







 该博客介绍了如何利用无监督原子表示学习(MG-BERT)来预测分子性质,主要涉及在分子图上应用BERT模型进行预训练。文章详细解析了模型结构、数据处理、模型训练和验证过程,包括分层采样、数据集构建、模型搭建、权重加载等步骤,并展示了分类和回归任务的实现。
该博客介绍了如何利用无监督原子表示学习(MG-BERT)来预测分子性质,主要涉及在分子图上应用BERT模型进行预训练。文章详细解析了模型结构、数据处理、模型训练和验证过程,包括分层采样、数据集构建、模型搭建、权重加载等步骤,并展示了分类和回归任务的实现。
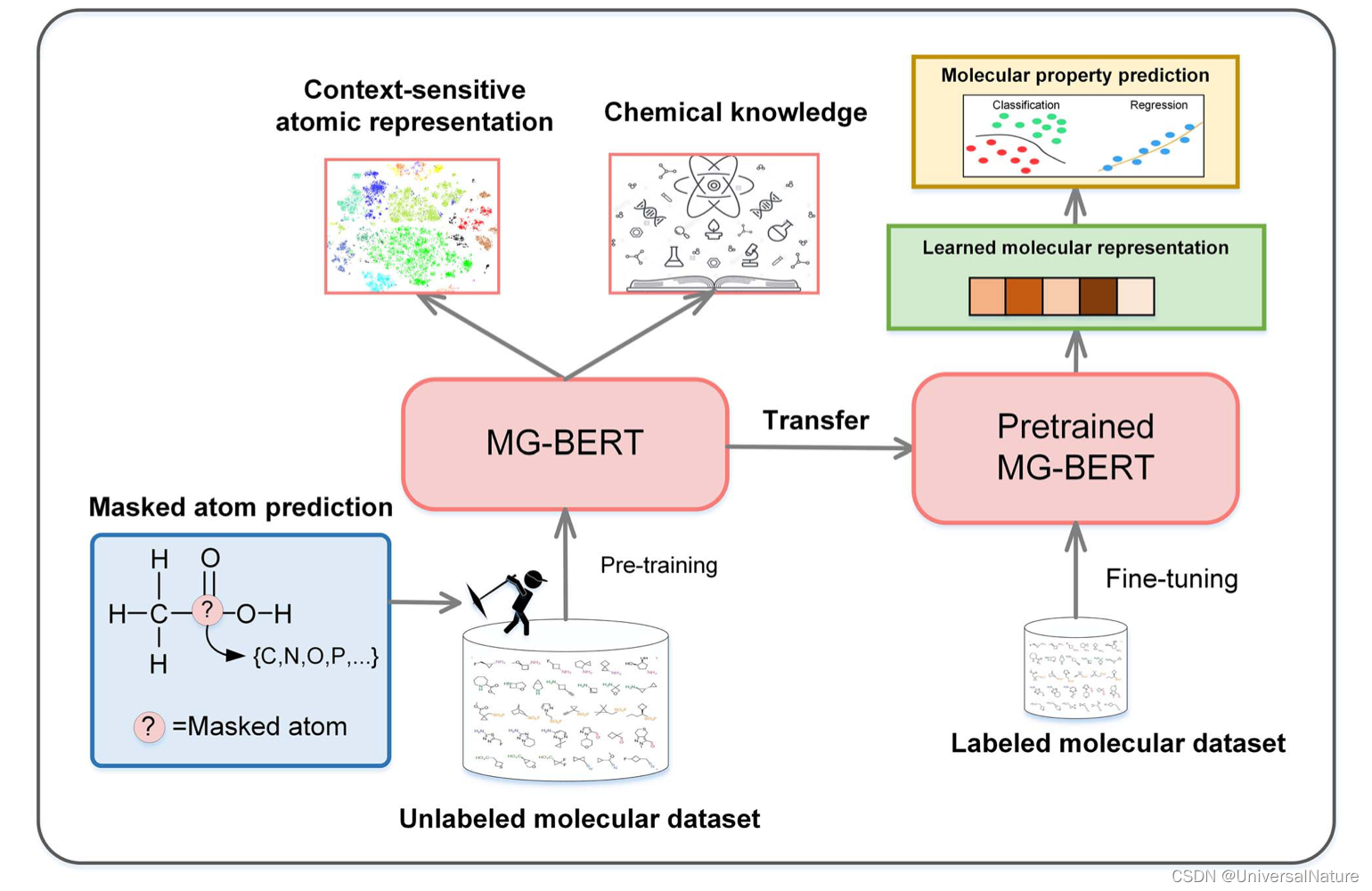
基于分子图的 BERT 模型,原文:MG-BERT: leveraging unsupervised atomic representation learning for molecular property prediction,原文解析:MG-BERT | 利用 无监督 原子表示学习 预测分子性质 | 在分子图上应用BERT | GNN | 无监督学习(掩蔽原子预训练) | attention,代码:Molecular-graph-BERT,其中缺少的数据以logD7.4例,与上一篇文章处理类似,可以删除 Index 列。代码解析从 pretrain 开始,模型整体框架如下:
1.classification
1.1.run
os.environ["TF_FORCE_GPU_ALLOW_GROWTH"] = "true"
keras.backend.clear_session()
os.environ['CUDA_VISIBLE_DEVICES'] = "0"
if __name__ == '__main__':
auc_list = []
for seed in [7,17,27,37,47,57,67,77,87,97]:
print(seed)
auc = main(seed)
auc_list.append(auc)
print(auc_list)
- 给定全局随机种子,收集测试准确度后输出
1.2.main
def main(seed):
# tasks = ['Ames', 'BBB', 'FDAMDD', 'H_HT', 'Pgp_inh', 'Pgp_sub']
# os.environ['CUDA_VISIBLE_DEVICES'] = "1"
# tasks = ['BBB', 'FDAMDD', 'Pgp_sub']
task = 'FDAMDD'
print(task)
small = {'name':'Small','num_layers': 3, 'num_heads': 2, 'd_model': 128,'path':'small_weights','addH':True}
medium = {'name':'Medium','num_layers': 6, 'num_heads': 8, 'd_model': 256,'path':'medium_weights','addH':True}
large = {'name':'Large','num_layers': 12, 'num_heads': 12, 'd_model': 512,'path':'large_weights','addH':True}
arch = medium ## small 3 4 128 medium: 6 6 256 large: 12 8 516
pretraining = True
pretraining_str = 'pretraining' if pretraining else ''
trained_epoch = 10
num_layers = arch['num_layers']
num_heads = arch['num_heads']
d_model = arch['d_model']
addH = arch['addH']
dff = d_model * 2
vocab_size = 17
dropout_rate = 0.1
seed = seed
np.random.seed(seed=seed)
tf.random.set_seed(seed=seed)
- 设置参数和随机种子,选定测试任务
train_dataset, test_dataset , val_dataset = Graph_Classification_Dataset('data/clf/{}.csv'.format(task), smiles_field='SMILES',
label_field='Label',addH=True).get_data()
- 构建训练集,测试集和验证集
1.2.1.Graph_Classification_Dataset
class Graph_Classification_Dataset(object):
def __init__(self,path,smiles_field='Smiles',label_field='Label',max_len=100,addH=True):
if path.endswith('.txt') or path.endswith('.tsv'):
self.df = pd.read_csv(path,sep='\t')
else:
self.df = pd.read_csv(path)
self.smiles_field = smiles_field
self.label_field = label_field
self.vocab = str2num
self.devocab = num2str
self.df = self.df[self.df[smiles_field].str.len() <= max_len]
self.addH = addH
- 相较 Graph_Bert_Dataset 多了 label 和 太长 smiles 的处理,默认是 100
1.2.1.1.get_data
def get_data(self):
data = self.df
data = data.dropna()
data[self.label_field] = data[self.label_field].map(int)
pdata = data[data[self.label_field] == 1]
ndata = data[data[self.label_field] == 0]
lengths = [0, 25, 50, 75, 100]
ptrain_idx = []
for i in range(4):
idx = pdata[(pdata[self.smiles_field].str.len() >= lengths[i]) & (
pdata[self.smiles_field].str.len() < lengths[i + 1])].sample(frac=0.8).index
ptrain_idx.extend(idx)
ntrain_idx = []
for i in range(4):
idx = ndata[(ndata[self.smiles_field].str.len() >= lengths[i]) & (
ndata[self.smiles_field].str.len() < lengths[i + 1])].sample(frac=0.8).index
ntrain_idx.extend(idx)
train_data = data[data.index.isin(ptrain_idx+ntrain_idx)]
pdata = pdata[~pdata.index.isin(ptrain_idx)]
ndata = ndata[~ndata.index.isin(ntrain_idx)]
ptest_idx = []
for i in range(4):
idx = pdata[(pdata[self.smiles_field].str.len() >= lengths[i]) & (
pdata[self.smiles_field].str.len() < lengths[i + 1])].sample(frac=0.5).index
ptest_idx.extend(idx)
ntest_idx = []
for i in range(4):
idx = ndata[(ndata[self.smiles_field].str.len() >= lengths[i]) & (
ndata[self.smiles_field].str.len() < lengths[i + 1])].sample(frac=0.5).index
ntest_idx.extend(idx)
test_data = data[data.index.isin(ptest_idx+ntest_idx)]
val_data = data[~data.index.isin(ptest_idx+ntest_idx+ptrain_idx+ntrain_idx)]
self.dataset1 = tf.data.Dataset.from_tensor_slices(
(train_data[self.smiles_field], train_data[self.label_field]))
self.dataset1 = self.dataset1.map(self.tf_numerical_smiles).cache().padded_batch(32, padded_shapes=(
tf.TensorShape([None]), tf.TensorShape([None, None]), tf.TensorShape([1]))).shuffle(100).prefetch(100)
self.dataset2 = tf.data.Dataset.from_tensor_slices((test_data[self.smiles_field], test_data[self.label_field]))
self.dataset2 = self.dataset2.map(self.tf_numerical_smiles).padded_batch(512, padded_shapes=(
tf.TensorShape([None]), tf.TensorShape([None, None]), tf.TensorShape([1]))).cache().prefetch(100)
self.dataset3 = tf.data.Dataset.from_tensor_slices((val_data[self.smiles_field], val_data[self.label_field]))
self.dataset3 = self.dataset3.map(self.tf_numerical_smiles).padded_batch(512, padded_shapes=(
tf.TensorShape([None]), tf.TensorShape([None, None]), tf.TensorShape([1]))).cache().prefetch(100)
return self.dataset1, self.dataset2, self.dataset3
-
pdata 和 ndata 是 positive data 和 negative data,标签分别是1和0
-
依据 smiles 的长度分层采样80%的正样本训练集和负样本训练集,合并后构建为 train_data
-
剩下的数据集一半是测试集,一半是验证集,同样按照 smiles 长度分层采样
-
将 dataframe 包装成 tf.data.dataset,经过 pad 和 指定 batch 后输出
1.2.1.2.tf_numerical_smiles
def tf_numerical_smiles(self, smiles,label):
x,adjoin_matrix,y = tf.py_function(self.numerical_smiles, [smiles,label], [tf.int64, tf.float32 ,tf.int64])
x.set_shape([None])
adjoin_matrix.set_shape([None,None])
y.set_shape([None])
return x, adjoin_matrix , y
- 相较 Graph_Bert_Dataset 少了处理标记列表
1.2.1.3.numerical_smiles
def numerical_smiles(self, smiles,label):
smiles = smiles.numpy().decode()
atoms_list, adjoin_matrix = smiles2adjoin(smiles,explicit_hydrogens=self.addH)
atoms_list = ['<global>'] + atoms_list
nums_list = [str2num.get(i,str2num['<unk>']) for i in atoms_list]
temp = np.ones((len(nums_list),len(nums_list)))
temp[1:, 1:] = adjoin_matrix
adjoin_matrix = (1-temp)*(-1e9)
x = np.array(nums_list).astype('int64')
y = np.array([label]).astype('int64')
return x, adjoin_matrix,y
- 得到 smiles 的原子列表,邻接矩阵,label 输出
1.2.2.PredictModel
x, adjoin_matrix, y = next(iter(train_dataset.take(1)))
seq = tf.cast(tf.math.equal(x, 0), tf.float32)
mask = seq[:, tf.newaxis, tf.newaxis, :]
model = PredictModel(num_layers=num_layers, d_model=d_model, dff=dff, num_heads=num_heads, vocab_size=vocab_size,dense_dropout=0.5)
class PredictModel(tf.keras.Model):
def __init__(self,num_layers = 6,d_model = 256,dff = 512,num_heads = 8,vocab_size =17,dropout_rate = 0.1,dense_dropout=0.1):
super(PredictModel, self).__init__()
self.encoder = Encoder(num_layers=num_layers,d_model=d_model, num_heads=num_heads,dff=dff,input_vocab_size=vocab_size,maximum_position_encoding=200,rate=dropout_rate)
self.fc1 = tf.keras.layers.Dense(256,activation=tf.keras.layers.LeakyReLU(0.1))
self.dropout = tf.keras.layers.Dropout(dense_dropout)
self.fc2 = tf.keras.layers.Dense(1)
def call(self,x,adjoin_matrix,mask,training=False):
x = self.encoder(x,training=training,mask=mask,adjoin_matrix=adjoin_matrix)
x = x[:,0,:]
x = self.fc1(x)
x = self.dropout(x,training=training)
x = self.fc2(x)
return x
-
mask 和 encoder 与 BertModel 中的一致,后续的全连接层需要训练,最后输出标量 label 是预测值
-
x 经过 encode 后,输出是 (batch_size, input_seq_len, d_model) ,x[:,0,:] 取出了每个 smiles 中的第一个值作为表征,即超节点
1.2.3.load_weight
if pretraining:
temp = BertModel(num_layers=num_layers, d_model=d_model, dff=dff, num_heads=num_heads, vocab_size=vocab_size)
pred = temp(x, mask=mask, training=True, adjoin_matrix=adjoin_matrix)
temp.load_weights(arch['path']+'/bert_weights{}_{}.h5'.format(arch['name'],trained_epoch))
temp.encoder.save_weights(arch['path']+'/bert_weights_encoder{}_{}.h5'.format(arch['name'],trained_epoch))
del temp
pred = model(x,mask=mask,training=True,adjoin_matrix=adjoin_matrix)
model.encoder.load_weights(arch['path']+'/bert_weights_encoder{}_{}.h5'.format(arch['name'],trained_epoch))
print('load_wieghts')
- 加载预训练好的 encoder 参数
1.2.4.train
optimizer = tf.keras.optimizers.Adam(learning_rate=5e-5)
auc= -10
stopping_monitor = 0
for epoch in range(100):
accuracy_object = tf.keras.metrics.BinaryAccuracy()
loss_object = tf.keras.losses.BinaryCrossentropy(from_logits=True)
for x,adjoin_matrix,y in train_dataset:
with tf.GradientTape() as tape:
seq = tf.cast(tf.math.equal(x, 0), tf.float32)
mask = seq[:, tf.newaxis, tf.newaxis, :]
preds = model(x,mask=mask,training=True,adjoin_matrix=adjoin_matrix)
loss = loss_object(y,preds)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
accuracy_object.update_state(y,preds)
print('epoch: ',epoch,'loss: {:.4f}'.format(loss.numpy().item()),'accuracy: {:.4f}'.format(accuracy_object.result().numpy().item()))
- 训练 model 的时候指定 training=True,实际将整个模型参数都进行了训练,而没有冻结 encoder 参数
1.2.5.validation
y_true = []
y_preds = []
for x, adjoin_matrix, y in val_dataset:
seq = tf.cast(tf.math.equal(x, 0), tf.float32)
mask = seq[:, tf.newaxis, tf.newaxis, :]
preds = model(x,mask=mask,adjoin_matrix=adjoin_matrix,training=False)
y_true.append(y.numpy())
y_preds.append(preds.numpy())
y_true = np.concatenate(y_true,axis=0).reshape(-1)
y_preds = np.concatenate(y_preds,axis=0).reshape(-1)
y_preds = tf.sigmoid(y_preds).numpy()
auc_new = roc_auc_score(y_true,y_preds)
val_accuracy = keras.metrics.binary_accuracy(y_true.reshape(-1), y_preds.reshape(-1)).numpy()
print('val auc:{:.4f}'.format(auc_new), 'val accuracy:{:.4f}'.format(val_accuracy))
if auc_new > auc:
auc = auc_new
stopping_monitor = 0
np.save('{}/{}{}{}{}{}'.format(arch['path'], task, seed, arch['name'], trained_epoch, trained_epoch,pretraining_str),
[y_true, y_preds])
model.save_weights('classification_weights/{}_{}.h5'.format(task,seed))
print('save model weights')
else:
stopping_monitor += 1
print('best val auc: {:.4f}'.format(auc))
if stopping_monitor>0:
print('stopping_monitor:',stopping_monitor)
if stopping_monitor>20:
break
- 当验证阶段准确度低于上次测试20次后停止,否则保存最优参数
1.2.6.test
y_true = []
y_preds = []
model.load_weights('classification_weights/{}_{}.h5'.format(task, seed))
for x, adjoin_matrix, y in test_dataset:
seq = tf.cast(tf.math.equal(x, 0), tf.float32)
mask = seq[:, tf.newaxis, tf.newaxis, :]
preds = model(x, mask=mask, adjoin_matrix=adjoin_matrix, training=False)
y_true.append(y.numpy())
y_preds.append(preds.numpy())
y_true = np.concatenate(y_true, axis=0).reshape(-1)
y_preds = np.concatenate(y_preds, axis=0).reshape(-1)
y_preds = tf.sigmoid(y_preds).numpy()
test_auc = roc_auc_score(y_true, y_preds)
test_accuracy = keras.metrics.binary_accuracy(y_true.reshape(-1), y_preds.reshape(-1)).numpy()
print('test auc:{:.4f}'.format(test_auc), 'test accuracy:{:.4f}'.format(test_accuracy))
return test_auc
- 加载参数,计算 test 准确度,评估模型
2.regression
2.1.run
os.environ["TF_FORCE_GPU_ALLOW_GROWTH"] = "true"
if __name__ == "__main__":
r2_list = []
for seed in [7,17,27,37,47]:
print(seed)
r2 = main(seed)
r2_list.append(r2)
print(r2_list)
- 给定随机种子,保持结果,官网解释os.environ[“TF_FORCE_GPU_ALLOW_GROWTH”] = “true”
2.2.main
def main(seed):
# tasks = ['caco2', 'logD', 'logS', 'PPB', 'tox']
# os.environ['CUDA_VISIBLE_DEVICES'] = "1"
keras.backend.clear_session()
os.environ['CUDA_VISIBLE_DEVICES'] = "0"
small = {'name': 'Small', 'num_layers': 3, 'num_heads': 4, 'd_model': 128, 'path': 'small_weights','addH':True}
medium = {'name': 'Medium', 'num_layers': 6, 'num_heads': 8, 'd_model': 256, 'path': 'medium_weights','addH':True}
medium2 = {'name': 'Medium', 'num_layers': 6, 'num_heads': 8, 'd_model': 256, 'path': 'medium_weights2',
'addH': True}
large = {'name': 'Large', 'num_layers': 12, 'num_heads': 12, 'd_model': 576, 'path': 'large_weights','addH':True}
medium_without_H = {'name': 'Medium', 'num_layers': 6, 'num_heads': 8, 'd_model': 256, 'path': 'weights_without_H','addH':False}
medium_without_pretrain = {'name': 'Medium', 'num_layers': 6, 'num_heads': 8, 'd_model': 256,'path': 'medium_without_pretraining_weights','addH':True}
arch = medium ## small 3 4 128 medium: 6 6 256 large: 12 8 516
pretraining = True
pretraining_str = 'pretraining' if pretraining else ''
trained_epoch = 10
task = 'PPB'
print(task)
seed = seed
num_layers = arch['num_layers']
num_heads = arch['num_heads']
d_model = arch['d_model']
addH = arch['addH']
dff = d_model * 2
vocab_size = 17
dropout_rate = 0.1
tf.random.set_seed(seed=seed)
- keras.backend.clear_session()避免内存问题,
- 模型配置选择medium,任务是预测 plasma protein binding (PPB)
graph_dataset = Graph_Regression_Dataset('data/reg/{}.txt'.format(task), smiles_field='SMILES',
label_field='Label',addH=addH)
train_dataset, test_dataset,val_dataset = graph_dataset.get_data()
- 源码中构建 graph_dataset 应该多加了 .get_data()
2.2.1.Graph_Regression_Dataset
class Graph_Regression_Dataset(object):
def __init__(self,path,smiles_field='Smiles',label_field='Label',normalize=True,max_len=100,addH=True):
if path.endswith('.txt') or path.endswith('.tsv'):
self.df = pd.read_csv(path,sep='\t')
else:
self.df = pd.read_csv(path)
self.smiles_field = smiles_field
self.label_field = label_field
self.vocab = str2num
self.devocab = num2str
self.df = self.df[self.df[smiles_field].str.len()<=max_len]
self.addH = addH
if normalize:
self.max = self.df[self.label_field].max()
self.min = self.df[self.label_field].min()
self.df[self.label_field] = (self.df[self.label_field]-self.min)/(self.max-self.min)-0.5
self.value_range = self.max-self.min
- 相较 Graph_Classification_Dataset 多了对 label 的回归任务的归一化
2.2.1.1.get_data
def get_data(self):
data = self.df
lengths = [0, 25, 50, 75, 100]
train_idx = []
for i in range(4):
idx = data[(data[self.smiles_field].str.len() >= lengths[i]) & (
data[self.smiles_field].str.len() < lengths[i + 1])].sample(frac=0.8).index
train_idx.extend(idx)
train_data = data[data.index.isin(train_idx)]
data = data[~data.index.isin(train_idx)]
test_idx = []
for i in range(4):
idx = data[(data[self.smiles_field].str.len() >= lengths[i]) & (
data[self.smiles_field].str.len() < lengths[i + 1])].sample(frac=0.5).index
test_idx.extend(idx)
test_data = data[data.index.isin(test_idx)]
val_data = data[~data.index.isin(test_idx)]
self.dataset1 = tf.data.Dataset.from_tensor_slices((train_data[self.smiles_field], train_data[self.label_field]))
self.dataset1 = self.dataset1.map(self.tf_numerical_smiles).cache().padded_batch(64, padded_shapes=(
tf.TensorShape([None]), tf.TensorShape([None,None]),tf.TensorShape([1]))).shuffle(100).prefetch(100)
self.dataset2 = tf.data.Dataset.from_tensor_slices((test_data[self.smiles_field], test_data[self.label_field]))
self.dataset2 = self.dataset2.map(self.tf_numerical_smiles).padded_batch(512, padded_shapes=(
tf.TensorShape([None]),tf.TensorShape([None,None]), tf.TensorShape([1]))).cache().prefetch(100)
self.dataset3 = tf.data.Dataset.from_tensor_slices((val_data[self.smiles_field], val_data[self.label_field]))
self.dataset3 = self.dataset3.map(self.tf_numerical_smiles).padded_batch(512, padded_shapes=(
tf.TensorShape([None]), tf.TensorShape([None, None]), tf.TensorShape([1]))).cache().prefetch(100)
return self.dataset1,self.dataset2,self.dataset3
- 与 Graph_Classification_Dataset 中的处理基本一样
2.2.1.2.tf_numerical_smiles
def tf_numerical_smiles(self, smiles,label):
x,adjoin_matrix,y = tf.py_function(self.numerical_smiles, [smiles,label], [tf.int64, tf.float32 ,tf.int64])
x.set_shape([None])
adjoin_matrix.set_shape([None,None])
y.set_shape([None])
return x, adjoin_matrix , y
- tf.py_function把python函数包装成tf运算嵌入计算图中,参数是函数名,输入变量,返回值类型
2.2.1.3.numerical_smiles
def numerical_smiles(self, smiles,label):
smiles = smiles.numpy().decode()
atoms_list, adjoin_matrix = smiles2adjoin(smiles,explicit_hydrogens=self.addH)
atoms_list = ['<global>'] + atoms_list
nums_list = [str2num.get(i,str2num['<unk>']) for i in atoms_list]
temp = np.ones((len(nums_list),len(nums_list)))
temp[1:, 1:] = adjoin_matrix
adjoin_matrix = (1-temp)*(-1e9)
x = np.array(nums_list).astype('int64')
y = np.array([label]).astype('float32')
return x, adjoin_matrix,y
- 与 Graph_Classification_Dataset 中的处理基本一样
value_range = graph_dataset.value_range
x, adjoin_matrix, y = next(iter(train_dataset.take(1)))
seq = tf.cast(tf.math.equal(x, 0), tf.float32)
mask = seq[:, tf.newaxis, tf.newaxis, :]
- 源码中 graph_dataset.value_range() 要改成 graph_dataset.value_range,运行后结果如下
for (x, adjoin_matrix, y) in train_dataset.take(5):
seq = tf.cast(tf.math.equal(x, 0), tf.float32)
mask = seq[:, tf.newaxis, tf.newaxis, :]
print(x.shape)
print(adjoin_matrix.shape)
print(y.shape)
print(seq.shape)
print(mask.shape)
print('------------')
"""
(64, 85)
(64, 85, 85)
(64, 1)
(64, 85)
(64, 1, 1, 85)
------------
(64, 72)
(64, 72, 72)
(64, 1)
(64, 72)
(64, 1, 1, 72)
------------
(64, 64)
(64, 64, 64)
(64, 1)
(64, 64)
(64, 1, 1, 64)
------------
(64, 77)
(64, 77, 77)
(64, 1)
(64, 77)
(64, 1, 1, 77)
------------
(64, 88)
(64, 88, 88)
(64, 1)
(64, 88)
(64, 1, 1, 88)
------------
"""
- 每个 batch 中包括 64 个 smiles,这些 smiles 被 pad 至当前 batch 中最长长度
- mask 中表示 pad 的部分是1,正常原子是0
2.2.2.PredictModel
model = PredictModel(num_layers=num_layers, d_model=d_model, dff=dff, num_heads=num_heads, vocab_size=vocab_size, dense_dropout=0.15)
- 与 Graph_Classification_Dataset 中一样
2.2.3.load_weight
if pretraining:
temp = BertModel(num_layers=num_layers, d_model=d_model, dff=dff, num_heads=num_heads, vocab_size=vocab_size)
pred = temp(x, mask=mask, training=True, adjoin_matrix=adjoin_matrix)
temp.load_weights(arch['path']+'/bert_weights{}_{}.h5'.format(arch['name'],trained_epoch))
temp.encoder.save_weights(arch['path']+'/bert_weights_encoder{}_{}.h5'.format(arch['name'],trained_epoch))
del temp
pred = model(x, mask=mask, training=True, adjoin_matrix=adjoin_matrix)
model.encoder.load_weights(arch['path']+'/bert_weights_encoder{}_{}.h5'.format(arch['name'],trained_epoch))
print('load_wieghts')
- 加载预训练好的 encoder 参数
2.2.4.else
class CustomSchedule(tf.keras.optimizers.schedules.LearningRateSchedule):
def __init__(self, d_model, total_steps=4000):
super(CustomSchedule, self).__init__()
self.d_model = d_model
self.d_model = tf.cast(self.d_model, tf.float32)
self.total_step = total_steps
self.warmup_steps = total_steps*0.10
def __call__(self, step):
arg1 = step/self.warmup_steps
arg2 = 1-(step-self.warmup_steps)/(self.total_step-self.warmup_steps)
return 10e-5* tf.math.minimum(arg1, arg2)
steps_per_epoch = len(train_dataset)
learning_rate = CustomSchedule(128,100*steps_per_epoch)
optimizer = tf.keras.optimizers.Adam(learning_rate=10e-5)
r2 = -10
stopping_monitor = 0
for epoch in range(100):
mse_object = tf.keras.metrics.MeanSquaredError()
for x,adjoin_matrix,y in train_dataset:
with tf.GradientTape() as tape:
seq = tf.cast(tf.math.equal(x, 0), tf.float32)
mask = seq[:, tf.newaxis, tf.newaxis, :]
preds = model(x,mask=mask,training=True,adjoin_matrix=adjoin_matrix)
loss = tf.reduce_mean(tf.square(y-preds))
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
mse_object.update_state(y,preds)
print('epoch: ',epoch,'loss: {:.4f}'.format(loss.numpy().item()),'mse: {:.4f}'.format(mse_object.result().numpy().item() * (value_range**2)))
- 自定义了 LearningRateSchedule,但没有在 optimizers 中使用,其余部分与 Graph_Classification_Dataset 中基本一样


















 486
486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











