







 超级会员免费看
超级会员免费看
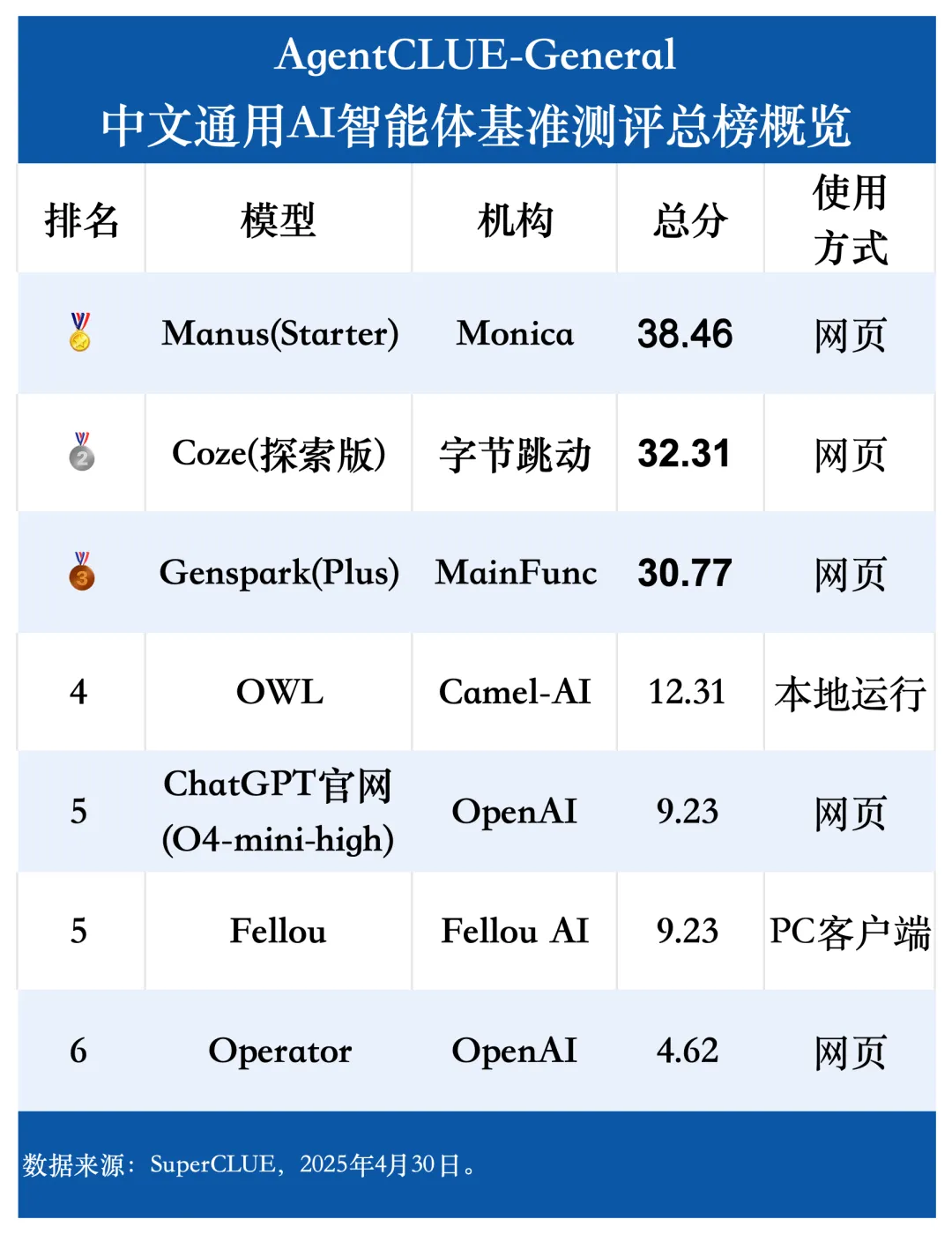
写在前面
大型语言模型 (LLM) 驱动的 Agent(智能体)正以前所未有的速度从学术研究走向大众视野,它们被寄予厚望,能够自主理解复杂指令、规划并执行多步骤任务、甚至调用多种工具与真实世界交互。然而,正如 RUC AI Box 团队和 SuperCLUE 等评估机构所指出的,当前 Agent 的发展面临着一个核心挑战:如何科学、客观、可复现地评估其“通用智能”水平?
许多 Agent 的演示令人印象深刻,但在实际应用中却可能“水土不服”,表现参差不齐。这种评估的“模糊性”不仅阻碍了技术的健康迭代,也让用户和开发者难以清晰地认识不同 Agent 产品的真实能力边界和适用场景。
为了解决这一痛点,SuperCLUE 团队推出的 AgentCLUE-General 这样的中文通用 AI 智能体测评基准应运而生。它试图建立一个可衡量、可比较的框架,来评估 Agent 在中文应用场景下的真实能力。
本文将结合 AgentCLUE-General 的测评思路和您提供的文章内容,深入探讨:
- 通用 Agent 评估的核心挑战与必要性。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 358
358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











