返回部分不满足条件的记录
分为:左外连接和右外连接
左外连接是在两表进行自然连接,只把左表要舍弃的保留在结果集中
右外连接是在两表进行自然连接,只把右表要舍弃的保留在结果集中
“内连接可以看做是取两个表的交集 ,其中只有两条互相对应着的数据才能被存入结果表中”
完全连接
交叉连接
自连接
Select …… from 表1 naturl join 表2
自然连接是一种特殊的等值连接,他要求两个关系表中进行比较的必须是相同的属性列,无须添加连接条件,并且在结果中消除重复的属性列
联合
未学习完~~持续更新中
















 1262
1262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











