







YOLOv7
YOLOv7是2022年发布的,在yolov6发布不久就出了。yolov7是在v5的基础上改进了网络结构,使网络更加高效。其仍然是anchor-based的预测形式,没有做大改。yolov7的主要创新点有三个,分别是E-ELAN网络、Planned re-parameterized convolution和标签分配方式。
yolov7结构图如下
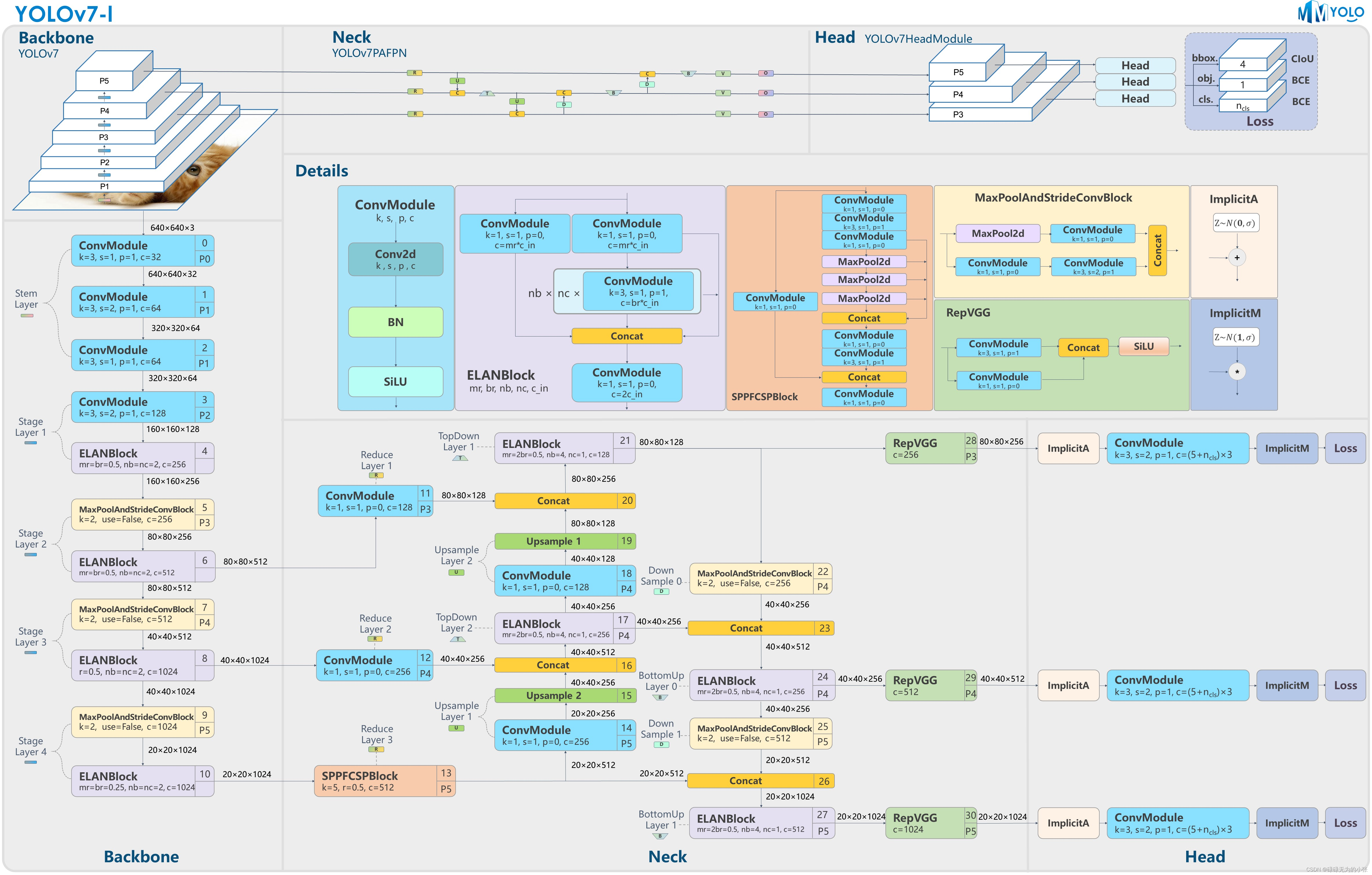
ELAN和E-ELAN
ELAN网络是在CSPnet的基础上改进的一个网络,它的网络结构具备更多的分支以及更少的卷积核,论文作者通过实验证明了这种方式是有效的。
接下来仔细分析ELAN网络,论文中给出的ELAN网络图如下
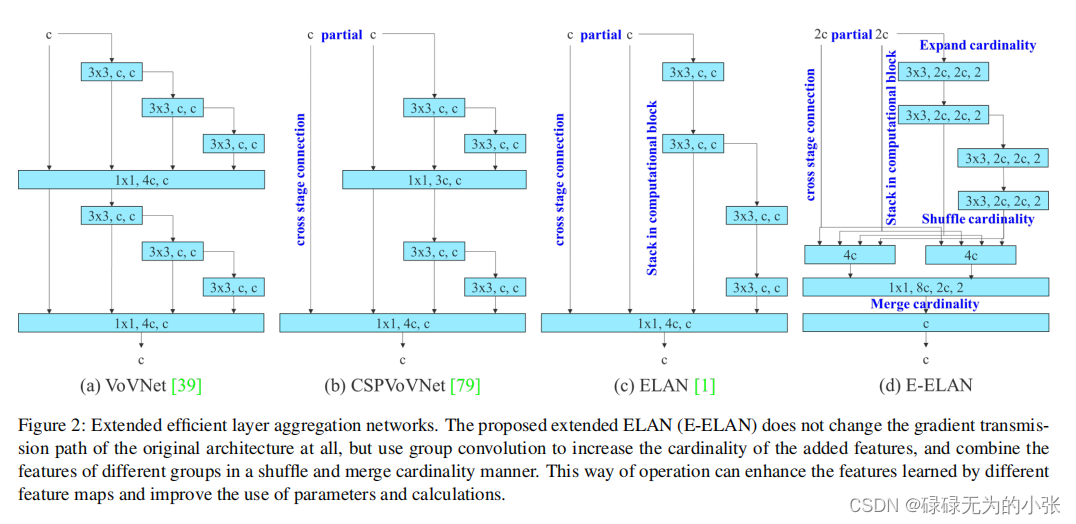
其中图 ( c ) (c) (c)为ELAN网络的具体结构,它与CSP网络一样,采用了梯度截流的方式。但ELAN它消除了网络中的1x1卷积concat的操作,转换成了3x3卷积直接输出,在最后再进行concat的方式,从直观上看来,它保留了残差连接,但卷积数减少了。且论文作者提出这种方式会带来更少更长的梯度路径,更容易收敛。
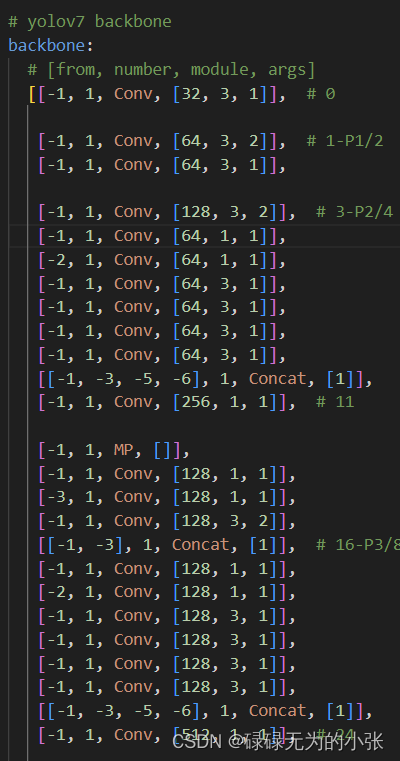
结合在代码中的结构,具体分析一下它的结构,上图是yolov7backbone的部分结构,第3层-第11层就是ELAN网络。可以发现,其是使用了1x1的卷积网路进行partial的操作,然后经过了4层的卷积网络,最后将第4层、第5层、第7层和第9层concat在一起。最后用1x1的卷积变换channel输出。这样的描述可能比较模糊,下面用结构图和代码结构对应来展示整个过程。

作者还提出了E-ELAN,是ELAN的扩展版本。它的结构如图 ( d ) (d) (d)所示。从图上可以发现,这个结构十分复杂,让人一头雾水。从图上可以看出partial的维度是 2 c 2c 2c,像是直接维度翻倍了。但实际它的结构应该如下图所示
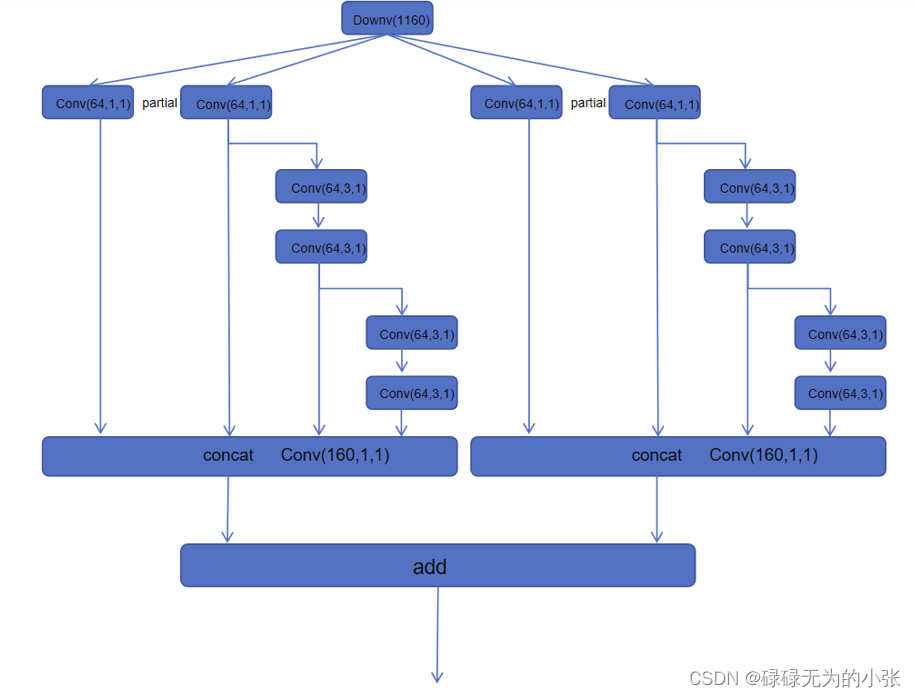
它是将俩个ELAN网络合并了,通过俩个一样的ELAN网络最后用add的方式合并输出。在官方代码中的yolov7e6的参数中实现了这个网络,所以可以结和它的参数具体分析一下。
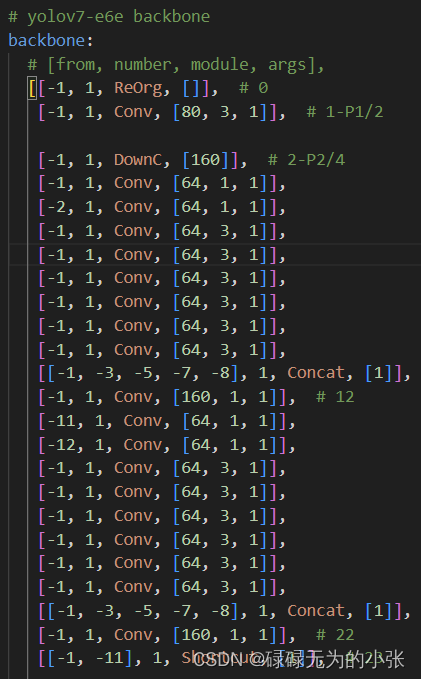
从上图可以发现,第2层至第23层为E-ELAN网络,其中第3层-第11层为第一个ELAN网络,第13层-第22层为第2个ELAN网络,最后用add(shorcut实现的也是add)方式叠加输出。ELAN网咯中,3x3的卷积多了俩个,同时最后concat时变成了5个,这与论文给的图是不一致的,论文图中的E-ELAN只用了4个分支,这里用了5个。具体的对应用下图表示。

结合E-ELAN和ELAN的机构可以看出,论文作者将多分支concat的方式作为一种增精降参的方式。
Planned re-parameterized convolution
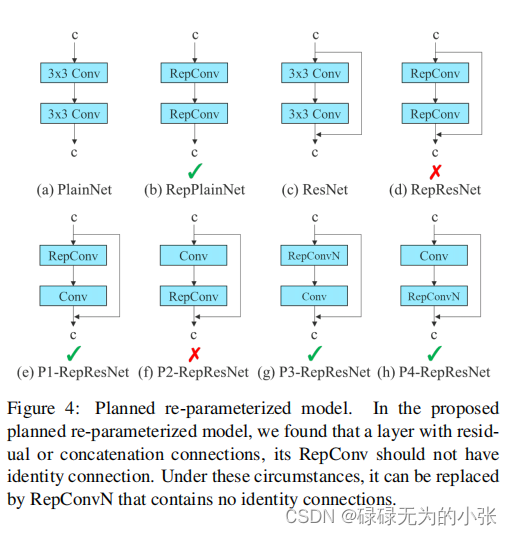
上图是Planned re-parameterized模型,它是re-parameterized的一种改进方式。论文中指出repconv的方式直接应用于网络中时会出现网路下降,并分析给出了原因。从图 ( a ) (a) (a)和图 ( b ) (b) (b),可以看出俩个卷积网络直接更换成repconv是可以的。根据图 ( c ) (c) (c)和图 ( d ) (d) (d),说明发现当网络中使用残差连接时,引用俩个连续的repconv层效果不好。根据图 ( e ) (e) (e)和图 ( f ) (f) (f),可以发现残差连接时,repconv层直接和残差连接相加的效果不好。根据图 ( g ) (g) (g)和图 ( h ) (h) (h),可以发现,将repconv改变成repconvN就可以改进图 e e e和图 f f f的效果。
总的来说,论文作者分析了Repconv的适用情况,认为残差连接不能直接和Repconv相加。但提出了RepConvN来改进这种情况。
标签分配
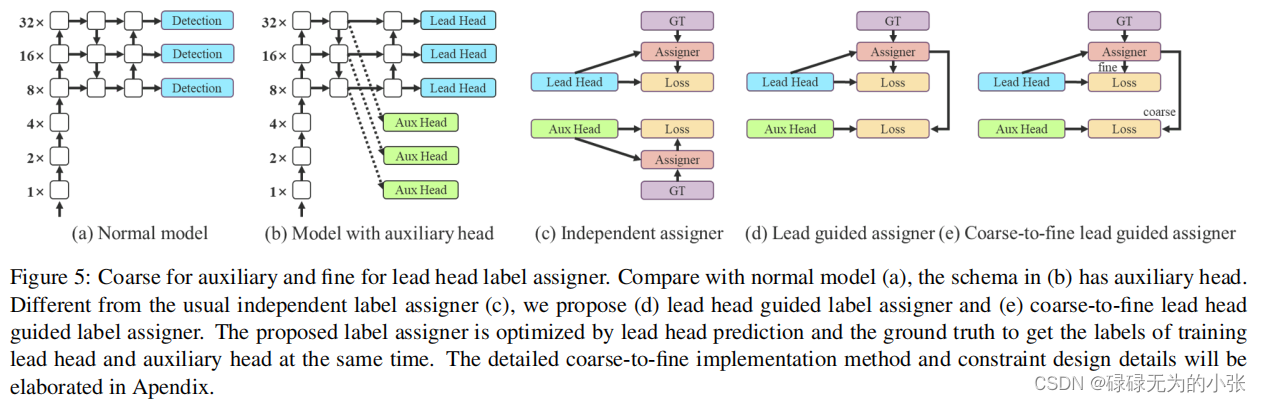
yolov7提出了lead guided assigner的方法。以前的辅助损失头一般用解耦的方式,各自分别分配标签,但是这样aux head的损失和lead head的就难以对齐了。所以这里提出了lead head guided label assigner。即通过lead头来控制lead和aux的标签分配。并在这个基础上提出了aux head学习coarse label,lead head学习fine label的方式,使aux head学习更多标签,具备更好地召回,而lead head学习细标签,更关注于精准度。
在yolov7中的代码中,标签分配采用了simOTA的方式,对aux head分配更多的正样本,而lead head分配较少的正样本。simOTA是yolox中提出的方法,能够使真实标签更好地分配给grid,减少真实标签分配过多给不正确的grid从而导致检测效果降低的情况。而yolox是采用anchor-free的方式,yolov7仍然是anchor-based的模型。
yolov7延续了yolov5的框分配方式,每个真实标签分配给了不多于3的grid中。将分配后的所有真实框与每个预测框计算iou的值。然后筛选前 m = min ( 10 , n u m ( p r e d i c t ) ) m = \min(10,num(predict)) m=min(10,num(predict)) 个iou的值。然后根据前 m m m个iou值计算动态 k k k值,即 D y n a m i c _ k = ⌊ ∑ i m i o u i ⌋ Dynamic\_k = \left \lfloor \sum_i^{m} iou_i\right\rfloor Dynamic_k=⌊i∑
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 984
984

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









