







yolo算法理解
Background
yolov10是清华大学发布的一个新yolo算法,作者认为NMS是影响yolo实时推理的一个主要问题,针对这个问题提出了dual assignments的方法来训练NMS-free的yolo模型。同时作者从速度和精度入手,提出了几个改进模型的方法。yolov10在推理速度以及参数量上都优于现有的模型,且仍具有不弱于其他模型的精度。接下来主要分析yolov10中的dual asignments和 Efficiency-Accuracy优化策略。
yolov10的论文地址:https://arxiv.org/abs/2405.14458
yolov10的代码地址:https://github.com/THU-MIG/yolov10
Consistent Dual Assignments for NMS-free Training
作者认为one-to-many label assign需要NMS进行后处理,从而影响模型部署后的推理速度,然而one-to-one label assign会带来额外的推理开销并且没有太好的表现。
基于这俩个原因,提出了dual label assignmets的策略,即在yolo中同时采用one-one和one-to-many。模型的结构见下图
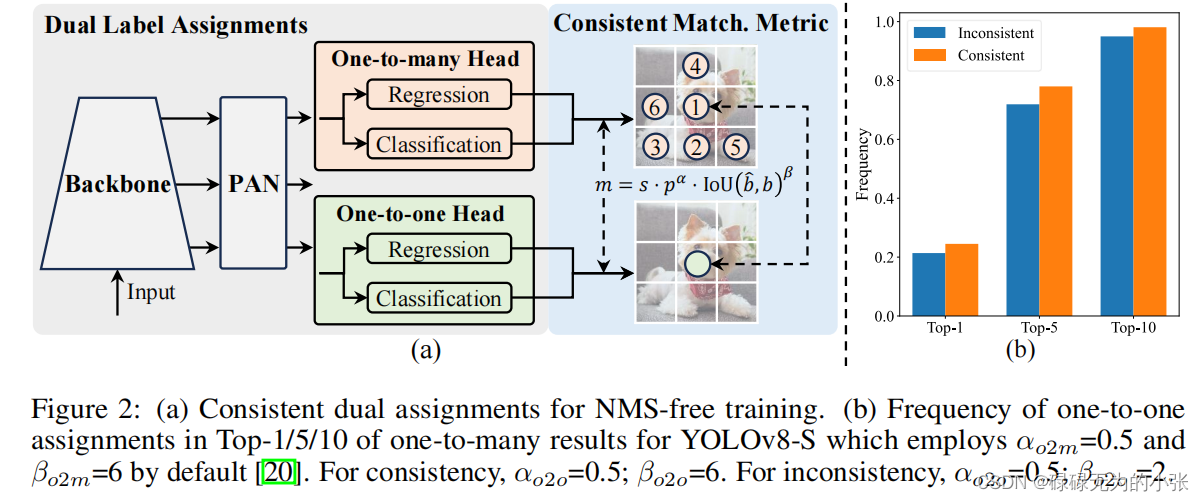
从上图可以看出,相较于普通的yolo头,这里的yolo头有俩个,分别用于one-to-one和one-to-many。同时每个头都采用了解耦头的方式,即回归和分类分开。这里的思想跟v7中的辅助头是挺像的,通过一个aux head实现one-to-many,lead head实现one-to-one。最后在推理阶段丢弃aux head。
引入了俩个头之后,最大的问题就是如何去分配标签。这里作者对俩个头都用了一样的匹配度量。这里匹配度量的仍然是考虑了分类头和回归头,这里匹配损失记为 m m m,具体计算如下 m ( α , β ) = s ⋅ p α ⋅ I O U ( b ^ , b ) β m(\alpha,\beta) = s\cdot p^{\alpha}\cdot IOU(\hat{b},b)^{\beta} m(α,β)=s⋅pα⋅IOU(b^,b)β其中 p p p是指分类分数, b ^ \hat{b} b^为预测框, b b b为真实框, α \alpha α和 β \beta β是超参数。
这样度量就同时考虑了分类任务和回归任务。对于one-to-one的任务记为 m o 2 o = m o 2 o ( α o 2 o , β o 2 o ) m_{o2o} = m_{o2o}(\alpha_{o2o},\beta_{o2o}) mo2o=mo2o(αo2o,βo2o),对于one-to-many的任务记为 m o 2 m = m o 2 m ( α o 2 m , β o 2 m ) m_{o2m}=m_{o2m}(\alpha_{o2m},\beta_{o2m}) mo2m=mo2m(αo2m,βo2m)。
作者认为o2m能够提供更丰富的监督信息,同时希望o2m能够引导o2o。所以作者分析了o2o和o2m的差距,发现它们在回归任务上的表现没什么大的差异,所以认为它们的差距主要体现在分类任务上。然后就是针对分类任务进行改进。
先给定一个目标,然后记俩个头预测的最大IOU为 u ∗ u^* u∗(由于回归任务差不多,所任可以认为俩个头预测的最大IOU相等),然后记俩个头的最大匹配分数为 m o 2 o ∗ m^{*}_{o2o} mo2o∗和 m o 2 m ∗ m^{*}_{o2m} mo2m∗。
同时假设 o 2 m o2m o2m的最佳匹配为 Ω \Omega Ω,而 o 2 o o2o o2o的最佳匹配为第 i i i个,并记为 m o 2 o , i = m o 2 o ∗ m_{o2o,i}=m_{o2o}^* mo2o,i=mo2o∗。然后有以下的等式关系 t o 2 m , j = u ∗ m o 2 m , j m o 2 m ∗ ≤ u ∗ t o 2 o , i = u ∗ m o 2 o , i
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









