






本科论文超星学习通一次免费查重机会
用户登录 (dayainfo.com) https://user.dayainfo.com/show/login <<----登录入口
https://user.dayainfo.com/show/login <<----登录入口
学信网还有一次免费机会https://blog.csdn.net/weixin_52763107/article/details/138000677?spm=1001.2014.3001.5501学信网还有一次免费查重机会,别浪费
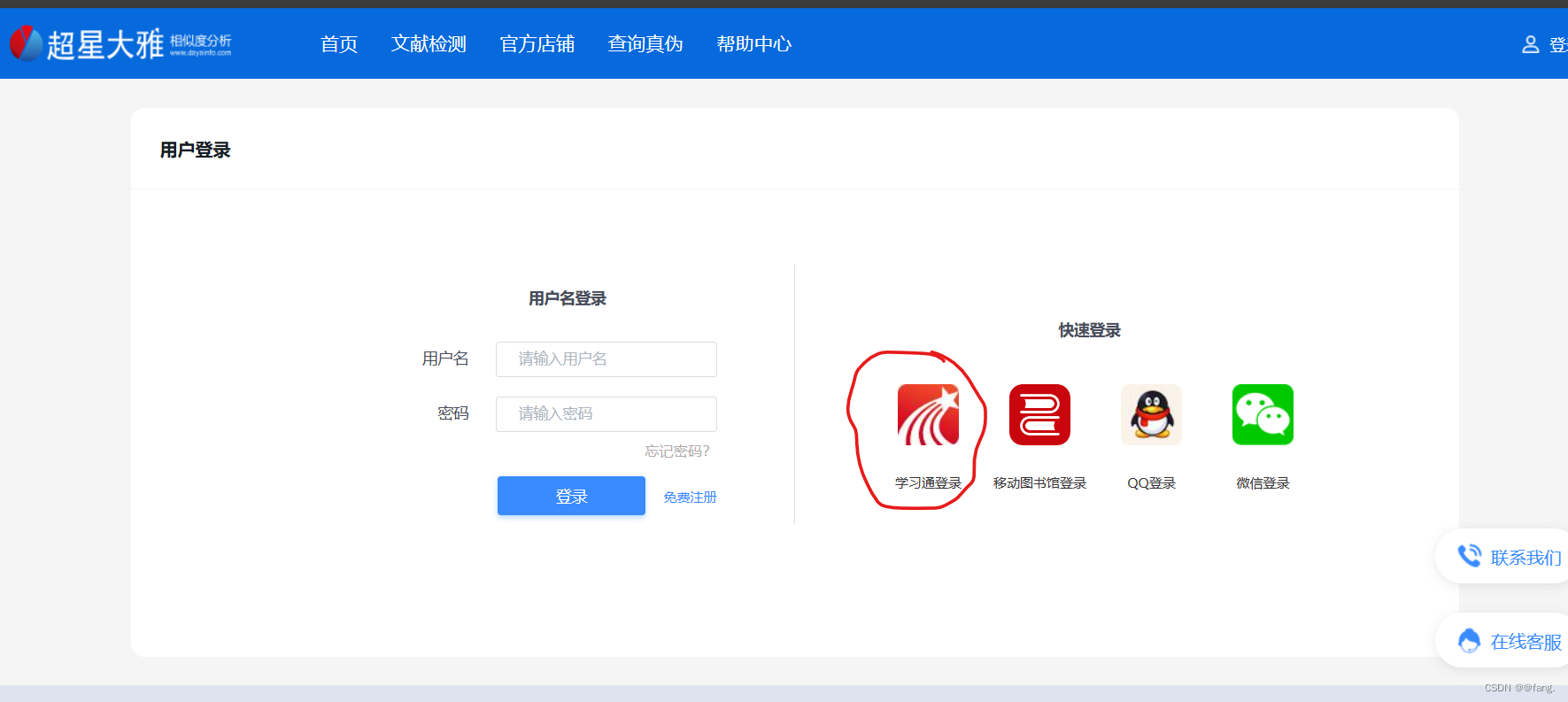
1.学习通登录
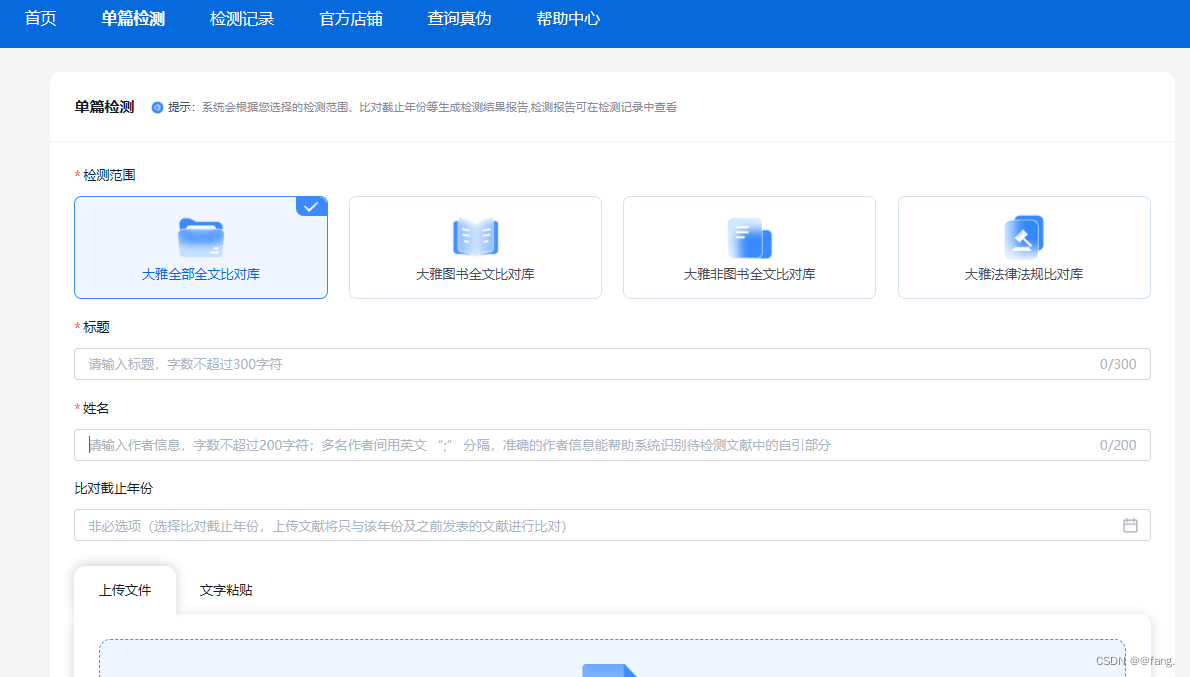
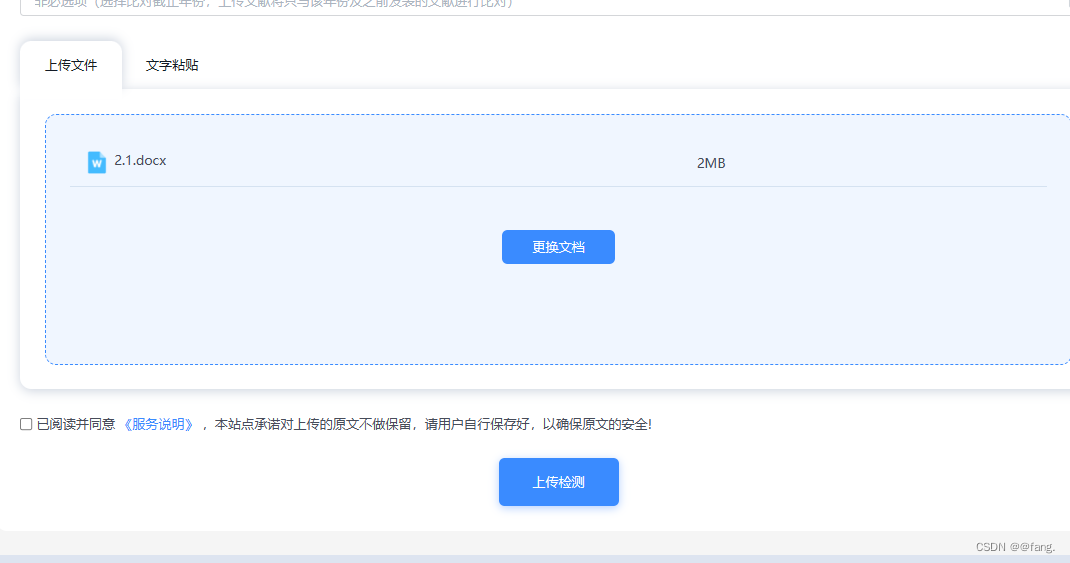
2.填写必填选项,上传检测
3.坐等出结果(几分钟)
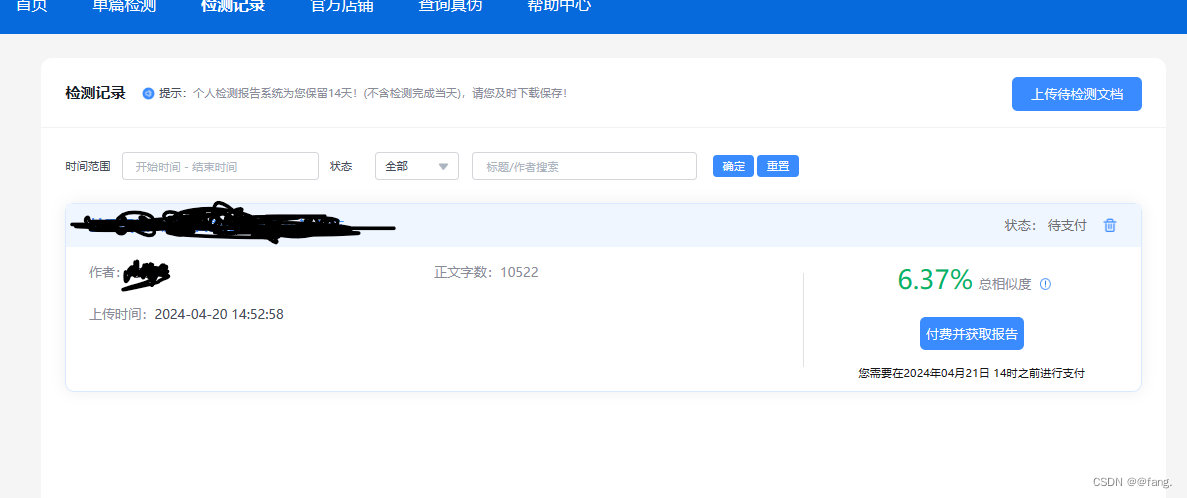
只能作为参考,还是要以学校的为准。
只做分享,与学校网站相差太大勿喷(想喷别用,用了别喷,免费的),谢谢家人们。。


















 1493
1493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











