







机器学习和深度学习算法在学习过程中对某种类型的假设有归纳偏好,这种归纳偏好可以看作学习算法自身针对假设空间的“价值观”。奥卡姆剃刀原则要求若多个假设与观察一致,选最简单的那个,但哪个是“最简单”的假设需要不简单的判断。归纳偏好对应了学习算法本身做出的关于“什么样的模型更好”的假设,具体问题中算法的归纳偏好是否与问题本身匹配,大多数时候决定了算法能否取得好的性能。“没有免费的午餐”定理( N F L NFL NFL)说明任何一个学习算法都能找出一种场景使它的性能很低或很高,任何学习算法的期望性能都相同,这就使得针对具体问题采用合适的学习算法很关键。
归纳和演绎是自然科学的两大方法,归纳指的是从一些例子中寻找共性,形成一个能泛化到很多问题的通用规则,偏好是对模型的偏好。归纳产生模型空间,偏好约束到某个具体的模型
下面是深度学习的归纳偏置是什么?中提到的文章《Relational inductive biases, deep learning, and graph networks》的前两部分(了解之后补充其余的部分),第一个回答很优秀:
在深度学习时代,这种归纳性偏好更为明显。比如深度神经网络结构就偏好性的认为,层次化处理信息有更好效果;卷积神经网络认为信息具有空间局部性(locality),可以用滑动卷积共享权重方式降低参数空间;反馈神经网络则将时序信息考虑进来强调顺序重要性;图网络则是认为中心节点与邻居节点的相似性会更好引导信息流动。可以说深度学习时代,纷繁的网络结构创新就体现了不同的归纳性偏。更强的归纳性偏好其实可以提升样本的利用效率,或者说减少计算代价。比如alphago由于面向围棋这种方形棋盘,用CNN就很合适。但是拿这套框架去打星际争霸,就还是得加上RNN去考虑时序处理逻辑。所以人脑智力的确很神奇,一方面就一个大脑却可以适应不同的任务,貌似model-free,另一方面人类在处理诸多信息时,又有很强的预先偏好性,可以快速决断。这种偏好也是诸多错觉或者误判的来源。
- In particular, generalizing beyond one’s experiences—a hallmark of human intelligence from infancy—remains a formidable challenge for modern AI.
- Just as biology uses nature and nurture cooperatively, we reject the false choice between “hand-engineering” and “end-to-end” learning, and instead advocate for an approach which benefits from their complementary strengths.
- We explore how using relational inductive biases within deep learning architectures can facilitate learning about entities, relations, and rules for composing them.
- We discuss how graph networks can support relational reasoning and combinatorial generalization, laying the foundation for more sophisticated, interpretable, and flexible patterns of reasoning.
- That is, the world is compositional, or at least, we understand it in compositional terms. When learning, we either fit new knowledge into our existing structured representations, or adjust the structure itself to better accommodate (and make use of) the new and the old.
- A key reason why structured approaches were so vital to machine learning in previous eras was, in part, because data and computing resources were expensive, and the improved sample complexity afforded by structured approaches’ strong inductive biases was very valuable.
- In contrast with past approaches in AI, modern deep learning methods often follow an “end-to-end” design philosophy which emphasizes minimal a priori representational and computational assumptions, and seeks to avoid explicit structure and “hand-engineering”.
Introduction前半部分:传统机器学习因为样本数少和计算资源昂贵,往往需要通过特征工程和各种假设来提高样本的表达能力,比如一个多肽序列样本就可以算出成千上万个描述符,或者假设属性对预测结果影响独立;现代深度学习讲究的是端到端的学习,尽量减少先验和假设。另一方面人脑实际上是通过一种复合的方式理解这个世界,不是仅靠先验假设(structured representations),也不是仅靠通过样本来获得所有信息。
- Recently, a class of models has arisen at the intersection of deep learning and structured approaches, which focuses on approaches for reasoning about explicitly structured data, in particular graphs.
- In the remainder of the paper, we examine various deep learning methods through the lens of their relational inductive biases, showing that existing methods often carry relational assumptions which are not always explicit or immediately evident. We then present a general framework for entity- and relation-based reasoning—which we term graph networks—for unifying and extending existing methods which operate on graphs, and describe key design principles for building powerful architectures using graph networks as building blocks.
- Many approaches in machine learning and AI which have a capacity for relational reasoning (Box 1) use a relational inductive bias. While not a precise, formal definition, we use this term to refer generally to inductive biases (Box 2) which impose constraints on relationships and interactions among entities in a learning process.
- Relational reasoning, then, involves manipulating structured representations of entities and relations, using rules for how they can be composed.
- An entity is an element with attributes, such as a physical object with a size and mass
- A relation is a property between entities.
- A rule is a function (like a non-binary logical predicate) that maps entities and relations
to other entities and relations
- An inductive bias allows a learning algorithm to prioritize one solution (or interpretation) over another, independent of the observed data.
- Inductive biases often trade flexibility for improved sample complexity and can be understood in terms of the bias-variance tradeoff.
- however, mismatched inductive biases can also lead to suboptimal performance by introducing constraints that are too strong.
- This composition of layers provides a particular type of relational inductive bias—that of hierarchical processing—in which computations are performed in stages, typically resulting in increasingly long range interactions among information in the input signal. As we explore below, the building blocks themselves also carry various relational inductive biases (Table 1).
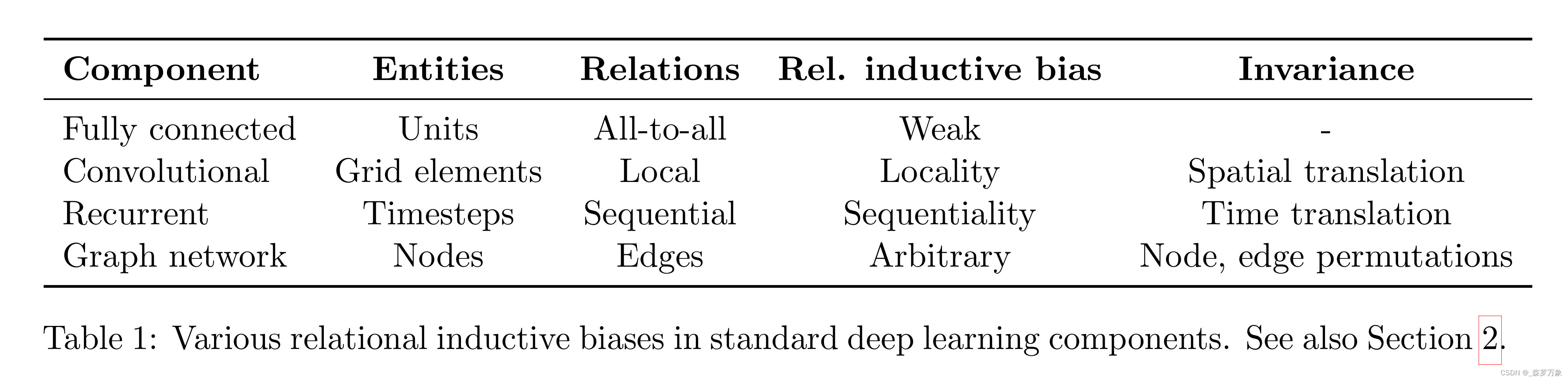
从图中可以看出,全连接层的归纳偏置最弱,即模型容量没有受到限制,而其他几类模型只是全连接层添加归纳偏置之后的特殊情况,可以参见《动手深度学习》6.1
-
Though beyond the scope of this paper, various non-relational inductive biases are used in deep learning as well: for example, activation non-linearities, weight decay, dropout (Srivastava et al., 2014), batch and layer normalization (Ioffe and Szegedy, 2015; Ba et al., 2016), data augmentation, training curricula, and optimization algorithms all impose constraints on the trajectory and outcome of learning.
-
In deep learning, the entities and relations are typically expressed as distributed representations, and the rules as neural network function approximators; however, the precise forms of the entities, relations, and rules vary between architectures. To understand these differences between architectures, we can further ask how each supports relational reasoning by probing:
- The arguments to the rule functions (e.g., which entities and relations are provided as input).
- How the rule function is reused, or shared, across the computational graph (e.g., across different
entities and relations, across different time or processing steps, etc.). - How the architecture defines interactions versus isolation among representations (e.g., by applying rules to draw conclusions about related entities, versus processing them separately).
-
The implicit relational inductive bias in a fully connected layer is thus very weak: all input units can interact to determine any output unit’s value, independently across outputs (Table 1).
-
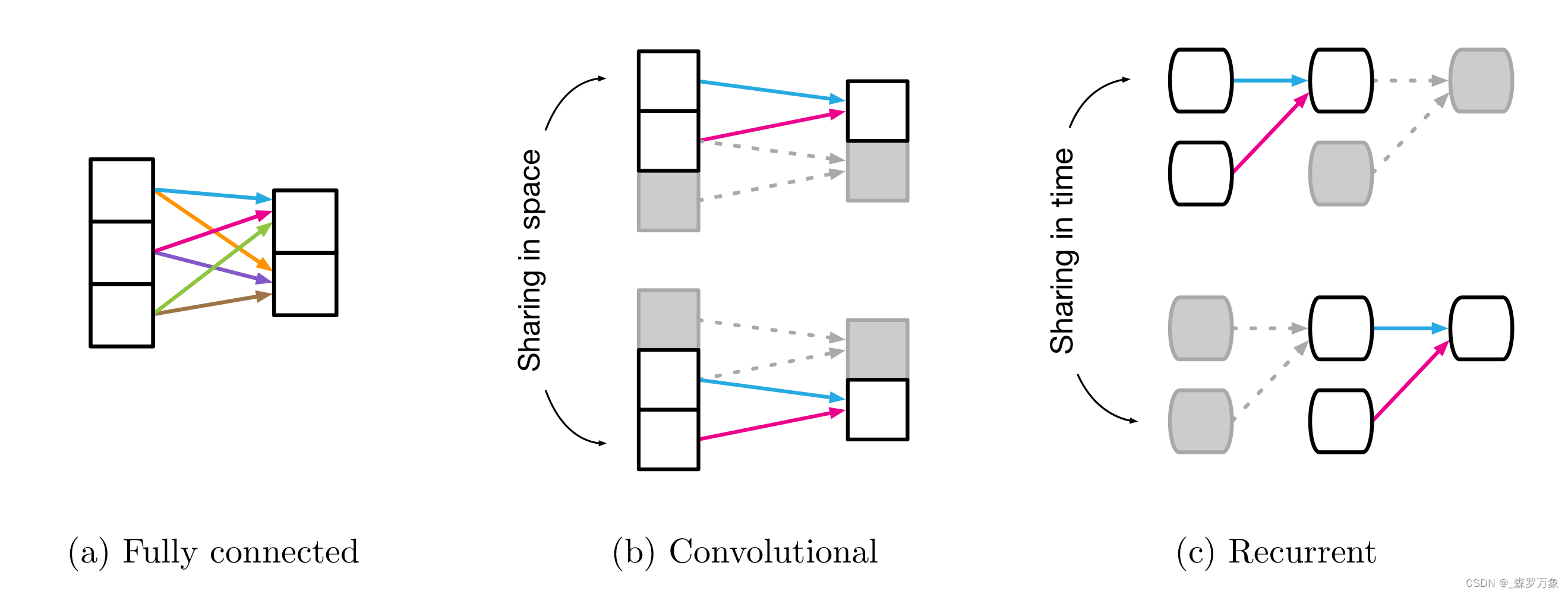
CNN : Translation invariance reflects reuse of the same rule across localities in the input.
-
RNN : The rule is reused over each step (Figure 1c), which reflects the relational inductive bias of temporal invariance (similar to a CNN’s translational invariance in space).
CNN中引入空间平移不变性(以卷积核体现),RNN中引入了时间平移不变性(以隐状态/输入的转移矩阵体现),这是一种归纳偏置,减少了直接使用 MLP 的参数数量
- While the standard deep learning toolkit contains methods with various forms of relational inductive biases, there is no “default” deep learning component which operates on arbitrary relational structure.
- Of course, permutation invariance is not the only important form of underlying structure in many problems.
- Graphs, generally, are a representation which supports arbitrary (pairwise) relational structure, and computations over graphs afford a strong relational inductive bias beyond that which convolutional and recurrent layers can provide.















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











