






一、YOLOv8 简介
YOLOv8 (“You Only Look Once” v8) 是 YOLO 系列模型的最新版本,由 Ultralytics 团队开发。作为一种一阶步目标检测网络,YOLOv8 具备速度快、精度高的特点,充分发挥在目标检测、实例分割、姿态估计和旋转目标检测等多个领域。
YOLOv8 具备易于使用的命令行界面和丰富的 API 接口,可以完编适配于各种实际场景,包括转播视频分析、安全监控、旅游相片分析等。
二、YOLOv8 与其他版本的区别
YOLOv8 在继承前代模型优点的基础上,在多个方面做出了重大优化:
- 模型结构优化:提供更深层的注意功能,使用更高效的跨阶段泛量连接 (CSP) 和并行跨二维注意功能图 (PAFPN) 等模块。
- 训练流程改进:增强了自选均值样本和光流变换等数据增强手段,改善模型治疗化和改善二次泛量选择算法,提升模型激活出给多样化场景的能力。
- 使用容易性:完全适配于 Ultralytics HUB 和自定义优化算法,提供高效计算方案。
目前,已经有众多实际场景实践了 YOLOv8,如安全监控中的行为识别,自动驾驶中的目标路径预测,以及人脸识别中的等级别判断等。
三、YOLOv8 开发环境搭建
1. 硬件环境要求
在进行 YOLOv8 实验和应用时,需要配备相应的硬件环境:
- 操作系统:Windows 10 64 位 或 Linux Ubuntu 18.04+
- 处理器 (CPU):Intel i7 或更高配置
- 内存:16GB 或以上
- 显卡 (GPU):NVIDIA GTX 1080 Ti 或更高配置,最好支持 CUDA 11.3+
如果需要扩大模型训练能力,可考虑使用 RTX 3090/4090 等高级显卡,可能大幅度提升动态性能。
四、YOLOv8 主要功能概述
YOLOv8 提供了一系列强大的功能,涵盖多个计算机视觉任务:
- 目标检测(Detect):YOLOv8 能够快速准确地检测图像中的多个目标。
- 图像分割(Segment):YOLOv8 可以对图像进行像素级的分割,适用于需要精确定位目标边界的场景。
- 姿态估计(Pose):YOLOv8 能够识别并估计图像中人物的姿态,这对于动作识别和人机交互等应用非常有用。
- 旋转目标检测(OBB):YOLOv8 支持 OBB 检测,能够更准确地检测具有旋转角度的目标。
五、YOLOv8 导出与预测
1. 导出模型
YOLOv8 支持将模型导出为 ONNX 格式,使其可以在不同的平台上运行。以下是一个简单的导出命令示例:
yolo export model=yolov8s-obb.pt format=onnx
这条命令将 YOLOv8 的 OBB 检测模型导出为 ONNX 格式,方便后续的部署和应用。
2. 进行模型预测
YOLOv8 还支持对图像进行预测,用户可以通过以下命令对指定图像进行预测:
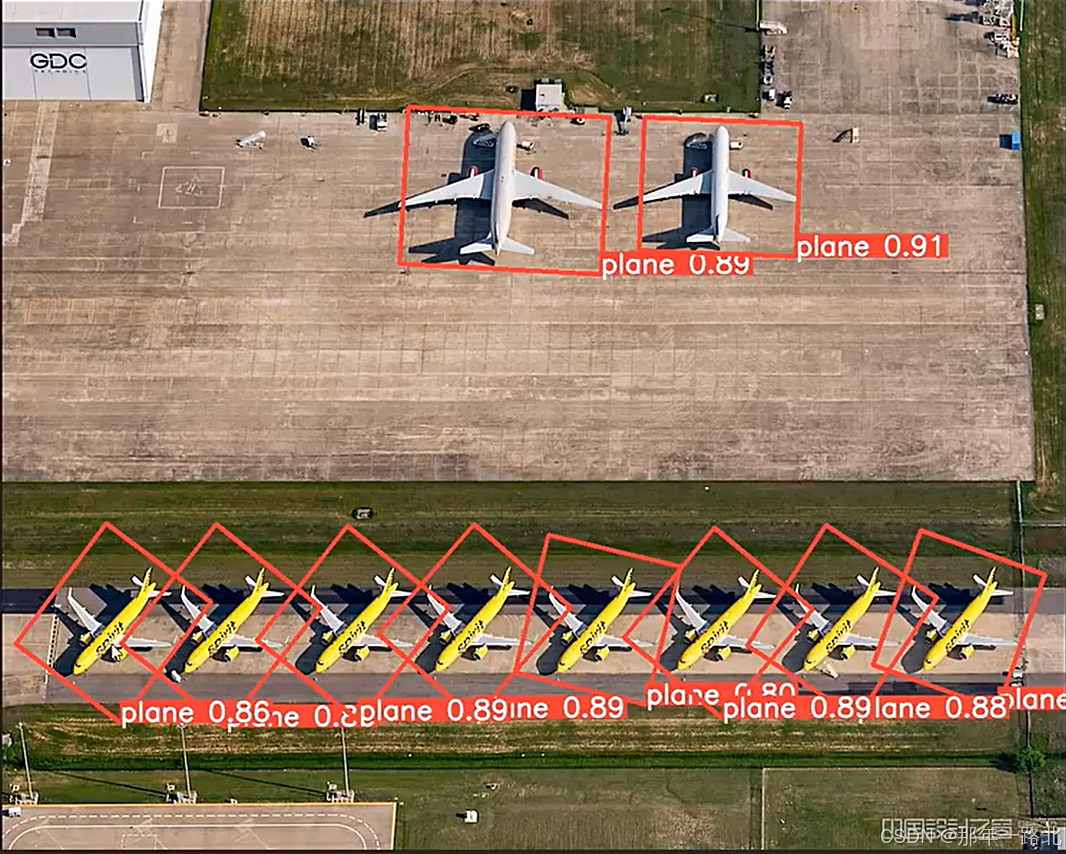
yolo obb predict model=yolov8n-obb.pt source=plane_03.jpg
这条命令使用 YOLOv8 的 OBB 检测模型对 plane_03.jpg 图像进行预测,输出检测结果。
六、YOLOv8 不同精度模型解析
YOLOv8 提供了不同精度的模型版本,以满足不同应用场景的需求。这些模型在参数数量和推理速度上有所不同,用户可以根据具体需求选择合适的模型版本。
1. 参数数量与精度
不同 YOLO 版本在参数数量和精度(COCO mAPval)上的表现如下:
| 模型 | 参数数量 | COCO mAP |
|---|---|---|
| YOLOv8n | 3.2M | 37.5 |
| YOLOv8s | 11.2M | 44.8 |
| YOLOv8m | 25.9M | 50.2 |
| YOLOv8l | 43.7M | 53.5 |
| YOLOv8x | 68.2M | 55.1 |
从表中可以看出,YOLOv8 在参数数量较少的情况下,仍然能够达到较高的精度,表明其在模型优化方面取得了显著进步。
2. 推理速度与精度
不同 YOLO 版本在推理速度(Latency A100 TensorRT FP16)和精度(COCO mAP50-95)上的表现如下:
| 模型 | 延迟 (ms) | COCO mAP |
|---|---|---|
| YOLOv8n | 1.2 | 37.5 |
| YOLOv8s | 1.9 | 44.8 |
| YOLOv8m | 2.8 | 50.2 |
| YOLOv8l | 4.3 | 53.5 |
| YOLOv8x | 6.0 | 55.1 |
模型精度对比:
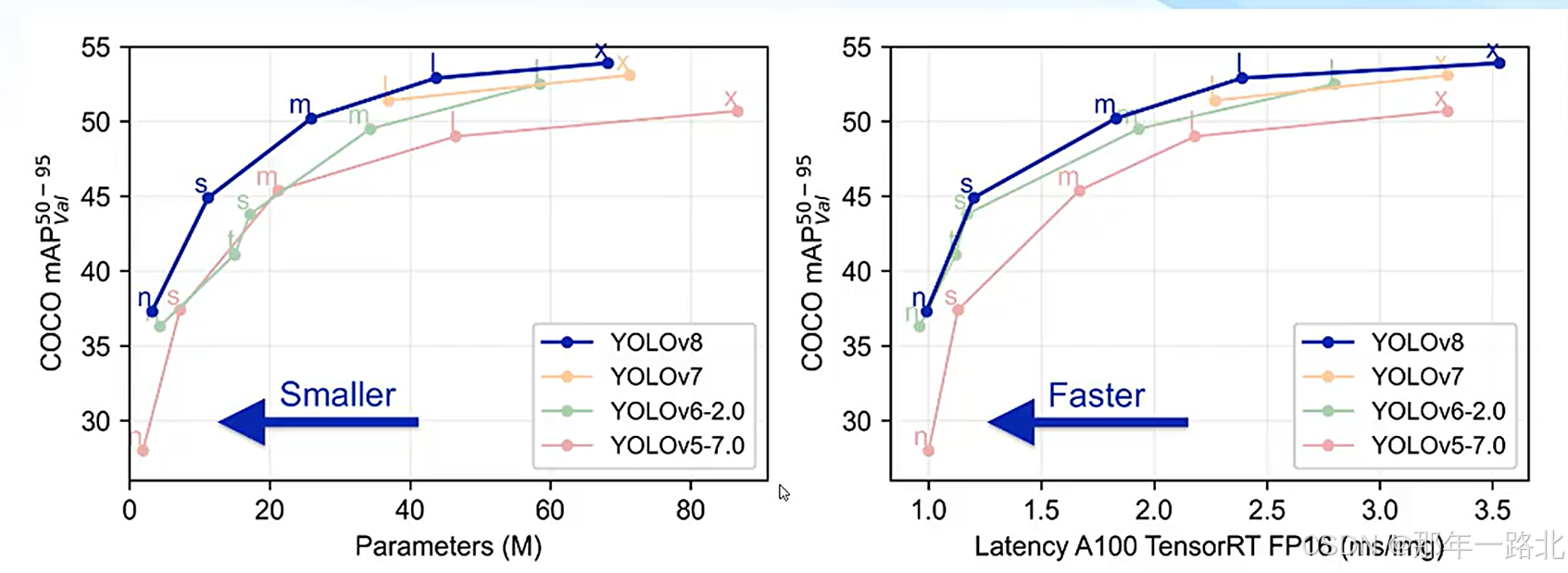
YOLOv8 在保持较高精度的同时,推理速度也得到了显著提升,使得其在实时应用中更具优势。
我使用YOLOV8s这个模型在自定义数据集上完成了实验,训练了15个epoch,mAP达到了90.66%,实验结果如图所示:
七、总结
YOLOv8 作为 YOLO 系列的最新版本,在目标检测、图像分割、姿态估计和 OBB 检测等方面表现出色。通过导出 ONNX 格式模型和可视化工具,YOLOv8 提高了模型的可移植性和易用性。不同精度的模型版本满足了不同应用场景的需求,使得 YOLOv8 在实时应用中更具优势。熟练掌握模型预测和导出命令,可以帮助用户更好地应用 YOLOv8 进行目标检测和分析。
本文详细介绍了 YOLOv8 模型及其导出方法。随着深度学习技术的不断发展,YOLOv8 将在更多领域发挥重要作用,推动目标检测技术的进步,感谢观看。


















 3318
3318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









