




FutureHouse_ether0
文章主要介绍了一个名为ether0的24B语言模型,该模型专注于推理和输出分子结构(以SMILES格式表示),并具有一定的化学相关任务处理能力。
一、模型概述
ether0模型源自对Mistral-Small-24B-Instruct-2501的微调和强化学习训练。它能够处理多种化学相关任务,但并非通用聊天模型。模型支持以SMILES格式输入分子,也具备一定程度的IUPAC名称处理能力。
二、使用场景
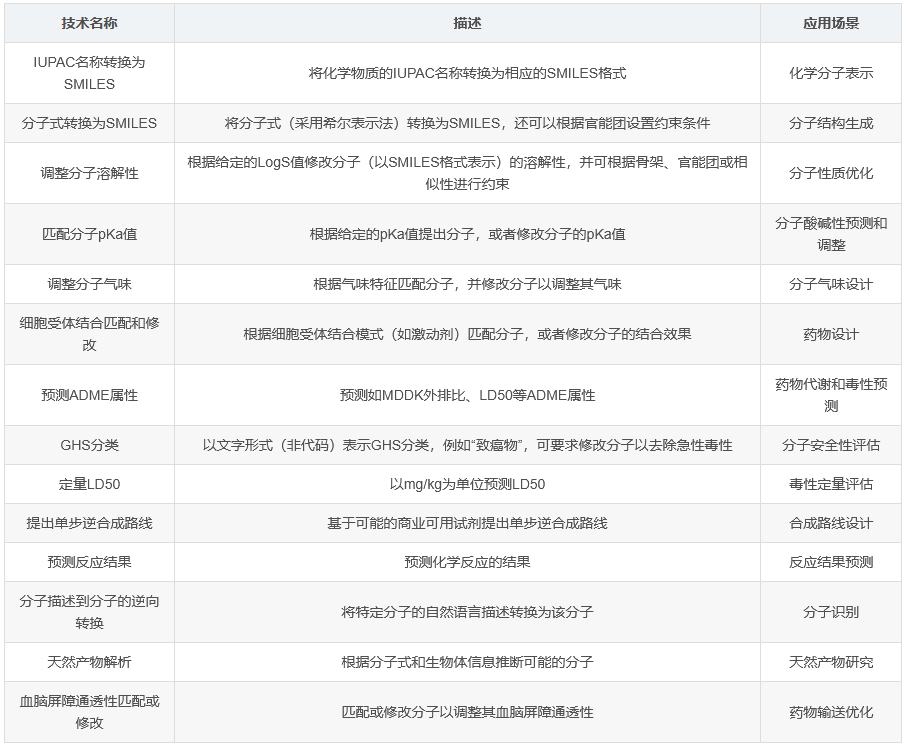
ether0模型适用于以下多种化学相关任务:
-
IUPAC名称转换为SMILES:将化学物质的IUPAC名称转换为相应的SMILES格式。
-
分子式转换为SMILES:将分子式(采用希尔表示法)转换为SMILES,还可以根据官能团设置约束条件。
-
调整分子溶解性:根据给定的LogS值修改分子(以SMILES格式表示)的溶解性,并可根据骨架、官能团或相似性进行约束。
-
匹配分子pKa值:根据给定的pKa值提出分子,或者修改分子的pKa值。
-
调整分子气味:根据气味特征匹配分子,并修改分子以调整其气味。
-
细胞受体结合匹配和修改:根据细胞受体结合模式(如激动剂)匹配分子,或者修改分子的结合效果。
-
预测ADME属性:如MDDK外排比、LD50等。
-
GHS分类:以文字形式(非代码)表示,例如“致癌物”,可要求修改分子以去除急性毒性。
-
定量LD50:以mg/kg为单位。
-
提出单步逆合成路线:基于可能的商业可用试剂。
-
预测反应结果。
-
分子描述到分子的逆向转换:将特定分子的自然语言描述转换为该分子。
-
天然产物解析:根据分子式和生物体信息推断可能的分子。
-
血脑屏障通透性匹配或修改。
需要注意的是,模型在处理超出其特定任务范围的问题时可能会失败,并且无法回答如“CCCCC(O)=OH的pKa是多少?”此类问题。此外,虽然可以组合属性进行任务,但尚未显著评估其效果。
三、模型局限性
ether0模型存在以下局限性:
-
通用知识不足:模型不掌握通用同义词,并且在教科书知识方面表现不佳,例如在chembench上的表现并不突出。
-
命名准确性问题:如果以常见名称输入分子,模型可能会使用错误的SMILES进行推理,导致结果不准确。例如,在使用常见名称提问时,模型容易将赖氨酸和谷氨酸混淆,但如果提供SMILES格式的结构,模型能够正确推理其化学性质。
四、训练细节
ether0模型的训练过程包括以下几个关键步骤:
-
预训练:基于DeepSeek r1的大部分错误推理痕迹对Mistral-Small-24B-Instruct-2501进行预训练,以激发推理能力并遵循新的标记/模板。
-
专家模型训练:针对上述任务之一,使用GRPO和可验证奖励独立训练专家模型。
-
推理痕迹聚合与过滤:从专家模型中收集并过滤出正确的推理痕迹(包含正确答案和推理过程),再次用于微调Mistral-Small-24B-Instruct-2501。
-
全面任务GRPO:在所有任务上进行GRPO训练。
-
安全后训练:对模型进行安全后训练,包括拒绝OPCW计划1和2中列出的化合物,以及拒绝有关制造炸药或毒药等恶意话题的问题。
训练过程中的技术细节和数据信息可参考文章的预印本。
五、安全特性
ether0模型在安全性方面进行了专门的训练:
-
拒绝敏感化合物:对OPCW计划1和2中列出的化合物进行拒绝后训练。
-
拒绝恶意话题:对有关制造炸药或毒药等标准恶意话题的问题进行拒绝后训练。
-
毒性调节能力:由于模型掌握药代动力学知识,可以调节毒性,但有毒或成瘾性化合物的结构通常是已知的,因此不视为安全风险。
-
无提升的“隐性知识”任务:在净化、放大或处理等“隐性知识”任务上,模型无法提供超出网络搜索或类似规模语言模型的信息。
综上所述,ether0模型是一个专注于化学分子结构处理和相关属性预测的大型语言模型,具备多种特定任务的处理能力,但在通用知识和某些特定场景下存在局限性。其训练过程经过精心设计,以确保模型在化学领域的准确性和安全性。


















 1203
1203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











